DDIA: 数据分区
复制是在不同节点上保存相同数据的多个副本,如果数据量过大使得单节点无法存储全量数据或者查询压力过高,那么仅仅使用复制是不够的,我们需要将数据拆分为分区(分片)。
分区使得每条记录(数据,行 或者 文档)只属于某个特定的分区。每个分区可以看作一个完整的小型数据库。
数据分区用于提高可扩展性;不同分区可以存放在无共享集群中的不同节点上,使得大数据集分散在更多磁盘上,负载相应地也分散到各个机器。
每个分区可以进行独立查询操作,因此多分区可以提高系统吞吐量;但是对跨分区查询比较困难。
分区与复制
分区通常与复制同时使用,即每个分区都会存在多个副本。
某条记录属于特定的分区,该记录又会被保存在不同的副本中以提高容错性
一个节点上可能存在多个分区;每个分区都有主副本 & 从副本,主副本与从副本被分配在不同的节点上。一个节点可能是某个分区的主副本,也可能是其他分区的从副本。
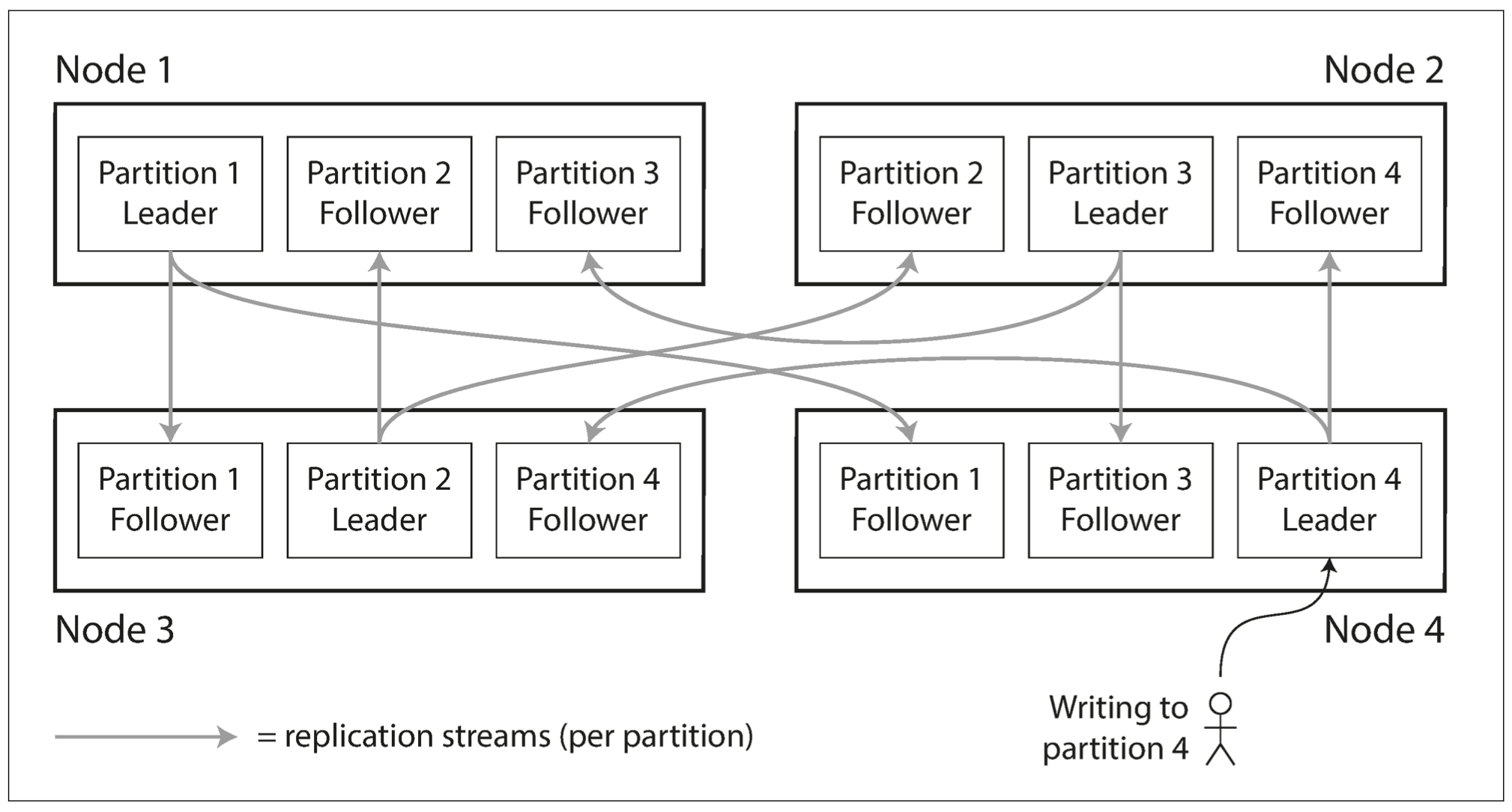
复制 & 分区组合使用:每个节点既是某些分区的主节点又是其他分区的从节点
键-值数据的分区
分区的主要目的是将数据和负载均匀分布在所有节点上。
