Distributed Systems
1-Introduction
运行在同一个进程中的多个线程共享同一个地址空间,因此单台计算机上的并发也被称为“共享内存并发”(shared-memory concurrency)。在这种模式下,很容易将数据从一个线程传递到另一个线程:比如指针(pointer),变量(variable)。
在分布式系统中,上述场景就有所不同了。分布式系统中虽然仍存在并发(不同的计算机可以并发执行同一个应用程序),但这些计算机通常不会共享内存(每个计算机都有自己的地址空间,访问自己的内存),此时节点之间只能通过网络进行通信(network)。
在一些超级计算机和科研系统中存在有限形式的共享内存模型,比如 RDMA(remote directly memory access)技术可以使得不同计算机通过网络互相访问内存;数据库(database)在某种程度上也可以被看作是共享内存模型,只不过与常见的字节寻址模型不同。总体来说,大部分分布式系统都是基于消息传递(message-passing)。
分布式系统中的每个节点被称为 Node。Node 含义比较广泛,可以是任何通信计算设备:如桌面计算机,数据中心的服务器,移动设备,网联车,传感器等。
关于分布式系统,Lamport 给出的定义是:
- a system in which the failure of a computer you didn’t even know existed can render your own computer unusable.
- multiple computers communicating via a network
- trying to achieve some task together
- Consists of “nodes” (computer, phone, car, robot, . . . )
1-1 About distributed systems
为什么要使用分布式系统?有以下原因:
- 一些应用本质上就是分布式的(intrinsically distributed):比如手机之间发送短信,该过程不可避免地要求不同手机间通过网络交互
- 提高可靠性(more reliably):如果系统中只有一个节点,该节点可能会故障,偶尔需要重启,那么系统就继续提供服务。但是如果系统中存在多个节点,当某个节点重启时,其他节点能够继续提供服务。所以,分布式系统要比单点系统更可靠。
- 提升系统性能(performance):假设一个服务被世界各地的用户访问,如果该服务是单点系统,那么总有一些地区的用户会觉得服务响应很慢,体验很差。如果该服务是分布式系统,可以将系统节点分布在世界各地,通过将用户路由到最近的节点以提高访问速度。
- 提升系统处理能力(solve bigger problems):随着数据规模增大,处理任务增多,单节点可能无法承载,或者处理速度很慢。通过将任务分散到不同的节点,以提高系统整体处理能力。
然而,分布式系统也存在不足:
- 网络异常(network failure):网络异常时,节点间将无法正常通信
- 节点自身异常(node failure):节点可能会崩溃(crash),运行过慢,或者由于软件硬件方面的异常导致不符合预期。如果我们想要实现故障转移,我们首先需要能够检测(detect)到故障确实发生了;而准确检测故障并不是一件容易的事
- 网络故障及节点异常经常会发生,系统需要能够处理这些异常
在单点系统中,如果出现硬件异常,通常我们不会期望服务仍能正常运行,因此不会对这些异常在软件层面做额外的处理。但是在分布式系统中,我们需要容忍部分节点异常:一些节点不可用时,其他节点能够继续提供服务。
我们把系统组件故障称为 fault,分布式系统需要能够容忍部分组件故障( fault tolerance):尽管存在故障,整个系统仍然能够正常运行。
不过,故障处理通常比较难
1-2 Distributed systems and computer networking
学习分布式系统,通常需要对硬件进行抽象。
我们假设节点间通过某种方式通信,而不关心消息如何被编码,通过何种方式发送等物理层表现方式。
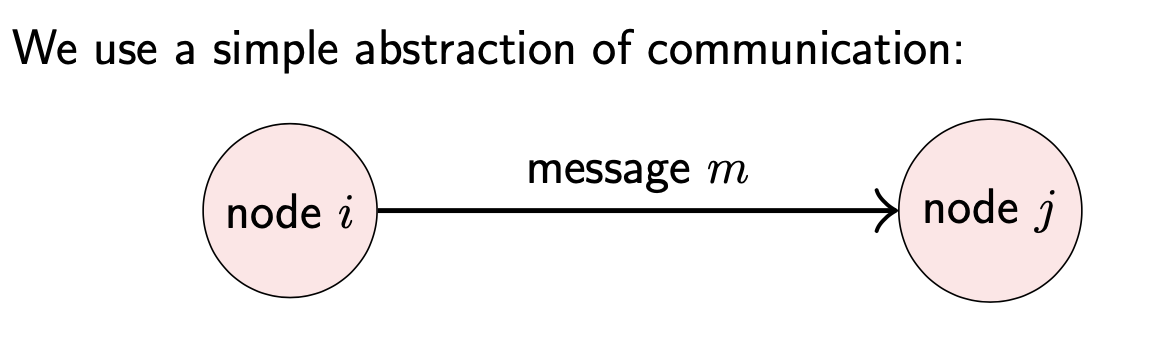
从分布式系统的角度看,我们只需要关注通信延迟(latency)与带宽(boundwith)即可。
- 延迟:消息发送到接收的间隔
- 带宽:单位时间内能够被传输的数据量
分布式系统建立在基础设施之上,更专注于如何进行节点之间的协调,以共同完成任务。分布式系统算法主要关于节点发送什么消息,及节点如何处理收到的消息。
浏览器访问网页是一个我们经常使用的分布式系统例子:
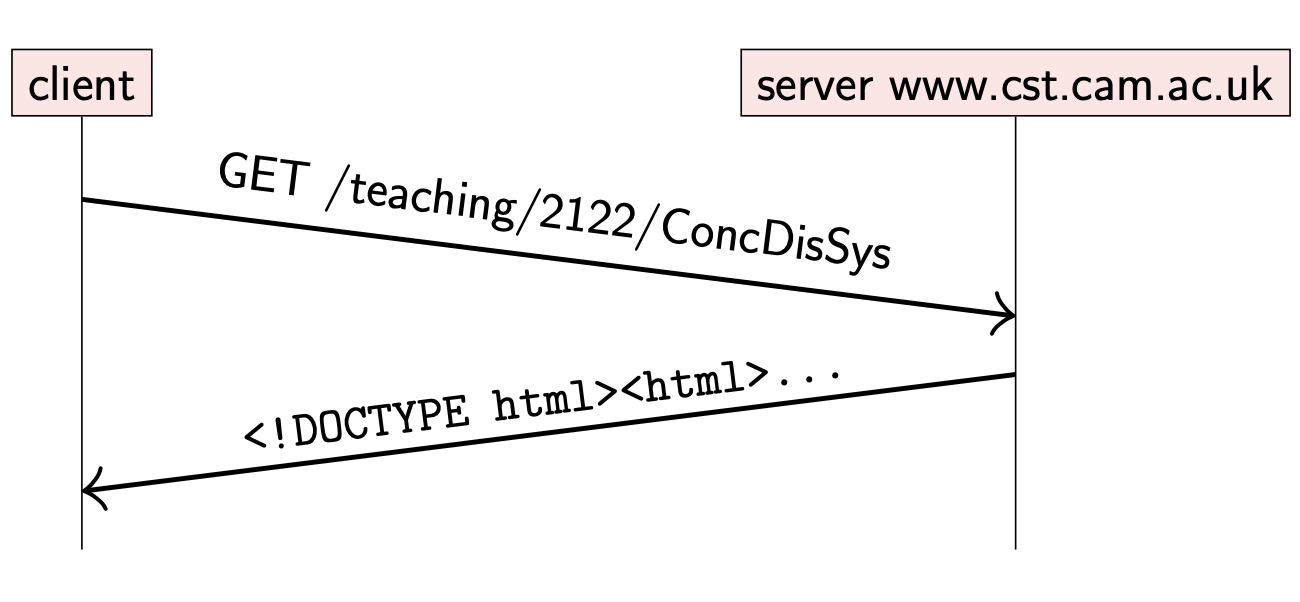
该例子中的节点有两种:
- server:网络站点提供服务
- client: 浏览器用于展示从站点加载的内容
加载网页时,浏览器发送 HTTP request message 到合适的 server 节点;收到请求后,server 返回携带网页内容的 response message(可能是 HTML 文档,图片,视频等)。
HTTP 协议运行在 TCP 协议之上:当 HTTP 报文较大时,TCP 将 HTTP request 内容切分为适当大小的报文,对于接收到的 response 报文段会重新拼接。HTTP 允许多个 request & response 复用同一个 TCP 链接。
网络通信协议有很多细节,然而当我们从分布式系统的角度观察时,具体细节并不重要:我们只需要把 request & response 分别看作一条消息,忽略底层网络实现,使得事情变得更简单(独立于底层网络)。
1-3 Example: Remote Procedure Calls (RPC)
使用信用卡进行网络购物是另一个分布式系统的例子。
- 当我们进行购物付款时,就会通过网络给专门处理信用卡支付的服务发送请求
- 付款服务反过来会与发行信用卡的银行进行通信,以确保该信用卡能够完成支付
在线购物的支付服务实现的代码可能如下:
// Online shop handling customer's card details
Card card = new Card();
card.setCardNumber("1234 5678 8765 4321");
card.setExpiryDate("10/2024");
card.setCVC("123");
Result result = paymentsService.processPayment(card,
3.99, Currency.GBP);
if (result.isSuccess()) {
fulfilOrder();
}
processPayment 方法调用看起来与本地调用的其他方法类似,不过实际上是向 PaymentService 发送了一个网络请求并等待响应。processPayment 方法需要与发行信用卡的银行进行交互,实现逻辑并不在本地,而是在其他节点。
这种交互方式(一个节点的代码看起来是调用另一个节点的方法)被称为 Remote Procedure Call(RPC)。在 Java 中,也被称为 Remote Method Invocation(RMI)。实现 RPC 的软件被称为 RPC Framework,或者 Middleware。
并不是所有的中间件都基于 RPC 通信,还存在其他通信模型
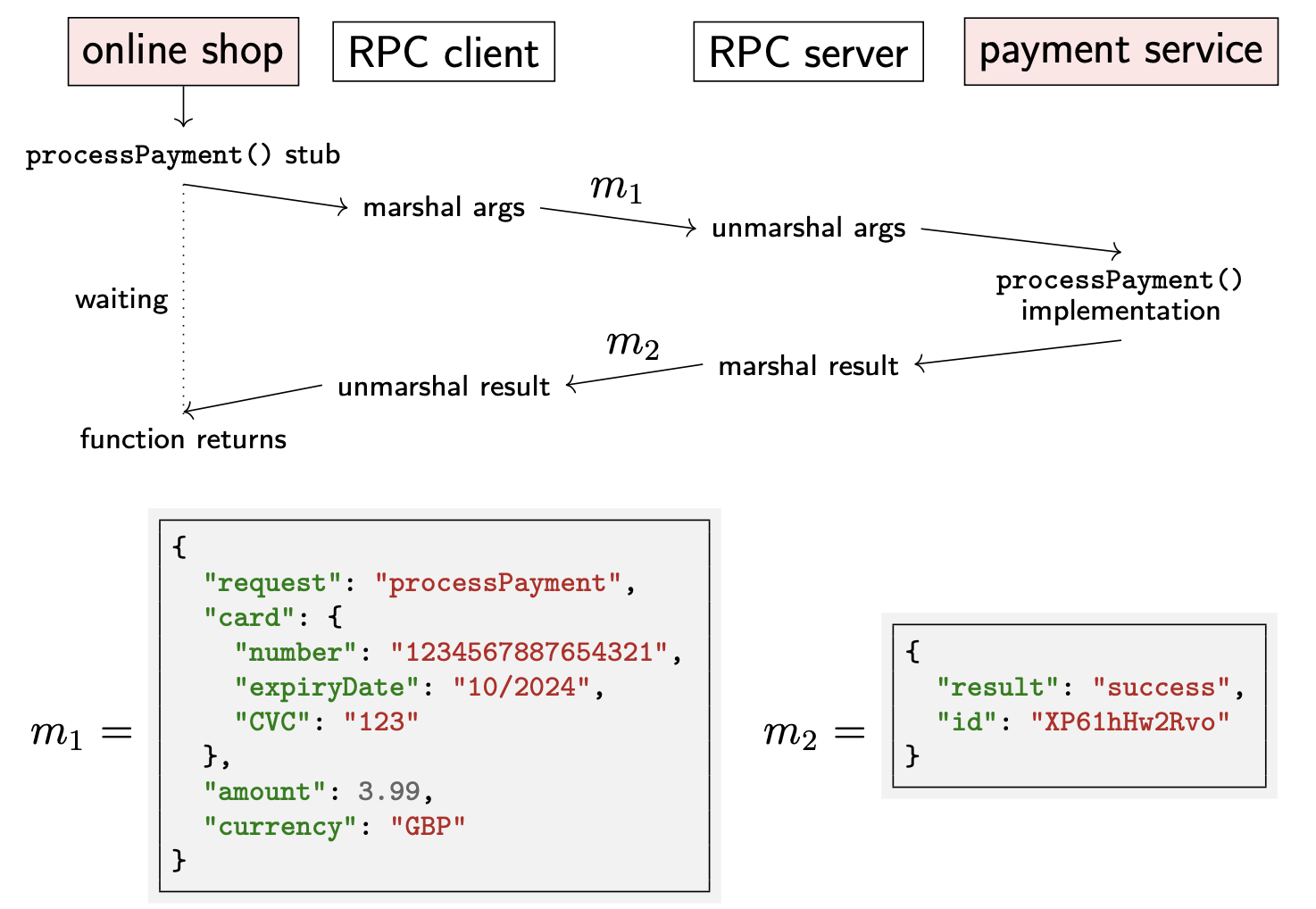
当一个服务想要调用运行在其他节点上的方法时,RPC 框架会在 Client 本地创建 stub 来代替目标方法。该 stub 的方法签名与真正的方法签名相同,但是并不真正执行方法,而是将方法参数编码成特定的消息,并将该消息发送到远程节点,请求调用对应方法。
方法参数编码的过程被称为 marshall;存在多种编码格式,比如 JSON
从 RPC Client 发送消息到 RPC Server 可能会使用不同的网络协议(如果使用 HTTP 协议,则被称为 Web Service)。在 Server 端,RPC 框架会解码收到的消息,并通过解析出的方法参数调用目标方法。当调用方法返回时,返回结果同样会被编码成消息发送给 Client。Client 收到后会解码并通过 stub 返回给调用方。因此,对 stub 的调用方来说,方法看起来是在本地执行并返回。
对应在线支付的执行流程如下:
不过,由于网络或者节点可能会出现故障,RPC 实现时有许多问题需要考虑。
- 方法调用期间,服务崩溃
- 消息传递过程中丢失了
- 消息延迟过大
- 调用出现问题时,能否进行安全重试
当 RPC Client 发送请求后却没有收到响应,Client 并不能确定 Server 是否收到消息。此时应该如何处理?