如果节点平均分担负载,那么 n 个节点理论上能处理 n 倍的数据量和 n 背的读写吞吐量。如果分区不均匀,那么会导致某些分区的负载比其他分区负载高,称之为倾斜。倾斜会导致整体性能下降;系统的瓶颈在负载最高的分区上,该分区就会称为系统热点。
假设所有的数据都是 key-value 类型的模型,常见的分区方式有:
基于关键字区间分区
每个分区分配一段连续的关键字或者关键字区间范围(min ~ max):如果知道关键字区间的上下限,就可以确定哪个分区包含哪些关键字。
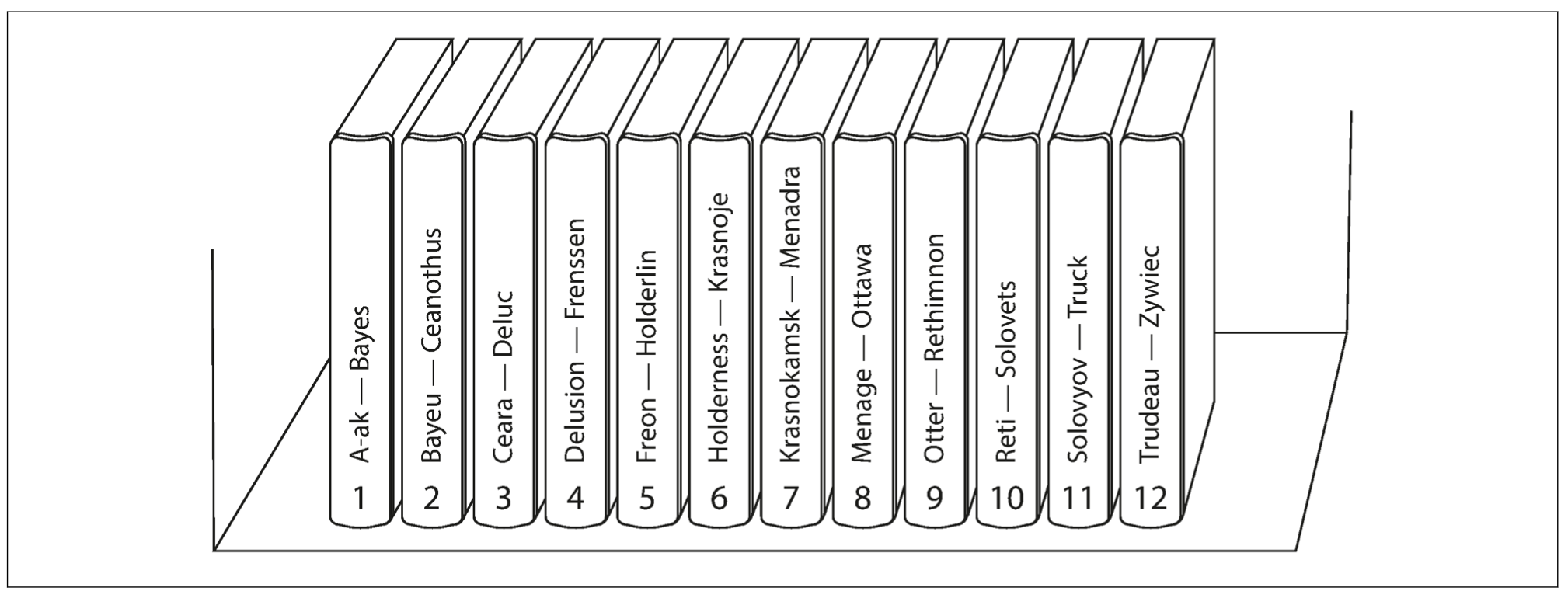
百科全书按照关键字区间进行分区
需要注意的是,*关键字的区间段不一定要均匀分布,因为数据本身可能就不均匀*。为了均匀地分布数据,分区边界应该适配数据本身的分布特征。每个分区内可以按照关键字排序,便于支持区间查询。
分区边界可以手动指定,也可以自动设定(分区再平衡)
基于关键字区间分区的缺点是某些访问模式下会导致热点。比如,关键字是时间戳,每个分区对应一段时间范围,可能大部分操作都集中在当前时间段内。
基于关键字 Hash 分区
对于数据倾斜与热点问题,较多的系统选择基于关键字的哈希值来分区。
可以为每个分区分配一个哈希值范围(而不是直接作用于关键字范围),关键字根据其哈希值的范围划分到不同的分区。