- Client 可以进行重试,但是可能会导致请求被执行多次(如多次支付);并且,我们也无法保证重试的消息能够成功被成功接收
- Client 也不能长时间等待响应。因此,在实践中,Client 通常在超时之后放弃此次请求
在过去几十年,RPC 发展了很多变体,包括面向对象的中间件(如 CORBA)。如今最常见的 RPC 形式是通过 HTTP 发送 JSON 格式数据。这种基于 HTTP 的 API 设计原则被称为表示状态传输(Representational state transfer)或者 REST,遵守该设计原则的 API 被认为 RESTful。具体协议包括:
- 资源(resources)通过 URL 表示
- 使用标准方法类型的 HTTP 请求来更新资源状态(state),如 POST, PUT
REST 的兴起得益于运行在浏览器上的 JavaScript 代码可以很容易发送该请求。不过,虽然 RESTful API 或者其他以 HTTP 为基础的 RPC 是面向 Web 的,但是也可以用于其他类型的 Client 或者 Server-to-Server 的交互。
Server-to-Server 交互场景在大型企业服务上比较常见:企业服务由于过大且复杂,以至于单台机器无法运行,因此常被拆分为多个服务。每个服务被不同的团队开发 & 管理,不同的服务可能使用不同的开发语言;RPC 框架实现了不同服务之间的交互。
当相互通信的服务使用不同的开发语言时,RPC 框架需要能够转化数据类型,使得被调用方能够理解调用方的请求参数;对于返回值也是同样的。
常见的解决方案是使用 Interface Definition Language(IDL)提供与编程语言无关的 RPC 方法签名。通过 IDL 可以自动生成 marshall & unmarshall 代码,同时可以生成与语言无关的 Server stubs & Client stubs。下面是 gRPC 的 IDL 示例:
message PaymentRequest {
message Card {
required string cardNumber = 1;
optional int32 expiryMonth = 2;
optional int32 expiryYear = 3;
}
required Card card = 1;
required int64 amount = 2;
}
message PaymentStatus {
required bool success = 1;
optional string errorMessage = 2;
}
// service
service PaymentService {
rpc ProcessPayment(PaymentRequest) returns (PaymentStatus) {}
}
2-Models of distributed systems
系统模型是对系统中 nodes & network 行为的假设及属性的抽象。为了阐述通用的系统模型,先引用两个经典的模型:
- The Two Generals Problem
- The Byzantine Generals Problem
2-1 The two generals problem
问题描述:假设有两个将军,每人领导一个军队,并且这两个将军都想占领同一座城市。城市的防御很坚固,如果每次只有一个军队进攻,那么会进攻失败;如果两个军队同时进攻,则能够成功占领城市。因此,这两个将军需要协调他们的进攻计划。
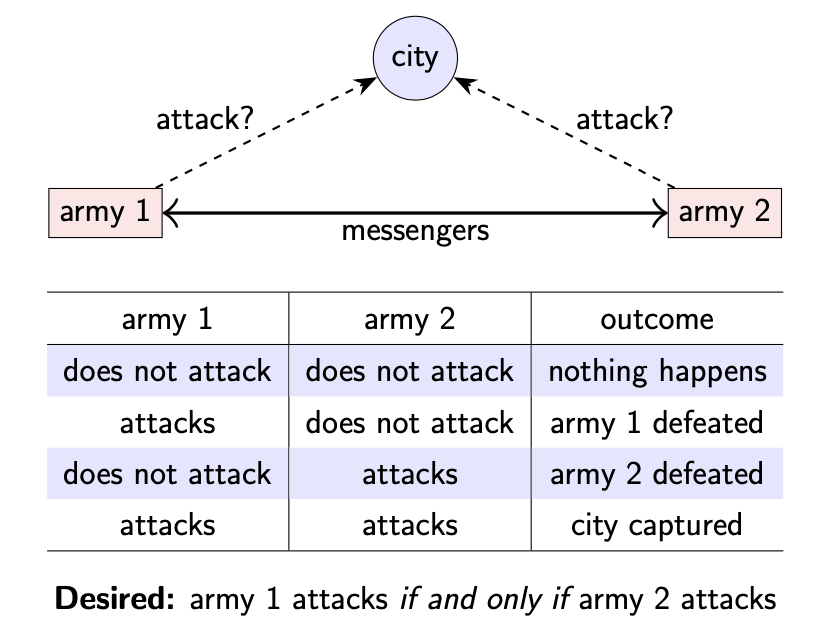
目标:只有在军队 2 进攻的情况下,军队 1 才会发起进攻
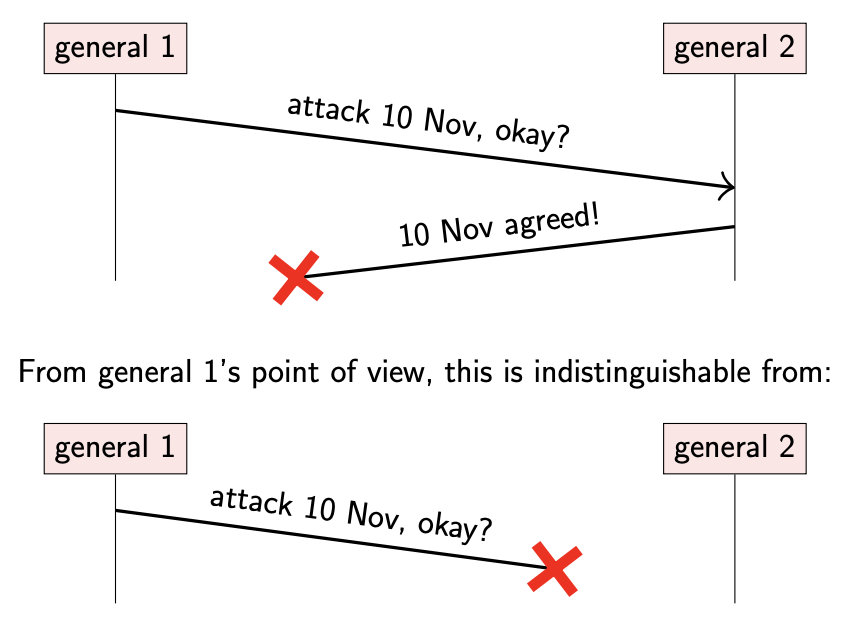
不过,由于这两个军队之间存在一定的距离,彼此间通信只能依靠信使。信使需要通过由城市控制的区域,并且有时候会被捕获,那么消息就无法成功送达。对于发送方来说,除非发送方收到接收方的明确回复,否则也不确定之前发送的消息是否成功被接收。
如果一方没有收到消息,可能是对方确实没有发送消息,也可能是对方发送的所有消息都被截获了。
如何使这两个将军就进攻计划达成一致?对每个将军来说,有两种选择:
-
承诺在任何情况下都发起进攻,即使没有收到对方的明确回复
这种情况下,发起进攻的将军可能会冒险独自进攻
-
直到收到对方明确回复才会发起进攻,否则就一直等待
这种情况相当于将问题抛给了对方:接收方需要决定是否等待回复消息的确认,还是回复之后就发起进攻(也可能会独自进攻)
无法达成共识:只能通过消息传递来获取信息
两将军的问题在于,不管双方交换了多少次消息,也无法确定对方一定能同时进攻。对于分布式系统来说,一个节点无法准确判断另一个节点的状态;不过通过消息传递的方式,可以得到一些信息。
上面介绍的在线商店支付流程可以看作是两将军问题的例子:在线商店服务与信用卡支付服务之间通过 RPC 进行消息传递,并且消息可能会丢失;尽管如此,商店只有在商品被支付成功的情况下才会发货,支付服务只有在商品被发货才会进行扣款。
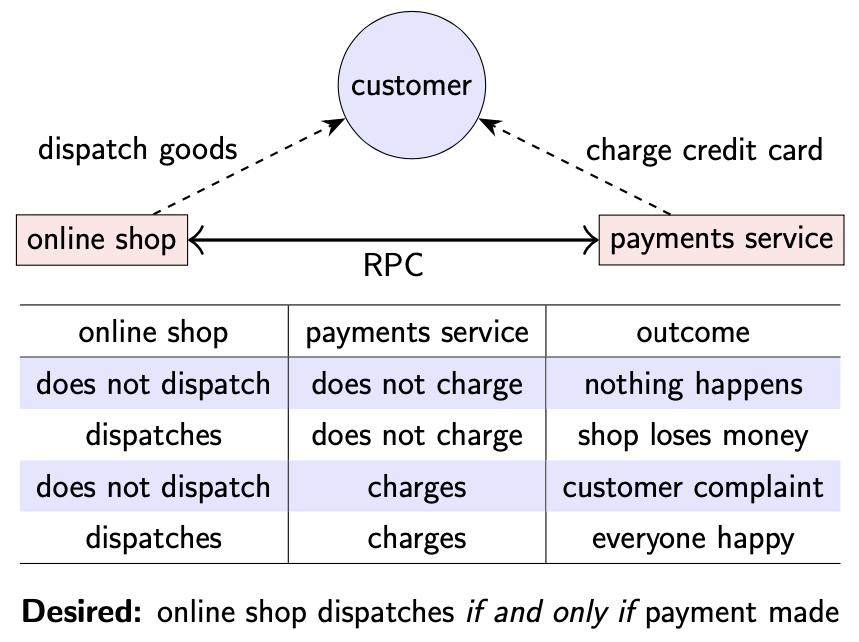
目标:只有商品被支付成功的情况下,在线商店才会发送货物
不过,实际上该流程与两将军问题有点不同:
- 支付服务在任何情况下都可以先进行扣款操作,如果在线商店始终无法发送货物,可以再进行退款操作。由于支付操作可以撤回,使得在两将军中的问题可以解决。
- 即使由于网络等问题导致在线商店服务暂时无法确定支付状态,可以在连接恢复之后再主动查询确定交易状态。发送方可以稍后再次确认之前的消息送达情况。
2-2 The Byzantine generals problem
问题描述:拜占庭将军问题的设定与两将军问题类似。假设多个军队(可以是 3 个以上)需要占领一座城市,不同军队之间仍然通过信使进行通信,只不过此时消息总是能够被成功送达。
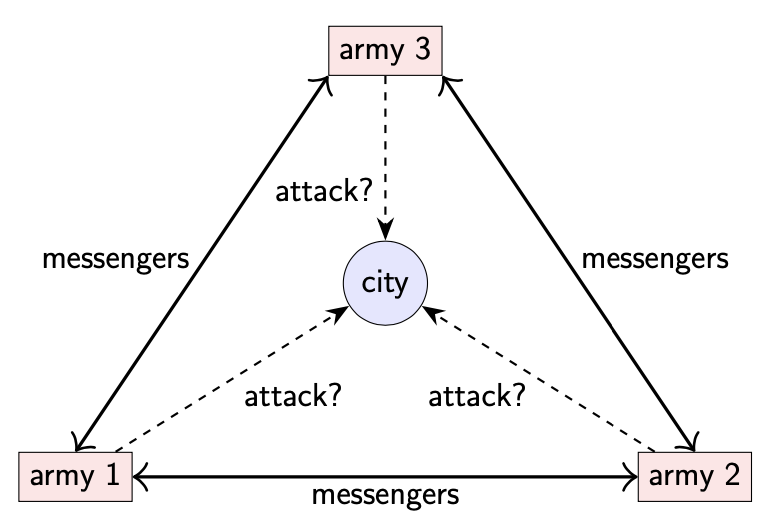
在拜占庭将军问题中,有些将军可能是叛徒:他们可能会故意误导及迷惑其他将军。我们把叛徒称为 “malicious”,其他将军称为 “honest”。
malicious 可能有以下行为:
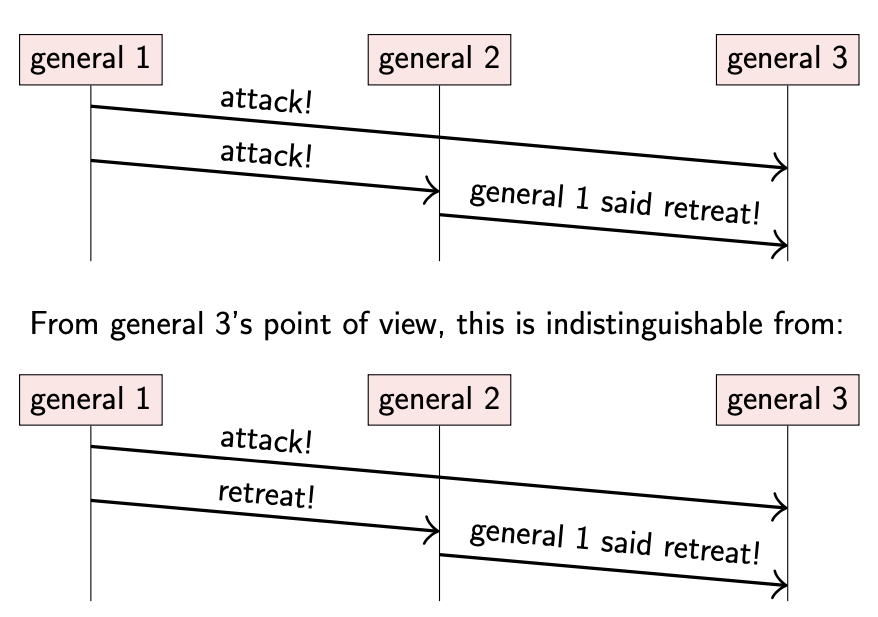
- 将军 3 分别从将军 1 & 将军 2 收到两条矛盾的消息
- 将军 1 声明要进攻
- 将军 2 声明将军 1 想要撤退
- 将军 3 无法确定将军 2 是否在撒谎
- 第一种场景,将军 2 在撒谎
- 第二种场景,由于将军 1 先后声明了两个矛盾的消息,此时将军 2 并没有撒谎
honest 并不知道哪些是 malicious,但是 malicious 之间可以秘密串通协调他们的行动。拜占庭将军问题的目标是需要确保所有的 honest 对计划达成一致:不管是进攻还是撤退。
根据设定,我们无法确定 malicious 的行动,所能做的只有让 honest 达成一致
然而由于 malicious 的存在及不可预测的通信延迟,使得上述目标很难实现;只有在 malicious 的数目严格少于 1/3 时,拜占庭问题才能得到解决。如果系统中存在 3*f+1 个节点,那么 malicious 数目不能多于 f。
通过引入密码学会使得拜占庭将军问题变得相对简单,但是问题仍然存在,例如数字签名:将军 2 需要向将军 3 证明将军 1 的声明。
那么拜占庭将军问题是否具有实际意义?
在实际的分布式系统中,通常涉及比较复杂的信任关系。比如,消费者需要信任在线商店真的会发送订单中的商品,尽管消费者在商品无法送达或者其他原因向银行提出异议。但是如果在线商店允许消费者在不支付的情况下就可以下单,这种情况下可能会被欺诈者利用,因此在线商店会假设消费者是潜在的 malicious。另一方面,在线商店的多个服务同属一个数据中心,它们内部间基本互相信任,但是支付服务并不完全信任在线商店服务,因为其他人可能会设立欺诈性的商店或者使用被盗信用卡(不过在线商店服务通常信任支付服务)。最后,我们期望消费者,在线商店,支付服务就任何订单达成一致。
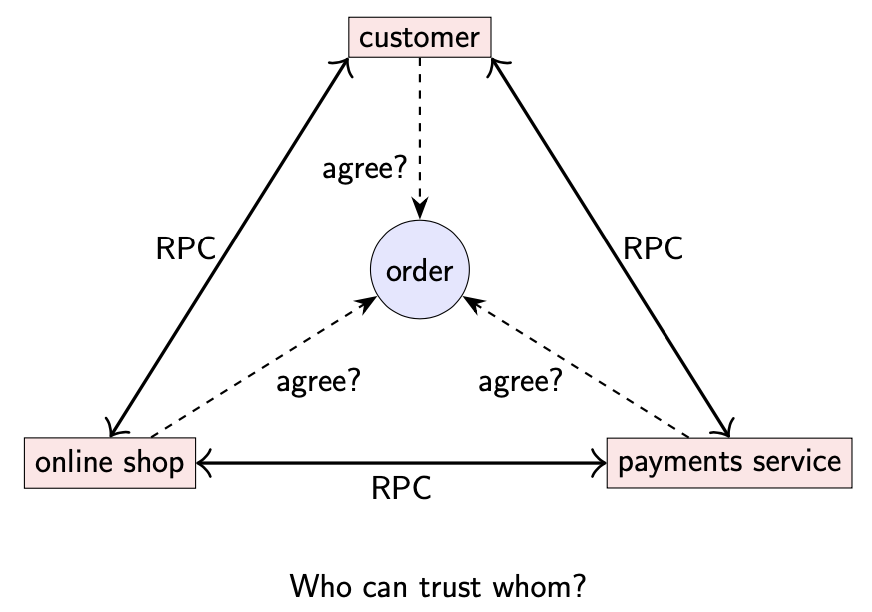
拜占庭将军问题可以看作是复杂信任关系的简化
在一些分布式系统中,会明确处理存在 malicious 节点的可能性,这类系统被称为 Byzantine fault tolerant。近些年来,该观点在区块链及加密货币中逐渐流行起来:即使系统的一些参与者试图欺骗或破坏系统,系统也能提供明确的保证。
2-3 Describing nodes and network behavior
当设计分布式算法时,system model 是对可能发生故障的假设。上文描述了两种 system model:
- Two generals problem: a model of networks
- Byzantine generals problem: a model of node behavior
在 system model 中传递的消息被捕获可能因为:
- Network behavior:消息丢失等
- Node behavior:节点崩溃等
- Timing behavior:延迟等
2-3-1 Network behavior
不存在完全可靠的网络:即使是在精心设计且有冗余连接的网络中。 大多数分布式算法都假设网络在一对节点间提供双向通信服务,被称为点对点通信(point-to-point)或者单播通信(unicast)。在真实的网络中有时确实提供广播(broadcast)或多播(multicast)通信(一个数据包同时发送给多个接收者)。不过,通常来说,假设只存在单播(unicast)是一个比较好的网络模型。
接下来我们可以假设网络的可靠性,大部分算法假设如下:
- Reliable (perfect) links 只有在消息被发送时,才会收到消息。不过,消息可能会被重排序。
- Fair-loss links 消息可能会丢失,重复或重排序。如果继续重试,消息最终会被成功发送。
- Arbitrary links (active adversary) 存在 malicious 节点干扰信息传递(窃听,篡改,丢弃,伪造,重放等)。
网络分区(network partition):一些连接长时间丢弃或延迟所有消息
我们可以将上述某些类型的网络转换为其他类型,如下图:

比如当前网络类型为 Fair-loss link,通过持续发送丢失的消息直到被成功接收,及在接收方过滤重复的消息,可以将 Fair-loss link 类型转换为 Reliable link 类型。
Fair-loss 类型意味着网络分区(network partition)只会持续一段时间,并不是永久故障;所以消息最终一定会被接收。
不过,网络分区期间发送的消息只能等到故障恢复之后才能被接收,而故障的时间可能比较长
之前提到的 TCP 协议在网络数据包层面提供了重试及重复数据过滤的机制,不过 TCP 通常配置了超时时间,在重试了一个确定的时间之后就会放弃重试(一般为 1min)。因此为了应对较长时间的网络分区(network partition),需要在 TCP 之上额外实现一套重试及重复数据过滤机制。
Arbitrary 类型是互联网通信的准确模型:每当你通过互联网进行通信时(可能是通过咖啡店的 wifi),网络运营商可以任意操作 & 干扰你的网络数据包。操作网络流量的人也被称为 active adversary。不过,通过使用加密技术几乎(almost)可以将 Arbitrary 类型的网络转换为 Fair-loss 类型。TLS(Transport Layer Security)协议可以防止 active adversary 进行窃听,篡改,伪造,重放流量等操作。不过,TLS 唯一不能阻止 active adversary 进行丢弃(dropping/blocking)网络包操作。所以,只有在 active adversary 永远不会进行 block 操作时,才能将 Arbitrary 类型的网络转换为 Fair-loss 类型。
Reliable 类型的网络看起来并不是不可实现:一般来说,只要我们在网络分区期间等待一段时间后进行重试,所有消息都能被成功接收。不过,我们也需要考虑消息发送者在重试期间崩溃(crash)的情况,这种情况下消息会永远丢失(permanently lost)。
2-3-2 Node behavior
假设每个节点运行模型的算法都为下面的一种:
- Crash-stop (fail-stop) 如果节点在任意时刻崩溃,则出现故障。崩溃之后,节点永久性地停止运行。
- Crash-recovery (fail-recovery) 节点可能在任意时刻崩溃,导致内存数据会丢失,不过持久化到磁盘上的数据并不会丢失。节点可能在一段时间后重新恢复运行。
- Byzantine (fail-arbitrary) 如果节点偏离运行的算法,则出现故障(A node is faulty if it deviates from the algorithm)。故障节点的表现可能有:崩溃或者一些恶意行为。
不存在故障的节点被称为正常节点(A node that is not faulty is called “correct”)。
在 Crash-stop 模型中,我们假设节点崩溃之后,永远不会恢复。
- 对于无法恢复的硬件故障来说,这是一种合理的模型(reasonable)
- 对于软件崩溃,Crash-stop 模型看起来不太符合,因为在节点重启之后,将会恢复。尽管如此,一些算法为了简化问题,仍然将其看作 Crash-stop 模型。在这种情况下,崩溃后恢复的节点被认为是重新加入系统中的新节点。
在 Crash-recovery 模型中,允许节点崩溃后重启并恢复运行。当节点崩溃重启时,假设内存中的数据全部丢失,但是持久化到磁盘上的数据都会被保存下来。该模型对节点崩溃后恢复所需要的时间并没有设定,因此崩溃后的节点可能永远都不会恢复。
Byzantine 模型是最常见的节点行为模型:正如拜占庭将军问题中的描述,故障节点也许不仅仅是崩溃,也可能以任何方式偏离指定的算法,包括一些恶意行为。节点服务实现中的错误(bug)也可以归类为拜占庭故障。不过,如果所有节点运行同样的软件,那么这些节点就会有同样的 bug。因此,任何基于拜占庭故障节点数少于 1/3 的算法都无法容忍此类 bug。因此,当涉及到偏离指定算法时,我们通常称为拜占庭问题,而不是 bug。
原则上,我们可以尝试使用同一算法的几种不同的实现,不过这并不是比较实际的选择。
在 network behavior 的介绍中,通过使用特定的协议可以将一种网络模型转换为另一种。不过,在 node behavior 中并不适用;比如,为 Crash-recovery 模型设计的算法与 Byzantine 模型有很大不同。
2-3-3 Synchrony (timing) assumptions
对于同步(计时)模型的假设如下所示:
-
Synchronous
消息延迟不会大于已知的上限。节点以已知的速度执行算法。
-
Partially synchronous
系统在某些有限(但未知)的时间内是异步的,否则是同步的。
-
Asynchronous
消息延迟时间不定。节点可以在任意时间暂停执行。完全没有时间保证。
上述术语在其他上下文中具有不同的含义。如,在 RPC & IO 操作中,synchronous 表示调用方会被阻塞直到操作完成;asynchronous 表示调用方在发出请求后继续执行,而不需要等待操作完成
Synchronous 模型是指通过网络发送的消息延迟永远不会大于已知的最大延迟,并且节点总是以可预测的速度执行。Synchronous 系统的假设会使得分布式计算问题变得简单,并且由于大部分时间(most of time)节点及网络都表现良好,因此该假设大部分情况下没有问题。
然而,大部分时间表现良好并不代表一直如此。如果系统在某段时间内违反了有界延迟与有界执行速度的假设,那么为 Synchronous 模型设计的算法就会崩溃。在实际系统中,网络延迟与执行速度由于各种原因会导致差异比较大。
另一个极端的假设是 Asynchronous 模型(不对延迟做任何假设):消息在网络中的延迟可以是任意的,不同节点执行速度的差异是任意的(如允许某个节点在其他节点正常运行的时候暂停执行)。为 Asynchronous 模型设计的算法通常非常健壮,因为可以不受任何临时网络中断或延迟峰值的影响。
不过,Asynchronous 模型并不能解决分布式系统中的全部问题,因此我们使用 Partially Synchronous 模型作为折中方案。在 Partially Synchronous 模型中,假设大部分情况下(most of time)系统表现良好,表现为 Synchronous;偶尔,可能会切换到 Asynchronous,其中所有定时保证都失效(该情况可能随时发生)。Partially Synchronous 模型对许多实际的系统都比较适用,不过想要正确使用需要多加小心。
2-3-4 Violations of synchrony in practice
网络通常具有可预测的延迟,不过偶尔延迟会增大,从而导致系统违背 Synchronous 模型,具体原因可能有:
- 消息丢失或者重试,导致延迟大幅增加
- 在网络分区修复前,消息不能被成功传递
- 如果网络阻塞导致数据包在交换机缓冲区中排队等待,也会增加延迟
- 网络重新配置同样会增大延迟,即使是在同一个数据中心,也可能会导致延迟超过一分钟
同样,节点通常也会以恒定的速度执行程序代码,偶尔也会因为意外导致程序暂停执行(pause):
- 操作系统调度问题:正在运行的进程可能会被抢占,导致暂停,尤其当机器处于高负载的情况下
- 对于一些实现内存管理的语言,比如 Java,当垃圾回收器在运行的时候,需要时不时地暂停正在运行的线程(垃圾回收可能会长达几分钟)
- 缺页中断也会导致线程挂起,尤其是没有多少空闲内存时
需要注意,此处说的 pause 与前文对节点行为描述中的 crash 并不相同。暂停中的进程通常没有意识到自己处于暂停状态,虽然其他节点在没有收到暂停节点的响应时,可能认为其已经崩溃。但是,过了一段时间,暂停的进程会重新恢复运行。另外,重启崩溃的节点需要由程序显示处理,因为其内存状态已经完全丢失,需要从磁盘中重新加载持久化数据;而暂停的进程内存数据并没有丢失
综合以上多种原因,如果假设一个系统为 Synchronous 模型,可能并不安全。因此,大多数分布式系统需要被设计成 Partially synchronous 或者 Asynchronous。
2-3-5 System models summary
在设计分布式系统模型时,需要对网络,节点行为,同步类型等进行合理假设,这些是分布式算法的基础:
- Network: reliable, fair-loss, or arbitrary
- Node: crash-stop, crash-recovery, or Byzantine
- Timing: synchronous, partially synchronous, or asynchronous
2-4 Fault tolerance and high availability
对于网站来说,服务的可用性(availability)可能是最重要的。比如,在线商店想要在任何时候都能售卖产品:网站的中断意味着失去赚钱的机会。对于其他服务来说,可能与客户签订了协议保证服务的可用性,如果服务不可用会对其声誉造成损失。
服务的可用性通常根据其在特定时间内正确响应请求的能力来衡量。
如何定义服务是可用的还是不可用:如果网站加载网页需要 5s,那么我们认为服务是可用的吗?如果耗时 30s, 1h 呢?服务的可用性预期被定义为 Service-Level Objective (SLO):需要在指定超时时间内返回正确响应的请求的百分比(由特定客户端在特定时间内测量)。Service-Level Aggrement (SLA) 是规定了一些 SLO 的协议,以及没有满足 SLO 的后果。
2-4-1 Fault tolerance
故障(faults,如节点崩溃或者网络中断)是影响可用性的常见原因。为了提高可用性,我们可以减少故障发生的频率,或者将系统设计成即使某些组件故障,仍能继续提供服务,这种方式被称为容错(fault tolerance)。
通过购买高质量的硬件,同时引入冗余,可以降低故障发生的频率,但是这种方式并不能完全杜绝故障发生;因此,需要系统都采用容错的方式提高可用性。
容错总是相对于最大容忍的故障节点数量:一些分布式算法能够在崩溃节点数量少于一半的情况下继续运行,但是如果超过一半节点故障,则无法运行。
想要容忍没有限制的节点故障没有意义:当所有节点崩溃且无法恢复时,没有算法能够继续运行。
在某些系统中,单个组件的故障可能会导致整个系统的中断,这种组件被称为单点故障(single point of failure, SPOF)。容错系统通常需要避免单点故障。
在这里,我们需要区分下 Fault & Failure:
- Fault: 系统的某一部分不可用,可能是由于节点故障或者网络故障导致
- Failure: 整个系统不可用
2-4-2 Failure detection
为了实现容错,首先需要能够检测故障,由故障检测器(failure detector)完成。故障检测器通常能够检测到节点崩溃故障,但是对于拜占庭(Byzantine)故障并不能总是检测出:虽然在某些 Byzantine 行为下会留下一些证据用于识别 malicious 节点。
大部分情况下,故障检测器周期性地向其他节点发送消息,如果在预期时间内没有收到响应则将节点标记为崩溃(crash)。理想情况下,我们期望只有在节点真正崩溃时才会检测超时(这种检测器被称为 perfect failure detector)。但是,两将军问题表明这并不是一种完全准确的检测方式,没有收到响应可能是因为消息丢失(message loss)或者延迟(delay)。
基于超时检测的 perfect failure detector 只存在于具有可靠网络连接的同步(synchronous)且崩溃中止(crash-stop)系统中。在异步(asynchronous)系统中,超时并不具备实际意义,因此也就不存在基于超时的故障。在部分同步(partially synchronous)系统中,不存在 perfect failure detector;但是存在另一种有用的故障检测器:eventually perfect failure detector。
对于 eventually perfect failure detector,表现有:
- 可能暂时(temporarily)将一个正常(correct)的节点标记为崩溃(crash)
- 可能暂时(temporarily)将一个崩溃(crash)的节点标记为正常(correct)
- 但是最终(eventually),当且仅当节点已经崩溃了,才会将其标记为崩溃
从中我们可以看到,检测并不是瞬时的,可能会存在错误的检测结果
后面将继续介绍如何使用这种故障检测器来设计容错机制,以及如何从节点崩溃中自动恢复。
3-Time, clocks, and ordering of events
在分布式系统中,我们经常需要测量时间。
- 基于超时的故障检测器需要计算时间用于决定检测是否超时
- 操作系统广泛依赖计时器用于任务调度,CPU 使用情况追踪等
- 应用程序通常会记录事件发生的事件,我们可以根据这些时间重建不同节点上同时发生的事件;或者判断不同节点不同事件发生的顺序
- 在日志文件和数据库中,也需要记录事件发生的时间
- 内存中的缓存需要有一定的实效性(过期失效)
- 应用性能测量
- ….
我们将区分两种类型的时钟:
- 物理时钟(physical clocks):计算真实时间(count number of seconds elapsed)
- 逻辑时钟(logical clocks):计算事件(count events, e.g. messages sent)
注意:数字时钟(振荡器)不等于分布式系统中的时钟(时间戳)
3-1 Physical clocks
物理时钟以秒为单位测量时间。物理时钟包括基于钟摆或者类似钟摆机制的模拟或机械时钟(analogue/mechanical clocks),也包括基于石英晶体震荡的数字时钟(digital clocks)。
物理时钟有时候也被称为挂在墙上的时钟(wall clock)
石英时钟出现在大部分手表,计算机,手机等物品中。石英时钟比较便宜,但是并不完全精确(accurate)。由于制造的缺陷,某些时钟可能要比其他的运行快/慢,并且石英震动频率受温度影响。
时钟震荡频率的快慢被称为漂移(drift)。
- 漂移以 parts per million (ppm)为单位进行测量
- 1 ppm = 1 microsecond/second = 86 ms/day = 32 s/year
- 大部分计算机的时钟精度大约在 50ppm 以内
3-1-1 UTC & TAI
如果需要提高时钟的精度,可以使用原子时钟(atomic clocks)。原子时钟基于某些原子的量子力学特性,如铯或铷(International Atomic Time,TAI,国际原子时间)
事实上,国际单位制(SI)中一秒的时间单位被定义为铯-133 原子特定共振频率的9,192,631,770个周期。
另一种获取高精度时钟的方法是依靠 GPS 等卫星定位系统。通过将 GPS 接收器连接到计算机,可以获得精确到几分之一微秒的时钟。
在数据中心,电磁干扰通常太大,无法获得良好的信号,因此 GPS 接收器需要在数据中心大楼的屋顶上安装天线
有一点需要指出,地球自转时间并不是严格的 24h,而且收到地震,潮汐等影响,自转周期并不固定。因此,基于量子力学的时钟(原子时钟)与基于天文学的时钟(日出日落)并不完全匹配。通过引入 UTC(Coordinated Universal Time)解决这个问题:UTC 基于原子时间,但包括考虑到地球自转变化的校正。
日常生活中,我们使用的本地时区为 UTC 的偏移(offset)
UTC 与 TAI 之间的区别是,UTC 包括了闰秒(leap seconds)。由于闰秒的存在,导致 1 小时不总是 3600 秒,1 天也不总是 86400 秒。在 UTC 时间范围内,1 天可能是 86399 秒,86400 秒或者 86401 秒。
闰秒发生在每年 6 月 30 日与 12 月 31 日的 23:59:59 UTC
3-1-2 How computers represent timestamps
在计算机中,timestamp 用于表示一个特定的时间点。有两种常见的表示 timestamp 的方法:
- Unix time
- ISO 8601
对于 Unix time,0 对应于 1970 年 1 月 1 日(UTC or GMT),也被称为 epoch。
在 Java 中,存在一些微小的变化:Java 中的
System.currentTimeMillis()表示毫秒而不是秒
Unix timestamp 直接忽略了闰秒,假装其不存在;并且这种方式也被 Posix 标准采用。对于那些只需要粗略计时的软件来说,这种方式是可行的,因为几秒的差异并不显著。
然而,操作系统和分布式系统经常确实会依赖高精度 timestamp 来准确测量时间,其中 1s 的差异非常明显。这种情况下,如果直接忽略闰秒可能会存在风险。假如 Java 程序在闰秒内连续两次调用 System.currentTimeMillis() ,每次间隔 500ms。这两次调用结果之间的差值不会是 500,可能是 0,也可能是负数。
2012 年 6 月 30 日闰秒处理不当是导致当天许多服务同时失败的原因
如今,许多软件都额外处理闰秒,比较实用的方法是:当闰秒发生时,并不是在 23:59:59 与 00:00:00 之间插入 1s,而是将这 1s 分散到其他时间段内,可能会加快/减慢时钟的速度。这种fang 被称为抹平(smearing)闰秒。
3-2 Clock synchronisation and monotonic clocks
3-2-1 Clock synchronisation
由于原子时钟(atomic clocks)过于昂贵且笨重,无法内置于计算机与手机上,因此一般使用石英时钟(quartz clocks)。然而,由于时钟漂移(drift),时钟误差会越来越大,因此需要定期从具有更准确时间源的服务器(原子钟或 GPS 接收器)获取当前时间。一般是通过 Network Time Protocol (NTP) 进行同步。
所有主流操作系统都内置了NTP客户端
时钟服务器的层次结构排列为:
- 第 0 层:原子时钟或者 GPS 接收器
- 第 1 层:直接与第 0 层设备同步
- 第 2 层:与第 2 层同步的服务器
由于网络延迟的不确定性,通过网络进行时钟同步也存在一定问题。为了减少偶然性带来的影响,NTP 采集了几个时间测量样本,并通过统计过滤器来消除异常值。
- 与多个时钟服务器进行通信,丢弃异常值,并对剩下的取平均值
- 对同一台服务器进行多次请求,减少网络延迟导致的随机异常
时钟倾斜(skew)指的是同一个时间点,两个不同时钟的差异。如何通过 NTP 评估客户端与时钟服务器之间的时钟倾斜?