一个好的 Hash 函数可以处理数据倾斜并使其均匀分布

分区的边界可以是均匀间隔,也可以是伪随机选择(有时被称为一致性哈希)。
一致性哈希是一种平均分配负载的方案
但是,关键字哈希值分区会使得区间查询的特性丧失;即使关键字相邻,经过哈希之后可能会分散到不同的分区中。
基于哈希分区的方法可以减轻热点,但是无法做到完全避免,如果大多数请求都是针对同一个关键字,那么都会被路由到同一个分区。
分区与二级索引
之前的分区方案都是假设数据模型为 key-value 类型,因此可以根据 key 直接分区;但是如果涉及到二级索引,分区方案更为复杂点。
二级索引通常不能唯一标识一条记录,而是用来加速特定值的查询。二级索引带来的主要挑战是不能规整地映射到分区中;主要有两种方法对二级索引分区:基于文档的分区 & 基于词条的分区。
二级索引是关系数据库标配,在文档数据库中也比较普遍
基于文档分区的二级索引
假设有一个汽车销售网站,每个列表都有一个唯一的文档 ID,用该 ID 进行数据库分区;存在二级索引颜色 & 制造商,用户搜索汽车时可以根据这两个二级索引条件进行过滤。
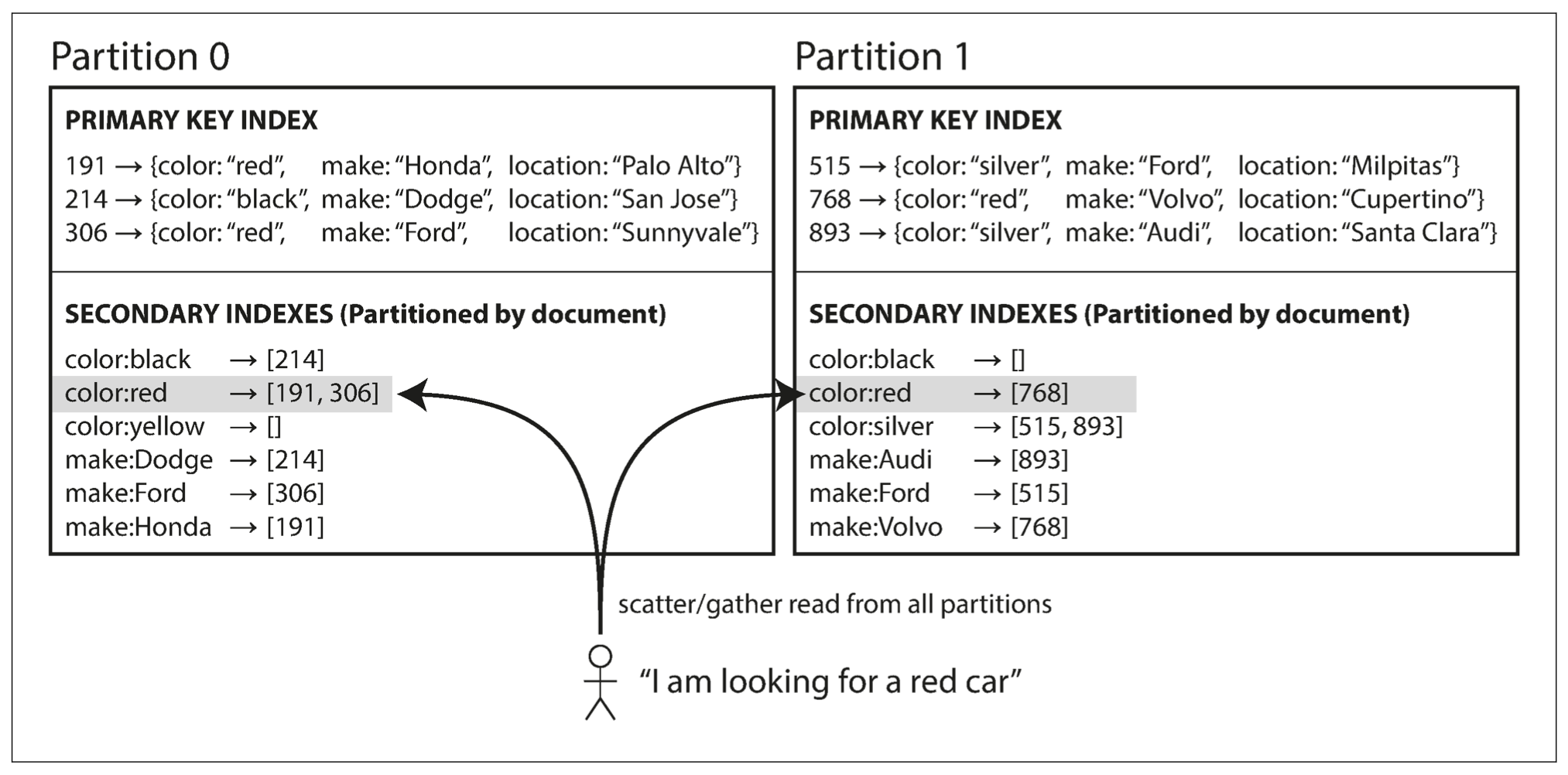