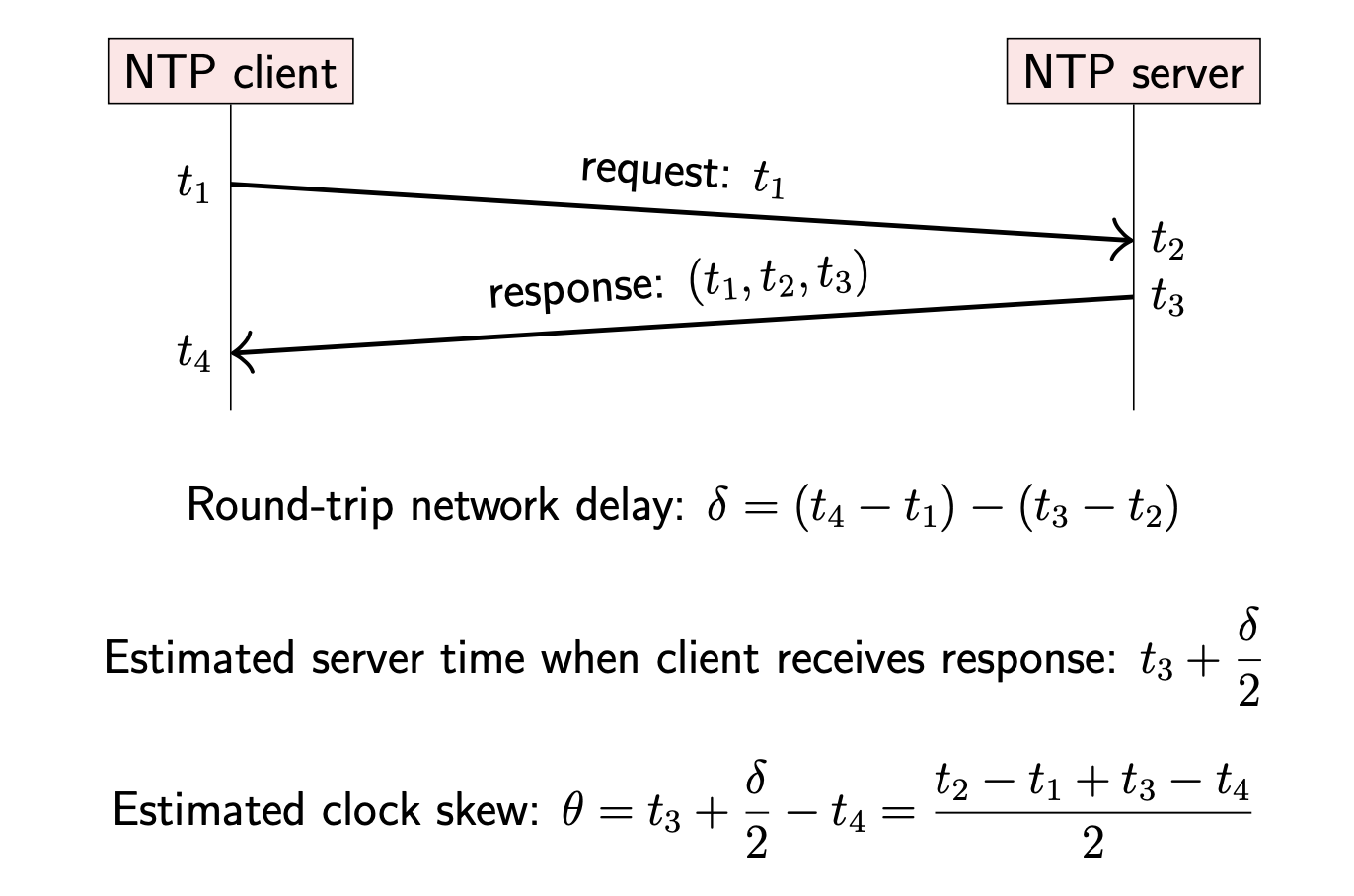
- NTP Client 向 NTP Server 发送请求,请求消息中携带 Client 的当前 timestamp t1(Client 的时钟)
- NTP Server 收到 Client 的请求,在处理请求前,先计算当前 timestamp t2(Server 时钟)
- NTP Server 处理完请求并发送响应。响应消息中携带:t1(请求发送 timestamp),t2(请求接收 timestamp),t3(响应 timestamp,Server 时钟)
- NTP Client 收到响应时,记录当前 timestamp t4(Client 时钟)
- 从 Client 的视角看,请求发出到接收的往返时间为 t4-t1,Server 处理请求的时间为 t3-t2,那么网络传输的时间为 (t4-t1)-(t3-t2),单向网络延迟约 t = ((t4-t1)-(t3-t2))/2
- 当响应到达 Client 时,我们可以估计 NTP Server 在此刻的时间约为 t3+t
- 此时我们可以预估 Client 与 Server 的时钟偏差(skew)为:t4-(t3+t)。
上述对时钟偏差的预估依赖网络的往返延迟大致相同的假设。该假设可能是正确的,但是如果网络中的排队时间是网络延迟的重要因素,那么请求与响应的延迟会有很大不同(如某个节点的网络连接负载较重,而其他节点比较空闲)。
然而,大部分网络并无法提供往返延迟基本一致的保证
一旦 NTP Client 预估了与 NTP Server 之间的时钟偏差,接下来需要调整自身的时钟与 Server 保持一致。时钟同步的方法取决于时钟倾斜的范围(amount of the skew)t:
-
|t|<125ms ,slew the clock
Client 通过稍快或者稍慢的速度(500ppm)运行,在之后的几分钟内(5min)逐渐减小偏差
-
125ms < |t| < 1000s ,step the clock
如果此时仍然采用 slew 的方式,同步周期将会很长。因此,Client 采用 step 的方式强行将自身时钟与 Server 保持一致。
会导致时钟突然向前或者向后跳了一段
-
|t| > 1000s,panic and do nothing
当偏移很大的时候(默认不超过 15min),NTP Client 会认为此时出现了异常,从而拒绝调整时钟,由运维人员去调整。
因此,时钟并不会一直保持同步,运维人员需要关注时钟偏移的范围
3-2-2 Time-of-day clock and Monotonic clock
通过 NTP 进行时钟同步可能会导致时钟跳转,因此对那些需要测量经过时间的应用来说有比较大的影响。下面是 Java 计算 dosomething() 的耗时,有两种写法:
// bad
long startTime = System.currentTimeMillis();
doSomething();
long endTime = System.currentTimeMillis();
long elapsedMillis = endTime -startTime;
// good
long startTime = System.nanoTime();
doSomething();
long endTime = System.nanoTime();
long elapsedNanos = endTime -startTime;
这两种写法有什么区别,首先需要清楚 currentTimeMillis() 与 nanoTime() 的区别:
currentTimeMillis()表示是真实的时间(real-time),表示从 1970.01.01 开始经历的时间。当 NTP 跳转时,该时间也跳转。如果用其计算经过的时间,结果可能比实际值大或者小,甚至为负数。nanoTime()是一个单调时钟(monotonic clock),并不会受 NTP 跳转影响,只会向前计算(NTP slew 只会影响其向前的速度)。因此,用nanoTime()计算经过的时间相对更准确。不过,nanoTime()只是表示从某个任意时间点经过的时间(如计算机启动的时间点);不同计算机的nanoTime()比较并不具备实际意义。
大多数操作系统及编程语言都提供了这两种时间
3-3 Causality and happens-before
在分布式系统中存在与时间密切相关的问题:事件排序(order events)。
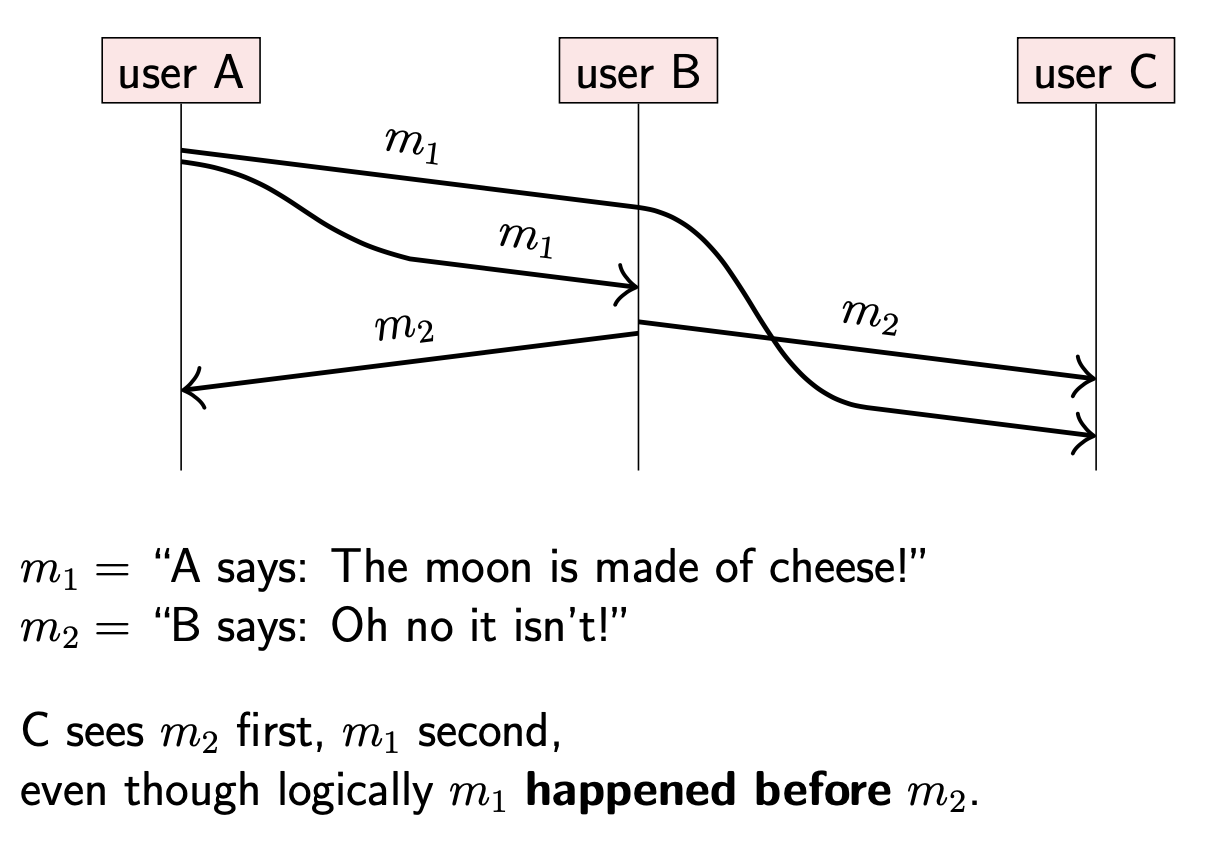
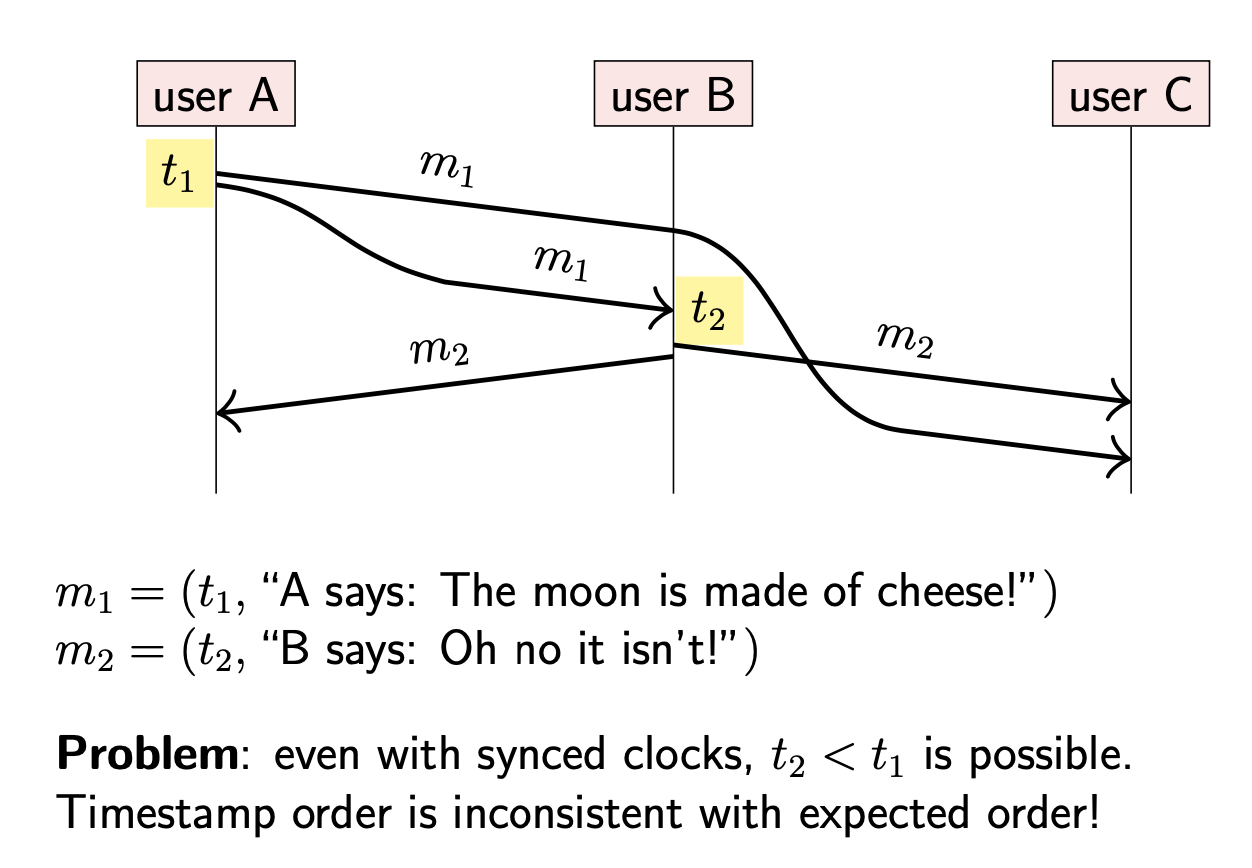
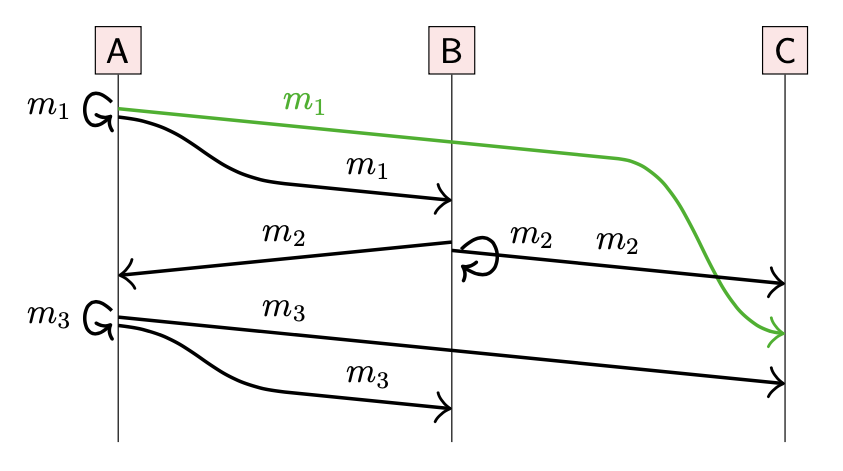
在上图中,A 发送消息 m1 给 B,C 两个用户;B 在收到 m1 之后,回复 m2 给 A,C 。然而,即使网络是可靠的(reliable),也是会存在重排序的情况。所以可能存在 C 在收到 m1 前就收到了 m2 的现象。从 C 的视角看,结果令人疑惑:先收到了回复,再收到了问题,好像 B 能够未卜先知。
在现实生活中,这种现象不会发生,所以我们也希望在计算机系统中也不发生
进一步讨论这个问题,假设 m1 是在数据库中创建对象的指令,m2 是更新该对象的指令。如果节点在处理 m1 操作前就处理了 m2,那么结果就是首先更新一个不存在的对象,之后再创建一个随后不会被更新的对象。在数据库操作中,只有 m1 发生在 m2 之前才会有意义。
3-3-1 Physical timestamps inconsistent with causality
那么对 C 来说,如何确定消息的正确顺序?