当一辆新的红色汽车添加到数据库中时,数据库分区会自动将其添加到索引条目为 color:red 的文档 ID 列表中。
在这种索引方法中,每个分区完全独立,各自维护自己的二级索引,并且只负责自己分区内的文档而不关心其他分区中的数据。因此文档分区索引也被称为本地索引,而不是全局索引。
但是在查找数据时需要注意:比如想要查找所有红色的汽车,需要将查询发送到所有的分区,然后合并所有的返回结果,该查询会引起读放大。这种查询方法也被称为分散/聚集(容易引起读延迟显著放大)。
基于词条的二级索引分区
可以对所有数据构建全局索引,而不是每个分区维护自己的本地索引;而且为了避免瓶颈,不能将全局索引存储在一个节点上。所以全局索引也必须进行分区,并且可以与关键字采用不同的分区策略。
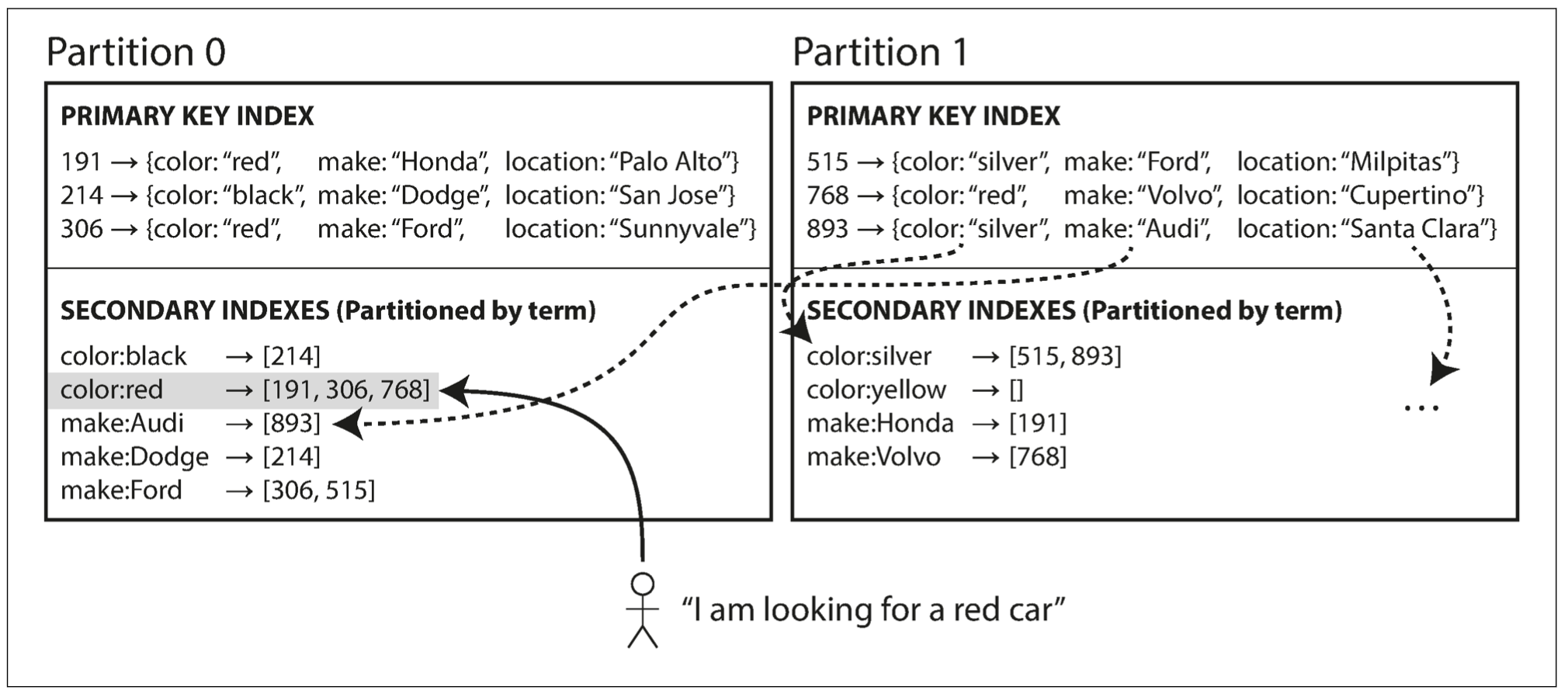
以上图为例,所有颜色为红色的汽车被收录到索引 color:red 中,而索引本身也是分区的(a ~ r 置于分区 0 中,s ~ z 置于分区 1 中;类似的汽车制造商的索引也被分区)。