由于单调时钟(monotonic clock)在不同节点间(A & B)的比较没有实际意义,因此不可采用。
尝试使用代表真实时间的物理时钟时间戳:每个消息都附带当前时间戳。在这种情况下,我们可以合理预估 m2 拥有比 m1 更靠后的时间戳,因为 m2 是对 m1 的响应,所以 m2 一定在 m1 之后发生(happen after)。
然而在部分同步(partially synchronous)的系统中,这种方式并不可靠。通过 NTP 或者类似协议进行的时钟同步并不能准确判断时钟偏差,尤其是在双向网络延迟不相同的情况下,这种不确定性会加大。因此,我们不能排除下面这种场景:
- A 根据自身时钟将时间戳 t1 附着在消息 m1 上发送
- B 收到 m1,并根据自身时钟获取当前时间戳 t2。由于 A 的时钟比 B 稍微快一点,导致 t2<t1。
此时,如果按照时间戳进行排序仍然会得到错误的顺序。
3-3-2 The happens-before relation
什么是正确的顺序?我们使用 Happen-before relation 来定义正确的顺序。该定义假设每个节点只有一个正在执行的线程,因此对于同一个节点上的两个执行步骤可以明确其先后顺序。更正式地说,假设同一个节点上的操作严格全局有序(strict total order)。
对于同一个进程的多个线程,可以把每个线程用独立的(separate node)节点表示
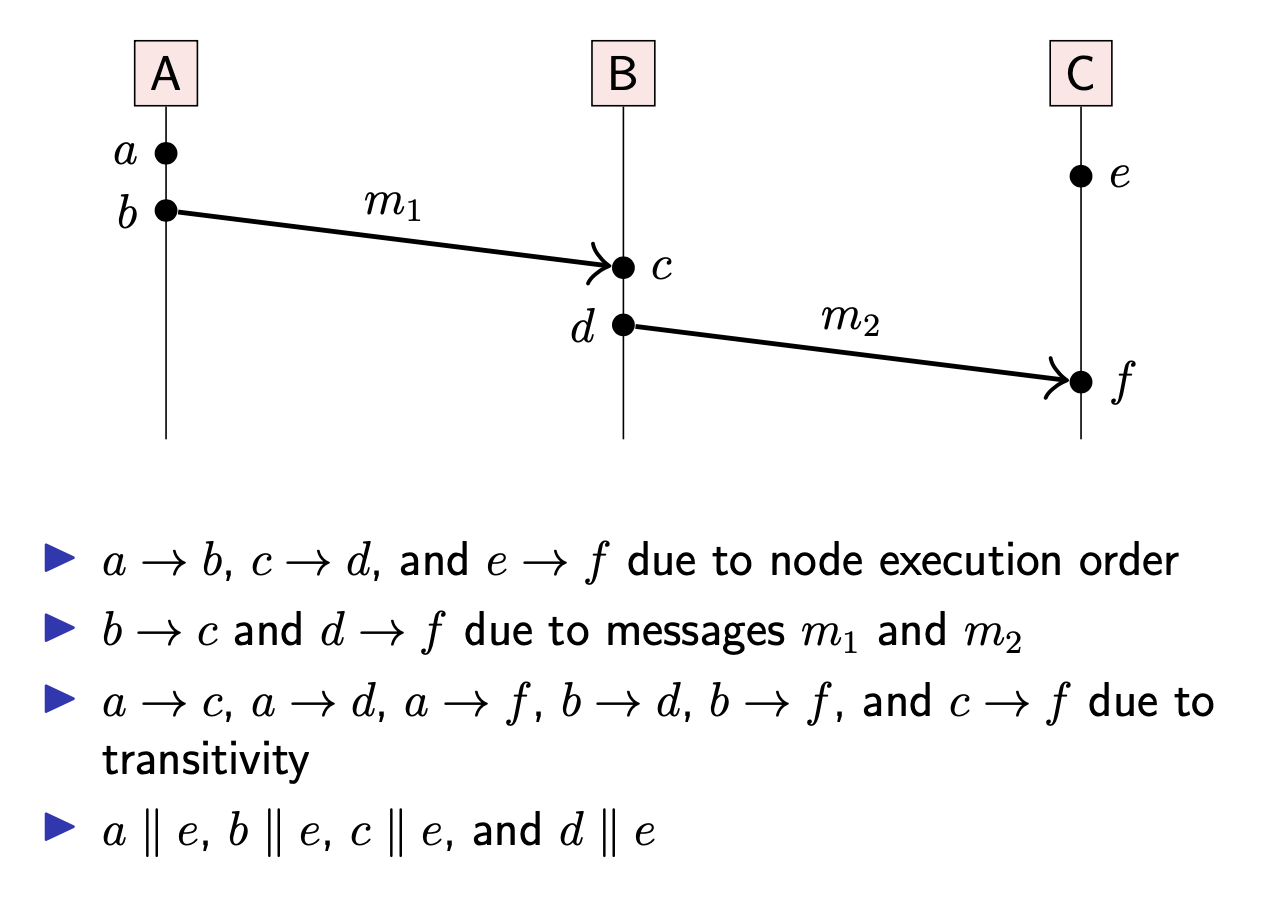
什么是 Happen-before?当操作 a 与 b 满足以下条件其中一个时,我们可以认为 a Happen-before b,记为 a→b:
- a 与 b 发生在同一个节点,并且 a 的本地执行顺序在 b 之前
- a 表示发送消息 m,b 表示接收同一个消息 m(假设消息 m 是唯一的)
- 存在操作 c,并且满足 a→c,c→b
我们可以把这种顺序扩展到多个节点:定义同一个消息在接收之前被发送(忽略网络延迟)。为了方便起见,假设每条消息都是唯一的,当接收到一条消息,总是可以确定其发送方及发送时间。
Happen-before 关系是偏序关系(partial order),因此会出现 a→b 与 b→a 都不满足的情况,此时 a 与 b 称为 Concurrent,记为 a || b。
此处的 concurrent 并不是指 a & b 同时发生,而是指 a & b 是独立的,不存在依赖关系
下面是 Happen-before 的示例:
3-3-3 Causality
Happen-before 是分布式系统中判断因果关系(causality)的一种方式。
因果关系(causality)关注信息是否可以从一个事件传递到另一个事件,从而导致一个事件影响到另一个事件。在上面消息传递的例子中,m2 是对 m1 的回复,因此 m1 影响了 m2。
一个事件是否真的影响了另一个事件是一个哲学问题;对我们来说 m2 发送前已经收到了 m1 才是我们关心的
因果关系的概念借鉴了物理学。人们普遍认为,信息不可能比光速传播得更快。
- 如果有两个事件 a & b 在空间中相距足够远,但在时间上相近。那么事件 a 不可能在事件 b 之前到达 b 的位置,反之亦然。因此,事件 a & b 肯定不存在因果关系(causally unrelated)
- 如果事件 c 在空间上与 a 相近,并且在 a 发生后的一段时间,那么事件 a 可能会给 c 传递信号,从而影响 c
分布式系统中的情况与之类似。
4-Broadcast protocols and logical time
广播协议(broadcast protocols)或者多播协议(multicast protocols)是指将一个消息发送给多个接收者的算法;主要用于构建更上一层的分布式算法。在实践中,有几种不同的广播协议,它们之间最大的区别在于消息发送的顺序(order)。
正如上文描述的,顺序与时间 & 时钟密切相关。接下来,需要进一步研究时钟如何帮助追踪分布式系统中的顺序。
4-1 Logical time
在之前的例子中,我们可以看到物理时钟时间戳可能与因果关系并不一致(inconsistent with causality),即使使用类似 NTP 协议进行时钟同步。
尽管 send(m1) → send(m2),也可能存在 timestamp(m1) > timestamp(m2)
相比之下,逻辑时钟(logical clocks)更注重于分布式系统中的事件顺序。
4-1-1 Logical vs. physical clocks
物理时钟:
- 计算经过的秒数
- 可以用于很多方面,但是可能会与因果关系不一致
逻辑时钟:
- 计算事件发生的次数
- 用于获取因果依赖关系(capture causal dependencies):(e1->e2)=>(T(e1)<T(e2)).
有两种类型的逻辑时钟:
- Lamport clocks
- Vector clocks
4-1-2 Lamport clocks
Lamport 时间戳本质上是一个整数,用于计算已经发生的事件数量;与物理时钟没有直接关系。在每个节点,由于事件的发生,整数就会增加,相应地 Lamport 也会增加。
该算法的假设适用于 crash-stop 模型(如果 crash-recovery 模型将时间戳持久化存储,则也可以用于该模型中)
当消息通过网络发送,发送者就会将当前的 Lamport 时间戳附在消息上。
当接收者收到消息后,会将本地的 Lamport 时钟向前移动到消息携带的时间戳 + 1。如果接收者的时钟已经领先于消息携带的时间戳,那么它只会在本地时间戳上递增。
Lamport clocks 算法流程如下:
- 初始化:每个节点初始化自己的本地时钟 t
- 事件发生在本地:本地时钟 t 递增:t = t + 1
- 发送消息:本地时钟递增后 t = t + 1,将时间戳附在消息上发送(t, m)
- 收到消息:收到(t’, m)消息后,更新本地时间戳 t = max(t, t’) + 1,并将消息传递给程序
Lamport 时间戳存在这样的性质:如果事件 a happen-before b,那么 b 的时间戳总是比 a 大;也就是说时间戳与因果关系保持一致。然而,反过来并不这样:如果 b 的时间戳比 a 大,我们可以知道 b 不会在 a 之前发生,但是我们不知道是 a → b 还是 a || b。同时,两个不同的事件可能拥有相同的时间戳。
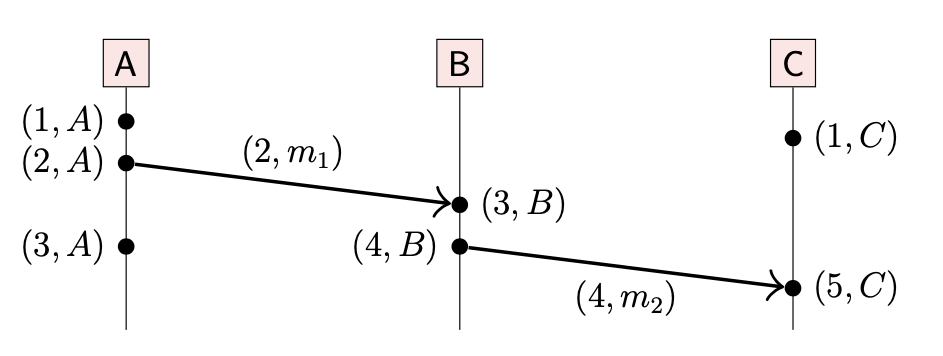
A 节点上的第三个事件与 B 节点上的第一个事件拥有相同时间戳
如果我们期望每个事件的都对应一个唯一时间戳,那么每个时间戳都可以使用发生该事件的节点的名称或标识符进行扩展(如上图)。
- 单节点范围内,每个事件被赋予唯一的时间戳
- 如果每个节点都有唯一的标识,那么时间戳与节点标识的组合为全局唯一(across all nodes)
上文介绍说 Happen-before 关系是偏序关系(partial order),通过使用 Lamport 时间戳我们可以把这种偏序关系扩展为全序关系(total order):
- 对(timestamp, node name)对进行字典排序:首先比较 timestamp 的大小,如果 timestamp 相同则比较 node name,从而可以对任意两个 (timestamp, node) 对进行比较,确定全序关系
我们使用 -> 表示 Happen-before 关系,对于全序关系使用 ≺ 表示。全序关系使得所有事件具有线性关系(linear order):
- 对任意两个不同的事件 a , b,要么存在 a ≺ b,要么存在 b ≺ a.
全序关系也是因果关系,换句话说,≺ 是偏序关系-> 的线性扩展(linear extension)
- 不管什么时候,只要存在 a->b,那么就可以得出 a ≺ b;对于 a ≺ b,我们不一定能得出 a->b.
- 然而,如果 a||b ,我们可以得出 a ≺ b 或者 b ≺ a,这两个事件的顺序由具体的算法确定.
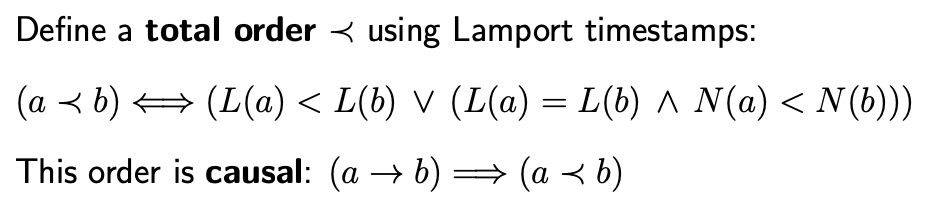
4-1-3 Vector clocks
对于给定两个事件的 Lamport 时间戳,通常不能判断这两个事件是并发(concurrent)还是存在 Happen-before 关系。
如果 b 的 Lamport 时间戳比 a 大,我们可以知道 b 不会在 a 之前发生,但是我们不知道是 a → b 还是 a || b;给定的两个 Lamport 时间戳虽然可以进行全局比较,但是不一定能够确定事件的先后顺序
如果我们想要检测两个事件是否是并发的,需要使用另一种逻辑时钟:向量时钟(vector clocks)。
与 Lamport 时间戳只使用一个整数(可能会附带 node name)不同,向量时钟是一组整数列表,每个整数对应系统中的一个节点。
- 如果节点列表用 <N1,N2,N3…Nn> 表示,那么向量时钟用 <t1,t2,t3…tn> 表示,其中 ti 与 Ni 对应.
- ti 表示在节点 Ni 上发生的事件数量
- 对于向量时钟 T=<t1,t2,t3…tn>,我们使用 T[i] 表示 ti.
Lamport 时钟是标量,向量时钟是矢量;除了这点区别外,向量时钟算法与 Lamport 时钟算法很相似。
- 每个节点初始化向量时钟 T := <0,0,…,0>,向量中的元素与系统节点一一对应
- 当事件发生在节点 Ni 时,该节点将向量时钟的第 i 个元素递增:T[i]=T[i]+1.
- 当通过网络发送消息 m 时,发送者递增自己的向量时钟 T[i]=T[i]+1,同时将当前向量时钟被附着在消息上一起发送: (T,m).
- 当收到消息后,接收者将消息中的向量时钟 (T’,m) 与自己本地的向量时钟 T 比较并合并:T[j] := max(T[j],T′[j]),j={1,2,3…n},之后递增自己的向量时钟:T[i]=T[i]+1,再将消息 m 传递给程序.
下面是向量时钟的例子:
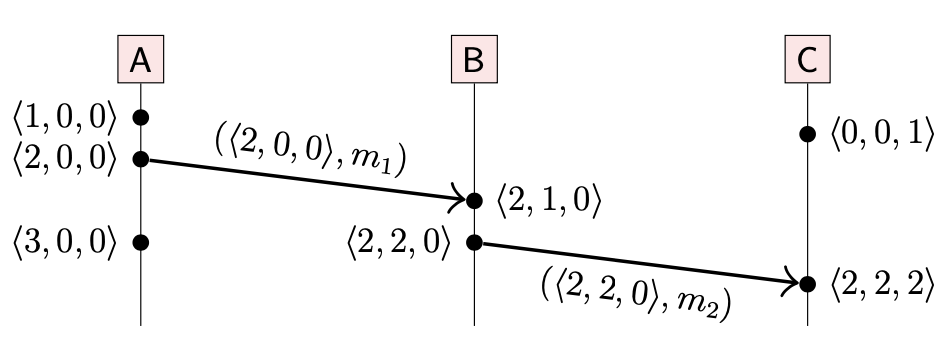
当节点 C 从 B 收到消息 m2 时,会将自己本地的向量时钟中表示节点 A 的元素也更新为 2,因为收到消息这个事件与发生在 A 上的两个事件有间接的因果关系(indirect causal)。因此,向量时间戳反映出了 Happen-before 关系的传递性。
通过向量时钟可以定义偏序顺序:
-
如果向量 T 的每个元素都等于另一个向量 T’ 中的对应元素,则 T=T’.
T =T′ iff T[i] = T′[i] for all i∈{1,…,n}
-
如果向量 T 的每个元素都小于或者等于另一个向量 T’ 中的对应元素,则 T<=T’.
T ≤T′ iff T[i] ≤ T′[i] for all i∈{1,…,n}
-
如果向量 T<=T’ 并且它们间至少存在一个元素不同,则 T<T’.
T <T′ iff T ≤ T′ and T != T′
-
如果向量 T 的某个元素比向量 T’ 对应元素大,而 T’ 的另一个元素比 T 对应元素大,那么这两个向量无法比较:T||T’. 如 T = ⟨2,2,0⟩ , T′ = ⟨0,0,1⟩,其中 T[1] > T′[1] 但是 T[3] < T′[3].
T || T′ iff T !≤ T′ and T’ !≤ T
向量时间戳展现出的偏序关系与 Happen-before 定义的偏序关系完全对应。因此,向量时钟算法提供了计算 Happen-before 关系的机制。
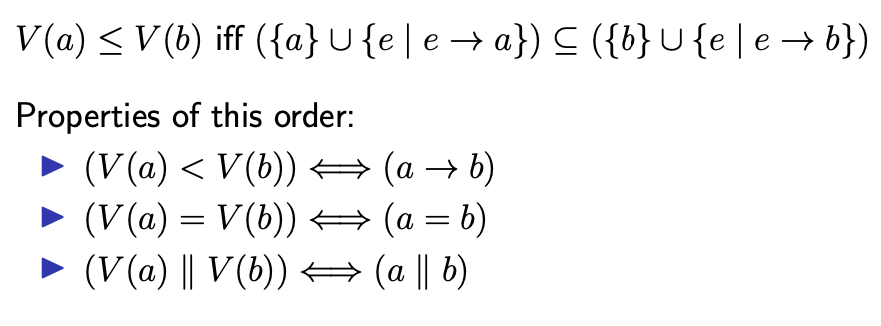
4-1-4 Summary
对于逻辑时钟,我们讨论了两种关键算法:
- Lamport 时钟:提供了全序关系(total order)
- 向量时钟:计算 Happen-before 的偏序关系
也有许多其他算法提出:如混合时钟(hybrid clocks)将逻辑时钟与物理时钟的特性结合起来。
4-2 Delivery order in broadcast protocols
许多网络提供点对点协议(单播,unicast),其中每个消息都有特定的接收者。我们将要讨论广播协议(broadcast),该协议中每个消息被发送给某个组中的所有节点。
网络组中的成员可能是固定的,也可能允许节点的加入与离开
一些局域网在硬件层面提供了多播(multicast)或者广播(broadcast),如 IP 多播,但是在互联网上的通信通常只允许单播。不过,硬件层面的广播通常只能提供 Best-effort:允许消息丢失。
之前讨论的 Node behavior 与 Synchrony model 可以扩展到广播组中
如果我们想在单播协议上构建广播协议,需要使用广播算法。
- 发送者程序通过单播链路向其他节点发送消息
- 接收者程序通过单播链路接收消息
-
广播算法将消息发送给接收者应用程序
有几种不同类型的广播协议,这些协议都是可靠的(reliable):所有消息最终都会发送给每个无故障节点(network behavior: reliable),但是没有延迟保证(synchrony model: partially synchronous)。这些广播协议在消息传递到每个节点的顺序上有所不同。
消息顺序的差异是不同广播算法间重要的区分
4-2-1 FIFO broadcast
定义:如果消息 m1, m2 由同一个节点广播,并且 broadcast(m1) → broadcast(m2),那么 m1 一定会在 m2 之前到达。
FIFO 广播模型是最弱的(weakest),与 FIFO 网络链路密切相关。在该模型中,同一个节点发送的消息按照发送顺序到达;但是不同节点发送的消息可以以任意顺序到达。
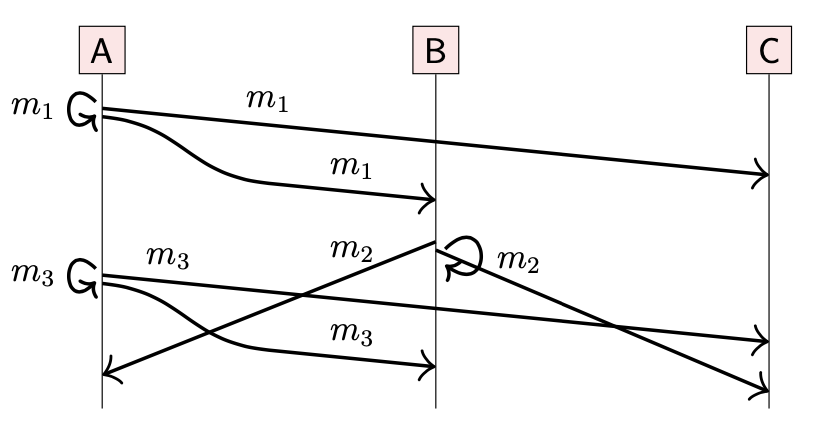
m1 一定会在 m3 之前到达:均由 A 节点发送;m2 相较于 m1, m3,可以在任意时间到达
另外,对于这些广播协议,我们假设一个节点不管什么时候广播消息,同时会将该消息发送给自己。
该特性在全序广播中将会被用到
4-2-2 Causal broadcast
FIFO 广播可能会违反因果关系:在上图的示例中,节点 C 在收到 m1 前收到了 m2,即使 B 是在收到 m1 之后再广播 m2。
Causal broadcast 相对于 FIFO,能够提供更严格的顺序保证:确保消息按照因果关系到达。
- 如果 broadcast(m1) → broadcast(m2),那么所有节点也必须按照该顺序收到 m1, m2。
- 如果 broadcast(m1) || broadcast(m2),那么节点可以按照任意顺序接收 m1, m2。
在之前的示例中,如果节点 C 在接收到 m1 之前收到了 m2,那么运行在 C 上的广播算法会 hold back(保留 or 缓冲)m2,直到接收到 m1,从而确保消息按照因果顺序接收到。
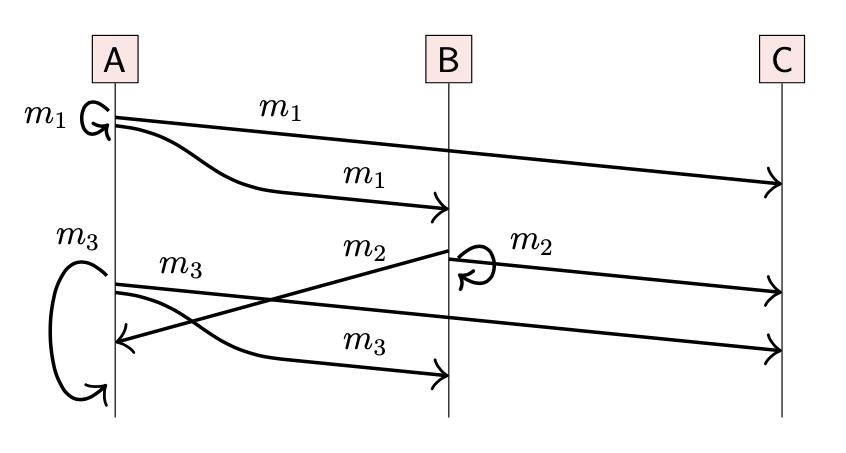
A:broadcast(m1) → broadcast(m3);B:broadcast(m1) → broadcast(m2);同时 broadcast(m3) || broadcast(m2),则节点 C 可以按照 (m1, m2, m3) 的顺序接收,也可以按照 (m1, m3,m2) 的顺序接收,这两个情况都与因果关系保持一致
4-2-3 Total order broadcast
Total order broadcast(全序广播)也被称为原子广播(atomic broadcast)。
FIFO broadcast 与 Causal broadcast 允许不同的节点按照不同的顺序接收消息,与之不同的是,Total order broadcast 加强了不同节点间的一致性,保证所有节点都按照相同的顺序接收消息。
接收的顺序没有准确定义,只要所有节点的顺序相同即可
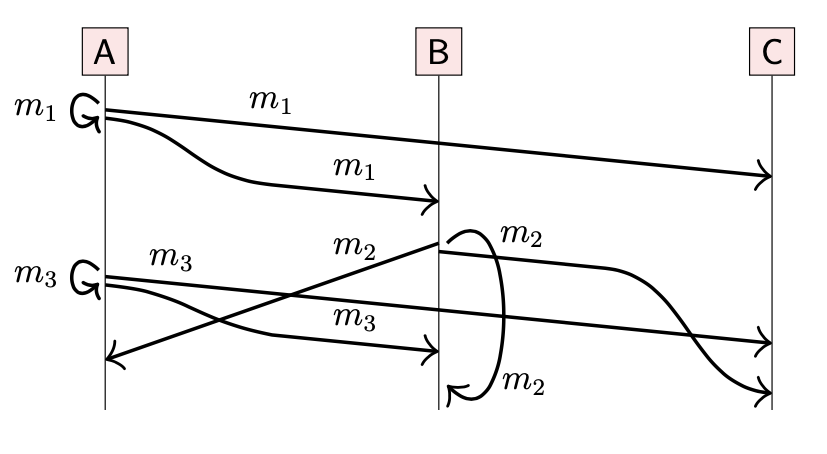
所有的节点都按照相同的顺序接收消息:(m1, m2, m3)
所有的节点都按照相同的顺序接收消息:(m1, m3, m2)
只要所有节点能够对消息顺序达成一致,上述两种顺序都是有效的。
与 Causal 广播一样,节点可能需要 hold back 消息直到该消息之前的消息都被接收。例如:节点 C 可能会按照任意的顺序收到 m2, m3,如果算法已经确定 m3 应该在 m2 之前收到,但是节点先收到了 m2,那么就会 hold back m2 直到收到 m3。
另外,在 FIFO broadcast 与 Causal broadcast 中,当一个节点广播了一条消息,那么它可以将该消息立即发送给自己,并不需要与其他节点通信。但是在 Total broadcast 中需要与其他节点通信以确定发送顺序:在第一个场景中,由于 m2 需要在 m3 前收到,因此节点 A 需要从 B 收到 m2 之后才能将 m3 发送给自己。
4-2-4 FIFO-total order broadcast
FIFO-total order broadcast 与 total order broadcast 类似,但是额外再加上 FIFO 的要求:同一个节点广播的消息需要按照发送的顺序送达。
在 Total order broadcast 中的两个例子实际上满足 FIFO-total order broadcast 要求,因为 m1 总是在 m3 前被接收。
4-2-5 Summary
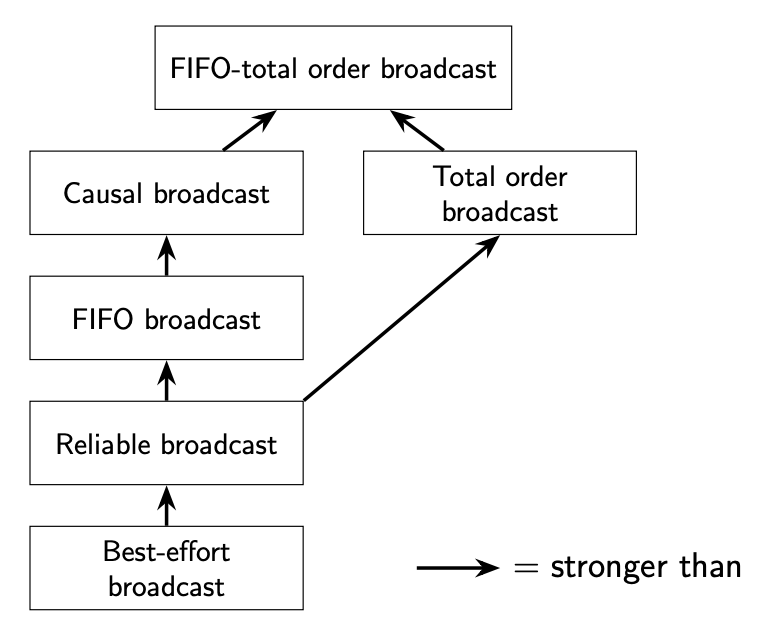
上述不同广播协议之间的层次关系如下:
FIFO-total order broadcast 协议要比 Causal broadcast 更严格:每个有效的 FIFO-total order broadcast 协议都是有效的 Causal broadcast 协议(反过来并不是)。
4-3 Broadcast algorithms
接下来将会讨论实现广播协议的算法。整体来说,涉及两个步骤:
- 确保每个节点都能收到每条消息:通过重发丢失的消息,使得广播协议变得可靠(reliable)
- 将消息按序送达:在可靠的广播协议之上使得消息有序送达
4-3-1 Deliver message reliably
广播算法实现的一次尝试:当一个节点想要广播一条消息时,它会通过可靠的网络连接(消息丢失后会重试)将消息分别发送给其他节点。然而,在消息重发之前,发送者节点可能已经崩溃。这种情况下,会存在节点永远不会收到消息。
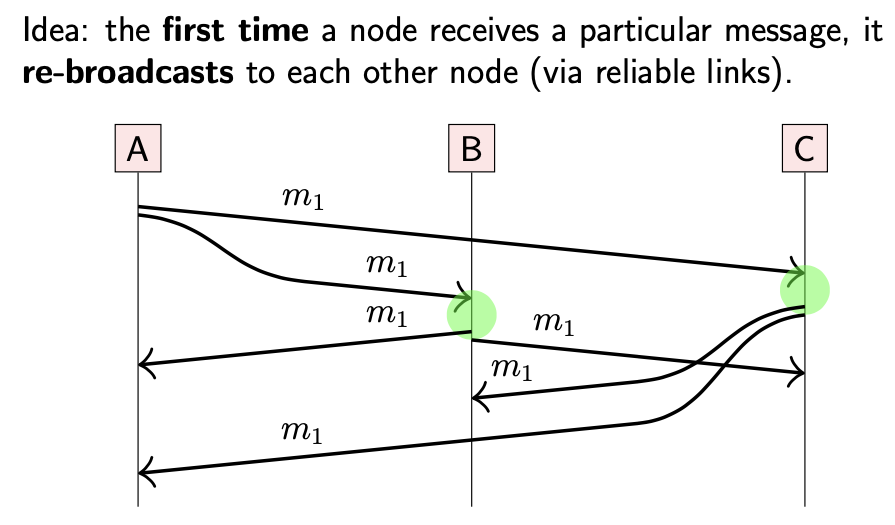
为了提高可用性,可以寻求其他节点的帮助:
- 当一个节点第一次收到某条特定的消息时,会将其转发到其他节点
这种方式被称为:Eager reliable broadcast。该算法能够保证,当一些节点崩溃后,剩余的所有非故障(non-faulty)节点都能收到每条消息。但是一个明显的缺点是,该算法效率很低:在没有故障节点的情况下,每条消息都会被发送 O(n^2) 次(假设系统中有 n 个节点),同时每个节点对于每条消息会收到 n-1 次;导致大量的网络冗余。
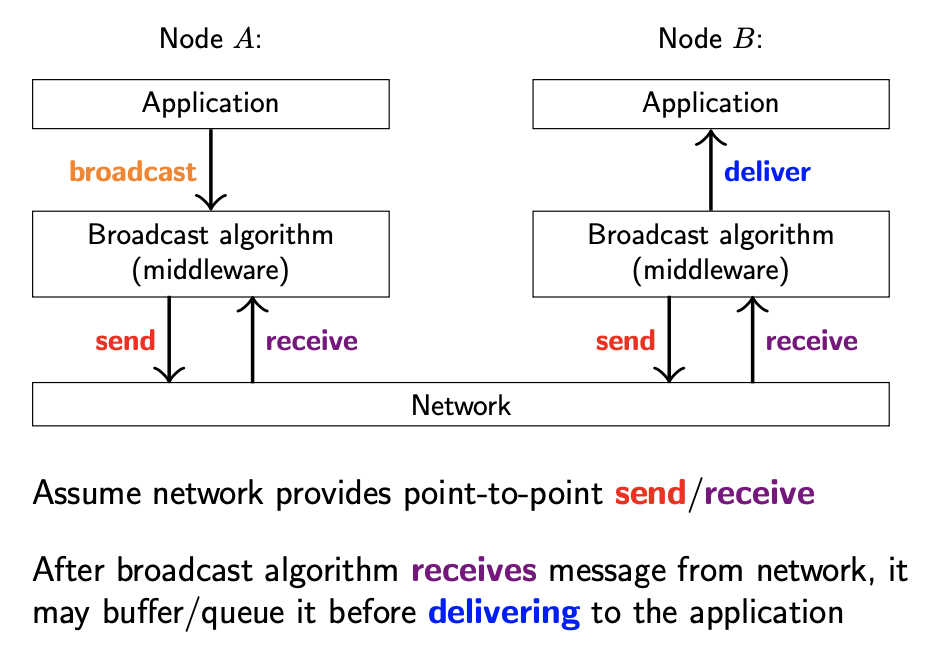
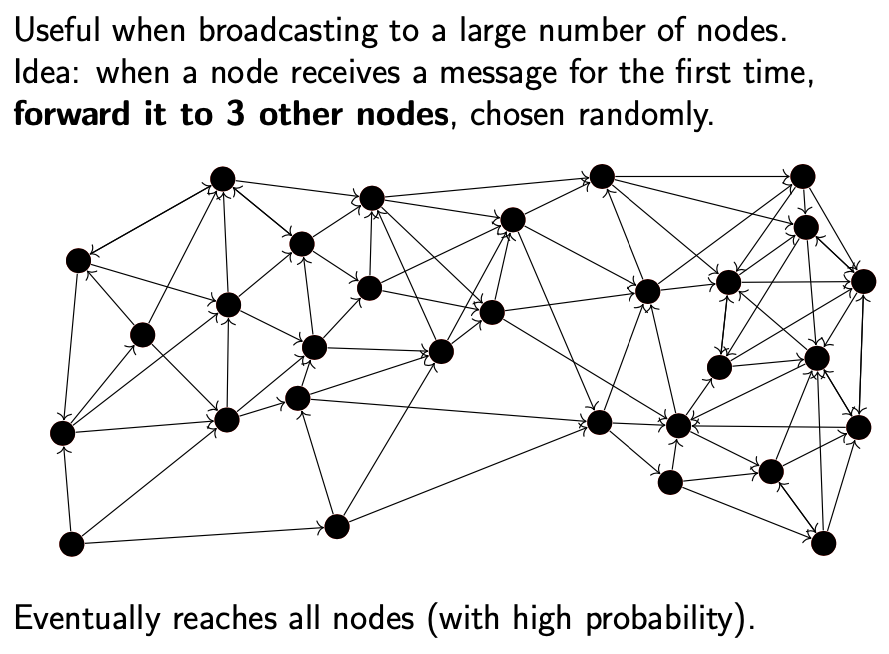
该算法发展了许多变体,从容错,所有节点收到消息的时间,使用的网络带宽等多个角度进行优化。其中一个比较常见的广播算法族是 Gossip protocols,也被称为 Epidemic protocols。基本流程为:
- 当准备广播消息时,节点将该消息发送给随机选择的,少量,固定数目的节点.