这种索引方案称为词条分区,它以带查找的关键字本身作为索引。相比于文档分区的优点是:读取效率更高,不需要对所有分区进行查询;只需要向包含指定词条的分区发出请求即可。缺点是:写入速度较慢且复杂,因为当一条记录更新时,可能会涉及到多个二级索引,而二级索引的分区可能在不同的节点上,从而导致写放大。
分区再平衡
随着时间的推移,数据库可能会发生变化:
- 查询压力增大:需要更多的 cpu 来处理负载
- 数据规模增加:需要更多的磁盘和内存来存储数据
- 节点可能出现故障:需要其他机器来接管失效的节点
上述变化要求数据和请求从一个节点转移到另一个节点,这种迁移负载的过程称为再平衡(动态平衡)。无论采用哪种分区方案,分区再平衡通常需要满足:
- 平衡之后,负载,数据存储,读写请求等应该在集群范围内更均匀地分布
- 再平衡执行过程中,数据库可以继续正常提供读写服务
- 避免不必要的迁移负载,以加快动态再平衡
动态再平衡的策略
为什么不用取模?
在哈希分区中,将哈希值划分为不同的区间范围,然后将每个区间分配给一个分区。如区间[0, b0) 对应分区 0,区间[b0, b1) 对应分区 1 等。
有时候会用对分区数取模的方式确定关键字所属分区;如果有 10 个节点(0 ~ 9),那么 hash(key) % 10 会返回一个介于 0 和 9 之间的数字,从而确定 key 的目标分区。