- 当节点首次收到该消息时,会将该消息转发给固定数目的,随机选择的节点.
这种传播方式类似于流言,传染病在人群中传播的方式
Gossip 协议并不严格保证每条消息都会被所有节点收到:在每次随机选择时,可能有些节点总是被遗漏。然而,如果算法参数比较合理,那么这种可能性就会很低。
Gossip 协议保证广播效率的同时,兼顾了消息丢失,节点崩溃的情况
通过 Eager reliable broadcast 或 Gossip 协议,我们已经保证广播的可靠性(reliable),之后需要讨论在其之上实现具体的广播算法:FIFO, Causal, Total order broadcast。
4-3-2 FIFO broadcast algorithm

每个节点都的本地状态信息由以下组成:
- sendSeq:计算当前节点广播消息的数量(每个消息都会标识该序列号)
- delivered:当前节点从其他节点收到消息数目的向量:<0, 0, . . . , 0>,每个元素对应一个节点
- buffer:缓冲区,用于 hold back 接收的消息,直到该消息可以传递给应用进程(如等到之前的消息全部接收到)
每个被广播的消息有以下标识:
- i:发送者节点 Ni 的标识
- sendSeq:当前消息的序列号(由当前节点计算已经发送的消息数量)
FIFO 算法检查每个发送方消息的序列号,如果与预期序列号匹配,则增加预期编号,确保来自特定发送方的消息有序传递给应用进程。
4-3-3 Causal broadcast algorithm

Causal 广播算法与 FIFO 算法类似,不过在每条广播消息上并不携带消息的序列号,而是序列号向量。该算法有时也被称为向量时钟(vector clocks)算法,不过它们之间有很大不同:向量时钟算法中的向量元素计算发生在每个节点上的事件数量,而该算法中向量元素由于计算从不同节点收到的消息数量。
每个节点的本地状态仍然由:sendSeq, delivered, buffer 组成。
当节点广播消息时,附带的信息有:
- i:发送者节点 Ni 的标识
- deps:表明该消息因果依赖性的向量
deps 向量以 delivered 进行初始化:delivered 是当前节点从其他节点收到消息数目的向量;deps 在本地发送的所有消息必须按因果顺序出现在该广播消息之前。初始化之后,将 deps 向量中对应该节点的元素更新为 sendSeq:确保此节点广播的每条消息都因果依赖同一节点广播的上一条消息。
4-3-4 (FIFO-)Total order broadcast algorithms

Total order (FIFO-total order) 广播算法相对更复杂。如上图所示有两种方式:
- 指定主节点的方式
- 通过使用 Lamport 时间戳的无主节点方式
不过这两种方法都不支持容错:单节点崩溃会导致其他节点都不能发送消息。
5-Replication
Replication 是指在多个节点上维护相同数据的副本,每个节点被称为副本(replica)。复制是许多分布式数据库,文件系统及其他存储系统中的标准功能。同时,也是实现容错(fault tolerance)的主要机制之一:如果一个副本故障,可以继续访问其他副本。
5-1 Manipulating remote state
如果数据没有发生变化,那么复制操作比较容易,因为只需要一次数据复制就行。因此,复制的主要问题是管理变更数据。在进一步深入复制流程的细节前,先探讨下在分布式系统中,数据是如何变更的。
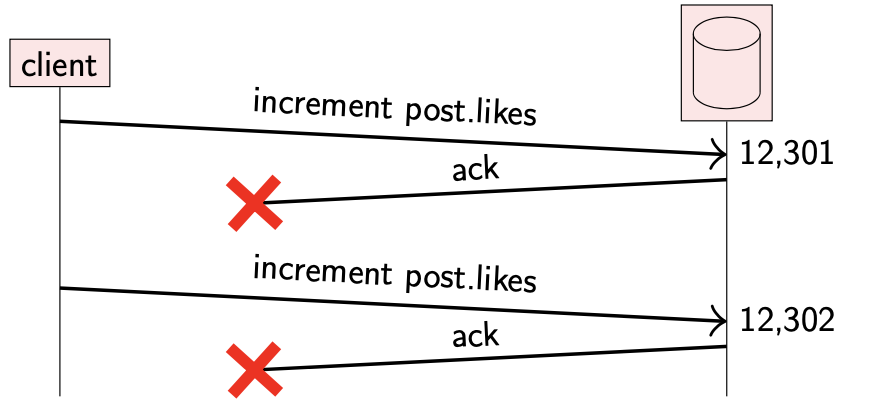
考虑这样一个场景,假设用户对某条推文感兴趣,因此点了 “like” 操作;twitter 会把喜欢这条推文的人存储在数据库中,以便展示给当前用户及其他用户。
我们把存储在数据库中的数据看作状态(state)。由于网络问题,更新数据库的请求可能会丢失,或者更新成功后的确认操作也会丢失。通常我们通过重试请求来提高可靠性,但是如果重试操作处理不当,该请求可能会被多次处理,导致数据库中的状态异常。
防止更新多次生效的一种方法是对请求去重(deduplicate requests)。然而在 crash-recovery 系统模型中,需要将请求(或者请求的元数据)存储在稳定的存储介质中,这样即使在节点崩溃后也能检测出重复的请求。
请求去重的一种替代方式是请求幂等(idempotent)。
-
递增操作不是幂等的,但是向集合中添加一个元素是幂等的。因此,如果需要计数器操作,最好维护元素集合,并从集合导出计数值。
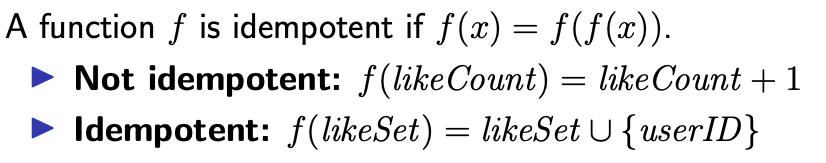
幂等更新操作可以安全重试:执行多次与执行一次的效果一样。幂等使得更新操作具有 exactly once 语义:更新操作可能执行多次,但是影响与正好执行一次是相同的。
对于重试操作的语义有以下几种:
-
At most once
发送请求,但是并不会重试,更新也会并不会执行
-
At least once
收到确认前一直重试,可能会多次更新
-
Exactly once
重试 + 幂等;或者去重
在分布式系统中,幂等是非常有用的特性:RPC 操作不可避免地要进行重试。
然而,当多个更新操作在处理时,幂等具有明显的局限性。下面是几个示例:
-
添加后删除
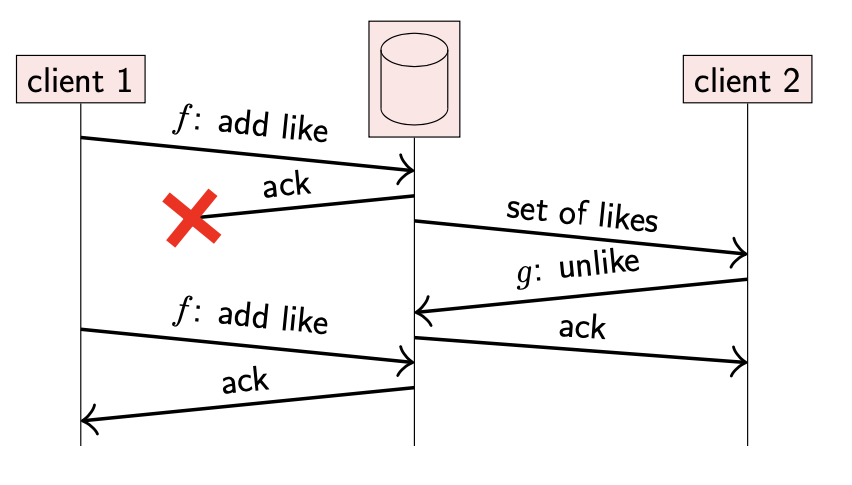
- client 1 将一个 userId A 添加到用户集合中,数据库添加成功但是响应丢失。
- client 2 从数据库中读取该集合,其中包含了 client 1 刚刚添加的 userId A。
- client 2 请求数据库将 userId A 从集合中移除,数据库操作成功并返回。
- 此时,client 1 并不知道 client 2 的删除操作,仍在重试刚才的添加请求;该重试操作重新将 userId A 添加到集合中。
最后的结果不符合预期,因为 client 2 是在 client 1 更新之后的操作,符合因果关系;我们希望 userId A 最后被移除。在这种情况下,幂等操作并不能实现安全重试。
-
另一种形式的添加后删除
假设有两个数据副本 A,B。
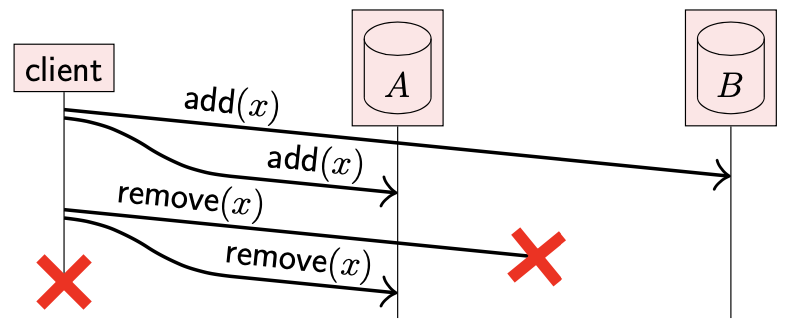
- client 将数据 x 添加到两个副本中,添加成功
- client 之后尝试将 x 从这两个副本中删除,但是对副本 B 的删除请求丢失了
- client 在重试前崩溃了
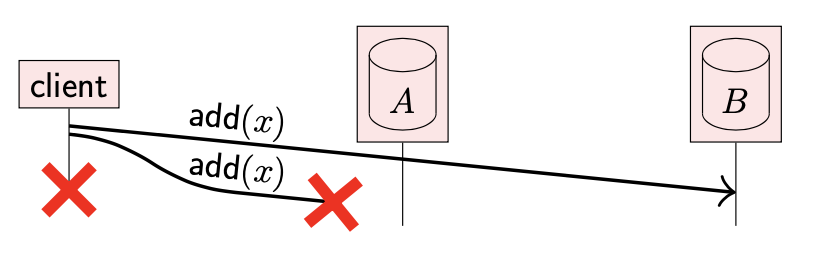
- client 尝试将数据 x 添加到两个副本中,但是向副本 A 添加数据的请求丢失了
- client 在重试前崩溃了
虽然这两个场景的预期效果不一样:第一个场景中,想要从两个副本中删除数据;第二个场景中想要向两个副本中添加数据。但是最后结果都一样:x 存在副本 B 中,但是在副本 A 中不存在。
当两个部分协调其不一致的状态时,我们希望它们最后都处于 client 期望的状态。然而,如果副本间无法区分这两种情况,是无法做到的。
为了解决这种问题,我们需要做两件事:
- 将逻辑时间戳附在每次的更新操作上,并将时间戳作为数据更新的一部分存储在数据库中
-
当想要将数据记录从数据库中删除时,我们并不真正删除该数据,而是看作一种特殊类型的更新操作,将其标记为删除,称为墓碑(tombstone)
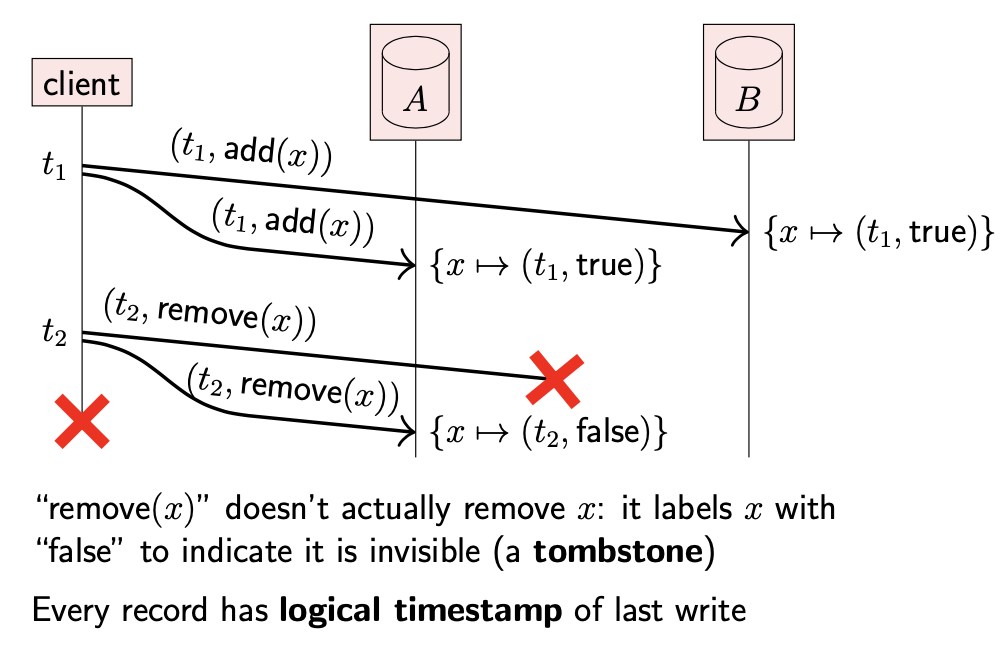
在许多分布式系统中,副本运行一个协议来检测 & 协调副本间的差异(被称为反熵,anti-entropy),最终所有副本都能保证数据的一致性。
- 由于墓碑,可以区分已经删除的记录和还未创建的记录
-
由于时间戳,可以区分哪个版本的记录更新,哪个版本更旧;从而可以丢弃旧的版本,保留新的版本

在第一种添加后删除的场景中,重试操作的时间戳与之前请求的时间戳相同,因此重试操作并不会覆盖 client 2 的更新:因为 client 2 的操作时间戳更大,与之前的请求具有因果性
在每次更新操作中附带时间戳的方式对处理并发更新也很有用。如下所示:
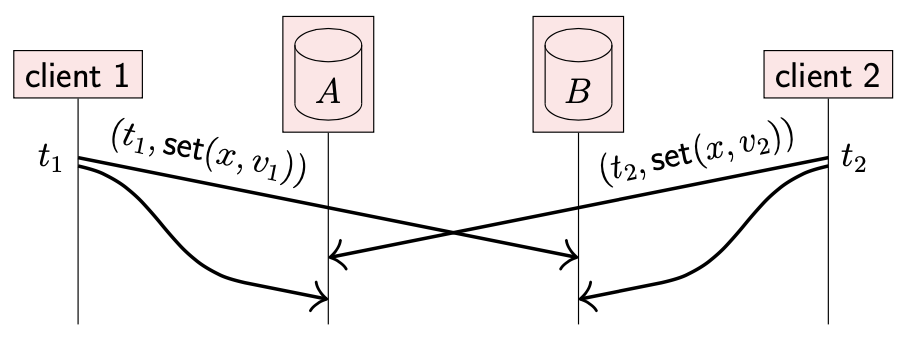
- client 1 想要将 x 的值更新为 v1(携带时间戳 t1)
- 与此同时,client 2 想要将 x 的值更新为 v2(携带时间戳 t2)
- 副本 A 首先收到 v2 ,之后收到 v1;副本 B 收到的顺序相反
为了确保两个副本最终状态相同,我们并不依赖它们收到更新请求的顺序,而是根据时间戳的顺序。
不过,该方法的具体细节依赖采用时间戳的类型。
-
Last writer wins (LWW)
如果使用的是 Lamport 时间戳(能够提供全序关系),并发更新操作就可以进行排序(具体取决于时间戳比较的方式)。这种情况下,我们可以使用 Last writer wins (LWW) 语义:拥有最大时间戳的更新操作有效,其他对同一 key 并发更新且时间戳较小的操作被丢弃。
该方法执行比较简单,但是如果多个更新操作并发执行,会导致数据丢失。不过,这一点取决于具体的应用程序:对有些系统来说,丢弃并发更新是允许的。
-
Multi-value register
当不能丢弃并发更新时,我们需要能够检测并发更新是在什么时候发生的,此时可以使用矢量时钟。矢量时钟具有偏序关系(帮助判断 Happen-before 关系),可以帮助我们判断新值是否应该覆盖旧值(当旧值 Happen-before 新值时可以覆盖)。同时,当多个更新操作并发时,我们可以保留所有并发更新的值。应用程序可以之后将冲突的值合并成一个值。
这些并发写入的值被称为 conflicts 或者 siblings
向量时钟的一个缺点是成本较高:每个 client 是向量时钟的一个元素:<n1,n2,n3..ni>,如果一个系统中有很多 client,那么向量时钟就会变得很长,可能要比数据本身所占的空间要大。
Dynamo 系统使用的是这种方式,不过对向量时钟进行了优化,确保不会太长。也存在其他的优化方式。

5-2 Quorums