然而,对节点数取模的问题是,如果节点数 N 发生了变化,会导致很多关键字需要从现有节点迁移到另一个节点;这种频繁迁移的操作大大增加了再平衡的成本。
固定数量的分区
为了减少数据迁移,可以采用固定数量分区的方式:首先,创建远超实际节点数的分区数,然后为每个节点分配多个分区。例如,对于 10 个节点的集群,可以创建 10000 个分区,这样每个节点大概承担 100 个分区。
Redis 集群采用该中方式,其中每个分区被称为 slot;固定数量分区的方式与一致性哈希是不同的,尽管都能减少迁移数据量
如果集群中新增了一个节点,该新节点可以从每个现有的节点上匀走几个分区,直到分区再次达到全局平衡;如果从集群中删除节点,则采取相反的均衡措施。
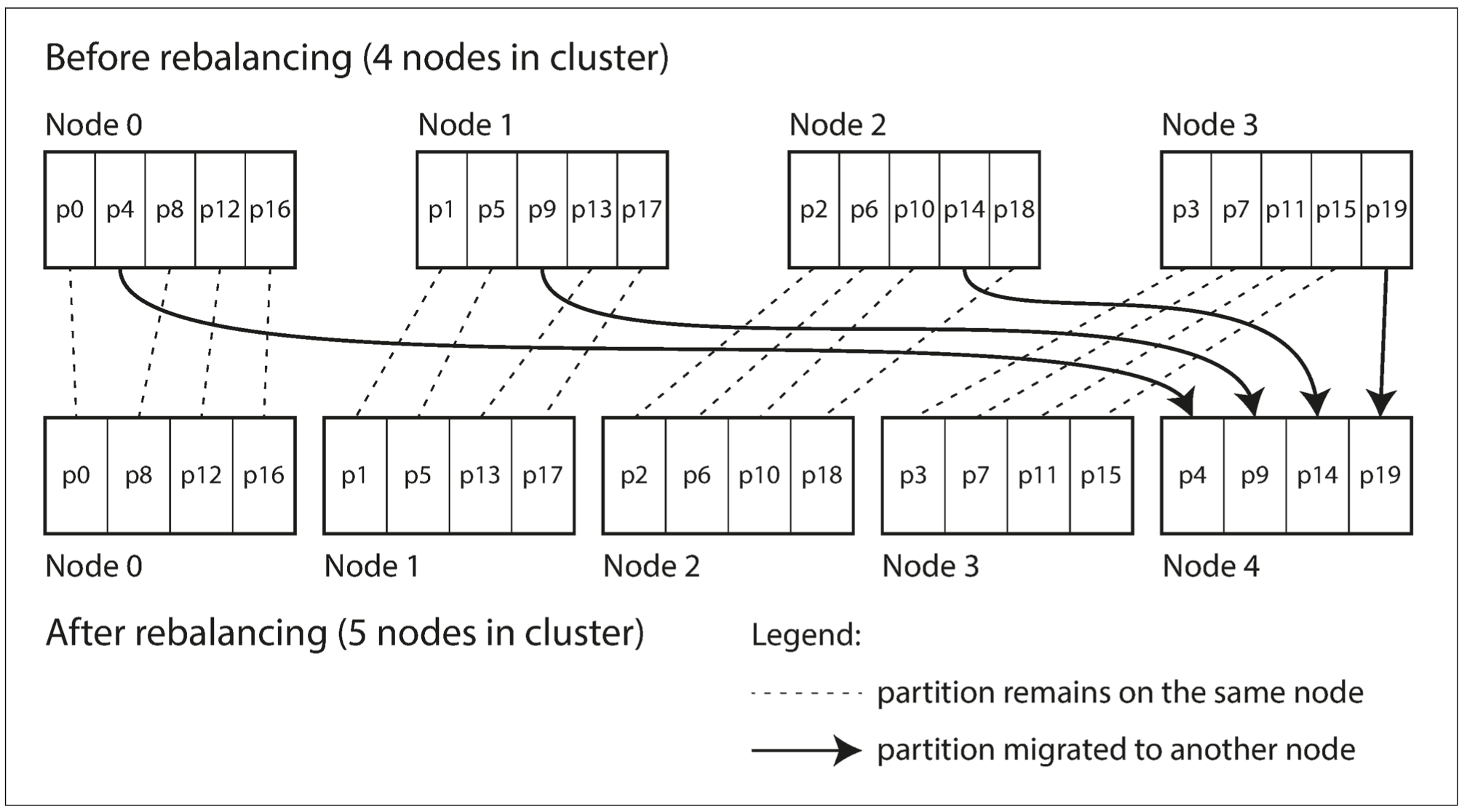
迁移过程会以分区为粒度(分区在节点间迁移),但是分区的总数量不变,也不会改变关键字到分区的映射关系;唯一需要调整的是分区与节点的对应关系。
在迁移期间,旧的分区仍然可以接收读写请求
使用该策略时,分区数目在集群初始化的时候就确定了,并且之后都不会改变。
动态分区
对于采用关键字区间分区的数据库,如果边界设置有问题,可能会出现所有数据都集中在一个分区中,而其他分区基本为空;设置固定边界 或者 固定数量的分区可能会带来不便。
因此有些数据库支持动态创建分区:当分区中的数据增长到一个阈值后,就拆分为两个分区,每个承担一半的数据量;相反,如果大量数据被删除,并且分区数据缩小到一个阈值以下,则将其与相邻分区合并。
HBase 采用了动态创建分区策略
与固定数量的分区策略一样,每个分区总是分配给一个节点,而每个节点可以承担多个分区。
动态分区的一个显著优点是,分区数量可以自适应数据总量。如果只有少量数据,则只需要少量分区,减小系统开销;如果有大量数据,每个分区可以被设定为一个可分配的最大阈值。
按节点比例分区
不管是固定分区数还是动态分区,两种方式的分区数量都与节点数无关;还有一种策略,使分区数与节点数目成正比关系,即每个节点拥有固定数量的分区。
当节点数目不变时,每个分区的大小与数据集大小保持正比关系;当节点数增加时,分区则会变小。较大的数据量需要较多的节点存储,因此该方法也使得每个分区的大小保持稳定。
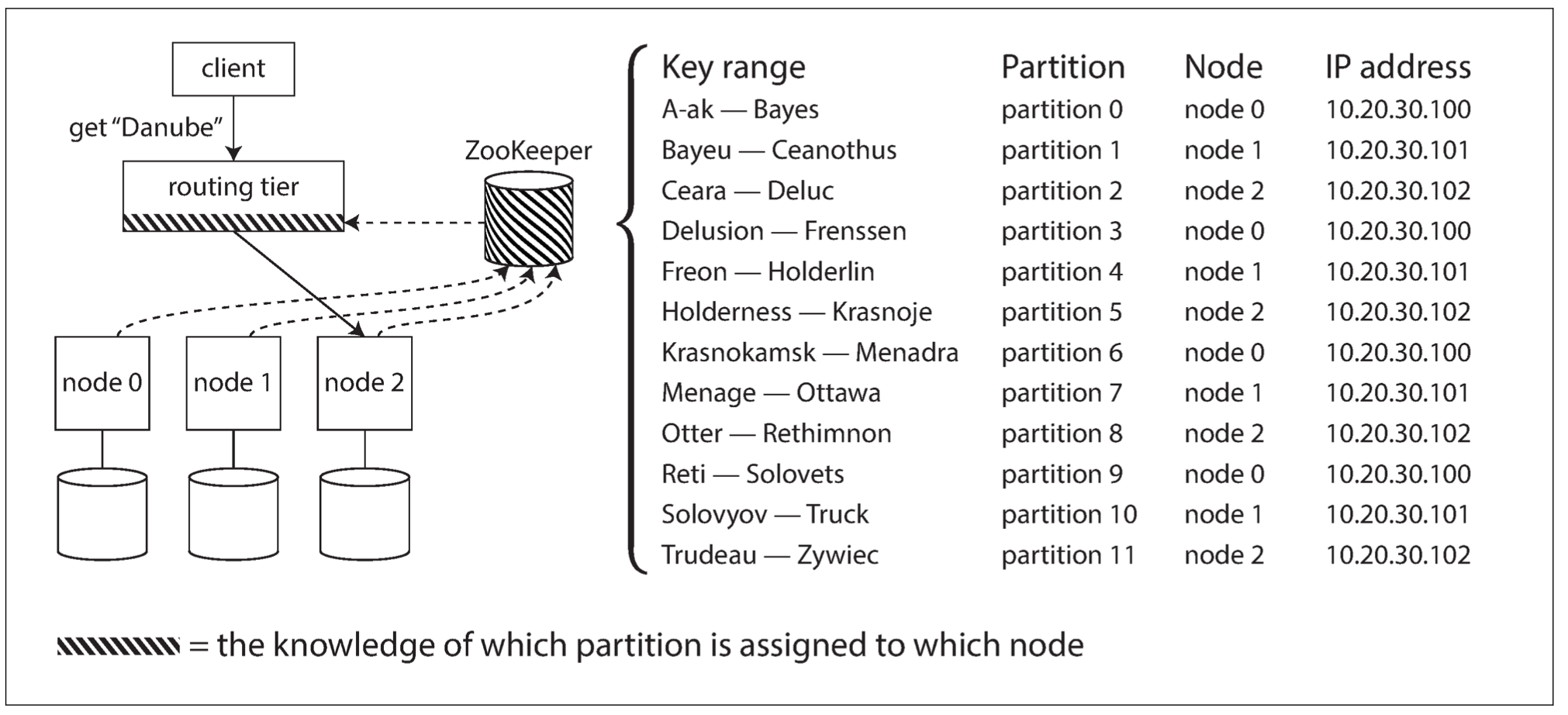
请求路由
将数据分散到多个节点上后,客户端如何知道应该访问哪个节点呢?
这类问题可以统一归为服务发现;并且有几种不同的处理策略:
-
允许客户端连接任意的节点。如果当前节点恰好拥有所访问的分区,则直接处理该请求;否则,将请求转发到下一个合适的节点,接收响应,并将结果返回给客户端。
-
所有的客户端请求都发送到一个路由层,由路由层负责将请求转发到对应的分区节点上。路由层本身不处理任何请求,仅仅充当一个分区感知的负载均衡器。
-
客户端感知分区与节点的分配关系。此时客户端可以直接连接到目标节点,而不需要任何中介。
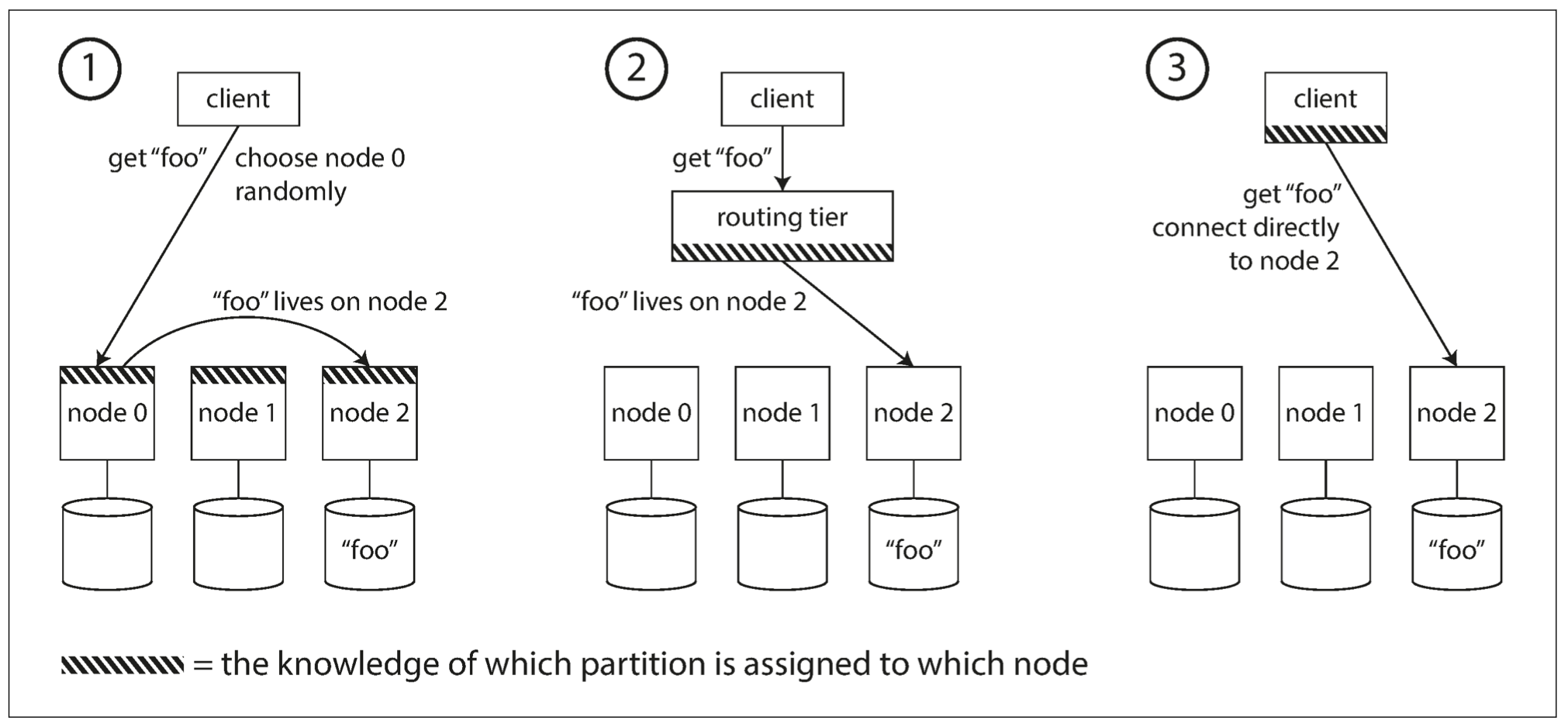
不管是哪一种方法,核心问题是:做出路由决策的组件如何知道分区与节点的对应关系以及变化情况?
这个问题可以归为共识问题:即需要对节点与分区的映射关系达成共识;有些系统直接使用 ZK 这类的协调服务跟踪集群范围内的元数据,一旦分区发生了改变,ZK 就会主动通知路由层,这样使得路由信息保持最新状态。