正如之前所说,复制可以提高系统的可靠性(reliability):当一个副本不可用时,剩下的副本可以继续处理请求。导致副本不可用的原因有:
- 节点故障:崩溃或者硬件故障
- 网络分区:无法通过网络访问节点
- 有计划地维护:重启节点或进行服务升级
不过,如何执行复制操作对系统可靠性有很大影响。如果没有容错机制,那么拥有多个副本可能使得系统可靠性更差(worse):部分越多,任意副本在任意时间出现故障的可能性越大。如果系统在一些副本故障的情况下仍能继续工作,那么可靠性提高:所有副本同时出现故障的概率远远低于单个副本出现故障的概率。
在继续讨论如何在复制中实现容错前,先看下一个示例:
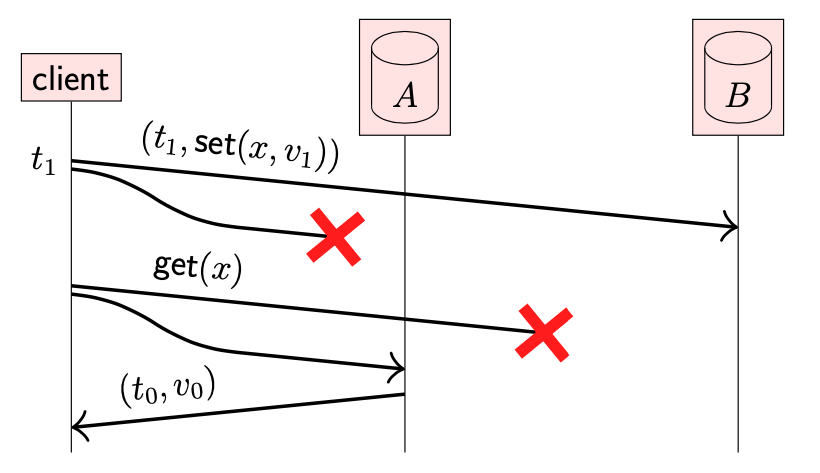
- 有两个副本 A,B,对于 x 的值都初始化为 v0(关联时间戳为 t0)
- client 尝试将 x 的值更新为 v1(时间戳 t1);更新操作在副本 B 上操作成功,但是由于副本 A 暂时不可用,导致更新失败
- 之后,client 尝试读取其写入的值;读取操作在副本 A 上成功,但是在副本 B 上失败
- 结果,返回值并不是 client 之前的写入值 v1,而是初始值 v0
上述场景是不符合预期的,因为从 client 的视角来看它写入的值似乎已经丢失了。
假设你在社交网络上刚刚发布一条动态,之后刷新页面,但是并没有看到刚刚的发布
为了解决这类问题,许多系统需要支持写后读一致性(Read-after- write consistency),也被称为 Read-your-writes consistency。这样能够取保,client 更新值之后,同一个 client 能够读取刚刚写入的值。
严格来说,写后读一致性并不能确保 client 读取其刚刚写入的值,因为其他 client 可能同时并发覆盖了该值。因此,写后读一致性能够保证读取最后写入的值或者之后的值。
在上面示例中,我们可以通过确保始终写入两个副本或者从两个副本中读来实现写后读一致性。但是,这意味着读/写操作并不具备容错性:如果一个副本不可用,那么需要两个副本都响应的读取/写入操作就无法完成。
我们可以通过使用三个副本来解决这个问题:把每个读写请求发送给全部三个副本,只要收到的响应数 ≥2,就可以认为请求成功。
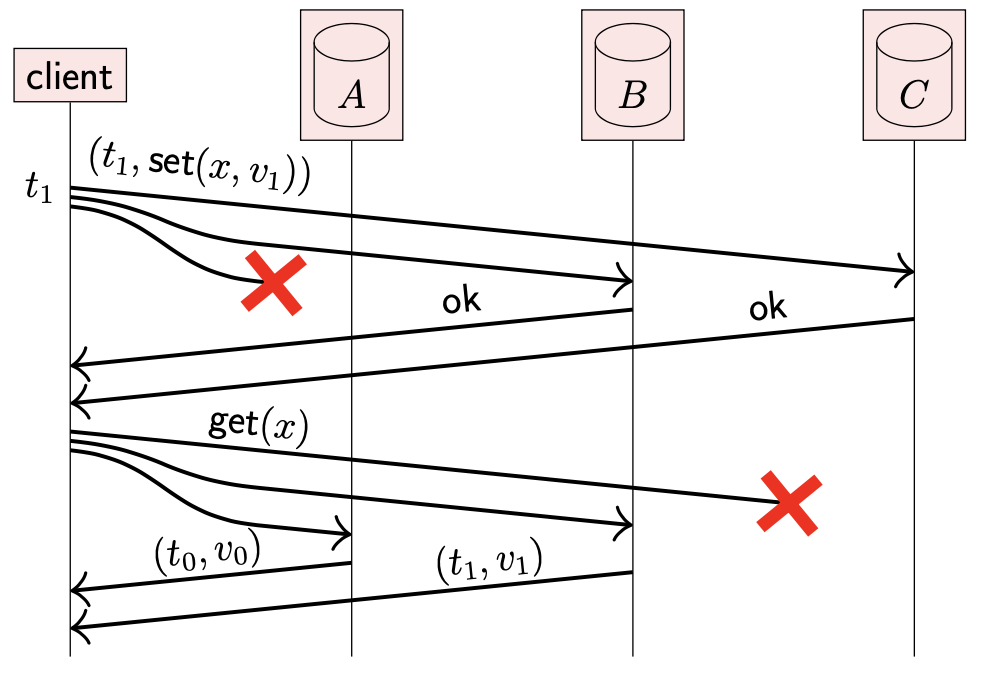
- 更新请求在副本 B,C 上执行成功;读取请求在副本 A,B 上执行成功
- 读写请求在 2/3 节点上执行成功;因此可以保证读取的响应至少有一个来自最新写入的副本(副本 B);通过比较响应的时间戳就可以判断最新数据
在该示例中,响应写请求的副本集合 {B, C} 称为 write quorum;响应读请求的副本集合 {A, B} 被称为 read quorum。
Quorum 是请求响应的最小节点集合。为了确保写后读一致性,write quorum 与 read quorum 必须存在非空交集。换句话说,read quorum 中至少包含一个已经确认写入的节点。
在分布式系统中,通常选择 Majority quorum:严格包含一半以上节点的集合。假设系统中有 {A, B, C} 节点集合,那么 majority quorum 为 {A, B},{A, C},{B, C}。一般来说,对于拥有奇数节点的系统,(n+1)/2 的数目集合即为 majority quorum;对于拥有偶数节点的系统,n/2+1 的数目集合即为 majority quorum。
majority quorum 的特性为:任何两个 majority quorum 至少存在一个共同节点
除了 majority quorum,其他形式的 quorum 也是可能的。
5-2-1 Read and write quorum
write quorum:写入操作需要确认的副本数。read quorum:读取操作需要确认的副本数。
如果 write quorum 为 w,read quorum 为 r,并且 r + w > n,那么读取操作能够获取到最新写入的值:读写 quorum 至少存在一个共同节点。
对于 write quorum 为 w 的系统,可以容忍最多 n-w 个副本不可用;对于 read quorum为 r 的系统,可以最多容忍 n-r 个副本不可用。对于 majority quorum 系统,3 个副本可以容忍 1 个不可用;5 个副本可以容忍 2 个不可用,以此类推。
5-2-2 Read repair
在这种 quorum 机制的复制系统中,任意时刻都可能存在部分副本缺少更新。在上面的例子中,副本 A 没有将 x 更新为 v1。为了使副本间保持一致,可以使用之前讨论的反熵机制(anti-entropy)。
另一种方式是 Client 帮助传播更新。
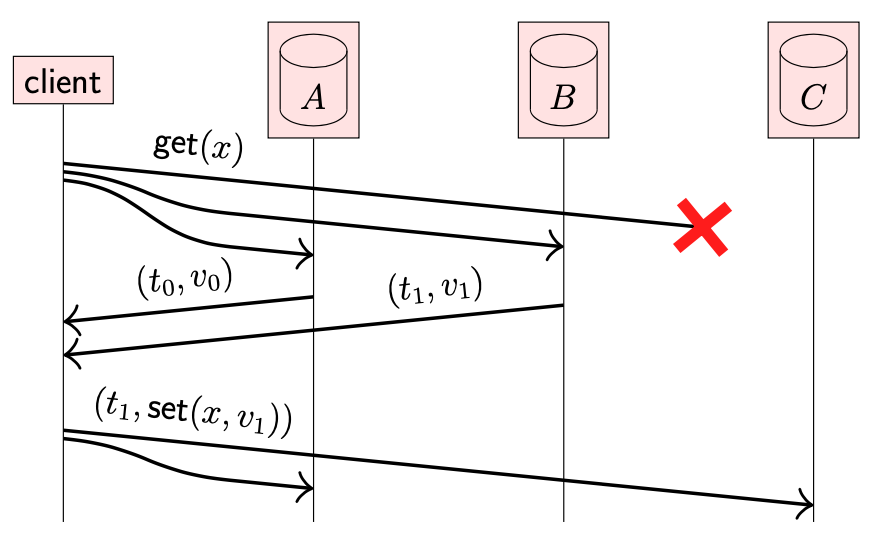
- client 从副本 B 读取到 (t1, v1);从副本 A 中读取到 (t0, v0);副本 C 未响应
- 由于 client 知道 (t1, v1) 为最新值,且需要传播到副本 A,所以可以向 A 发送更新请求:因为这不是新的更新操作而是之前更新的重试
- client 也许会将更新请求发送给 C,即使其不知道 C 是否需要再次更新:如果 C 已经执行过这次更新,也仅仅是浪费一小部分带宽
上述的流程被称为读修复(read repair)。client 可以对任意读请求进行读修复操作,而不管之前更新操作是否是当前 client 执行的。
5-2-3 Summary
使用 quorum 复制模型的数据库通常被称为Dynamo风格,以 Amazon Dynamo 数据库命名。
5-3 Replication using broadcast
5.2 节介绍的 quorum 复制方法使用的是 best-effort 广播:client 将每个读写请求广播到所有副本,但是使用的协议并不是可靠的(请求可能会丢失),同时不能提供顺序保证。
另一种复制方法使用的是 第 4 节介绍的广播协议。首先讨论最可靠的广播协议:FIFO-total order broadcast。
使用 FIFO-total order broadcast 比较容易构造一个复制系统,通过将每个更新请求广播到所有副本,副本根据收到的每条消息更新自身状态。这种方式被称为 State Machine Replication(SMR):副本充当状态机,消息传递是其输入。
我们只要求更新逻辑是稳定的(deterministic):任何两个处于相同状态并拥有相同输入的副本最终一定处于相同的下一个状态。即使是错误也需要是确定的:如果一个更新操作在一个副本上成功的,但是在另一个副本上失败,那么这两个副本就会变得不一致。

状态机复制的一个优点是:只要执行逻辑是稳定的,那么从一个状态转移到下一个状态的执行逻辑可以是任意复杂度。例如,可以执行具有任意业务逻辑的数据库事务,该业务逻辑可能依赖广播消息和数据库当前状态。一些分布式数据库以这种方式执行复制,每个副本独立执行相同且稳定的事务代码,被称为主动复制(active replication)。
该原理还被用于区块链,加密货币,分布式分类账:区块链中的“区块链”只不过是 FIFO-total order 协议传递的消息序列,每个副本确定性地执行这些块中描述的事务,以确定分类账的状态
状态机复制的缺点即为全序广播的限制。
- 正如之前讨论 FIFO-total order 广播,当一个节点想要通过全序广播协议广播一条消息时,该节点不能立即将消息发送给自己。因此,当一个副本想要更新自身状态时,不能立即更新;必须经历广播过程,与其他节点协调,并等待其他节点的更新响应
- 同时,状态机复制的容错性取决于底层依赖的全序广播协议的容错性
尽管存在上述限制,基于全序广播的复制仍被广泛使用。
5-3-1 Database leader replica
之前说过,实现 FIFO-total order 广播协议的一个方法是:
- 指定一个节点作为 leader
- 通过 leader 路由所有的广播消息
这个原理也广泛用于数据库复制。许多数据库系统指定一个副本作为 leader, primary 或者 master,任何对数据库更新的事务都必须在 leader 副本上执行。
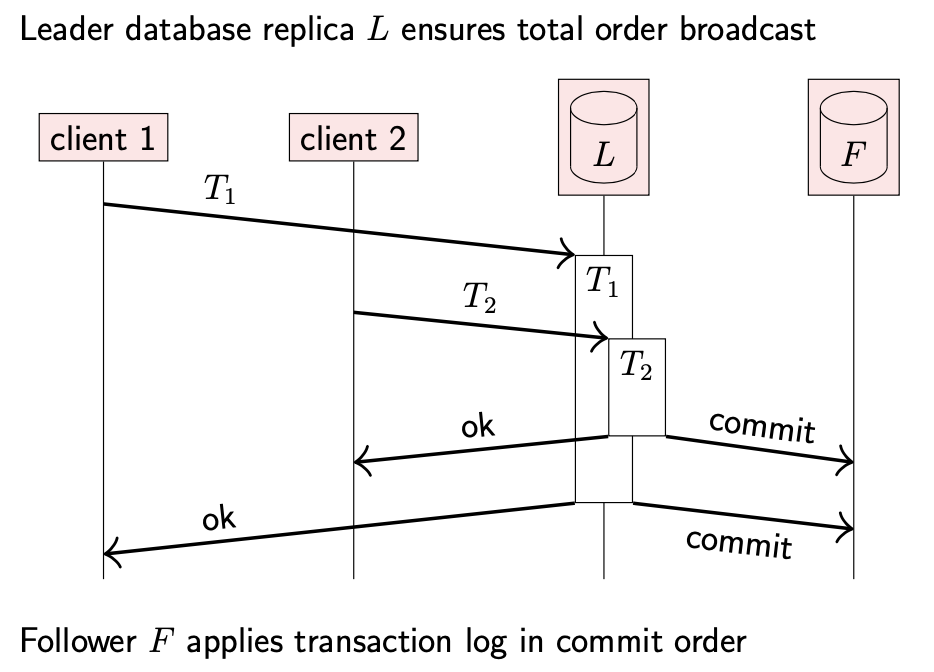
如上图所示,leader 可能并发执行多个事务,不过会按照全局关系提交(commit)这些事务。当事务提交时,leader 副本将事务产生的数据变更广播给所有 follower 副本,之后 follower 副本将这些变更按照提交顺序应用到本地。这种方法被称为 passive replication 或者 primary-backup replication。可以看到这种方式相当于事务提交记录的全序广播。
除了 FIFO-total order broadcast 协议,其他广播模型也可以用于复制,不过需要更加小心以确保副本间保持一致(仅仅确保更新逻辑是稳定的并不够)。

6-Consensus
在 5.3 节看到了全序关系广播(total order broadcast)对实现状态机复制非常有用。而其中一种实现全序关系广播的方式是:指定一个节点作为 leader,由 leader 路由所有的消息。leader 只需要通过 FIFO broadcast 进行消息分发,足以确保所有的节点以相同的顺序收到相同的消息序列。
然而,这种方法最大的问题是,leader 单点故障:如果 leader 不可用,整个系统就会不可用。一种解决方案是进行人工干预:当 leder 不可用时,通知管理员重新配置新的 leader 节点。这个过程被为故障转移(failover),该方式常用于许多数据库系统中。
在提前计划 leader 不可用的情况下,故障转移能够运行良好,如需要重启更新 leader 节点。然而对于突然或意料之外的 leader 不可用的情况(如节点崩溃,硬件故障,网络故障等),由于人为介入的速度有限,故障转移会受到影响。
管理员可能需要好几分钟才能响应,那么在此期间服务是不可用的
由此引出了一个新的问题,当旧 leader 不可用的时候,能否自动选择另一个节点作为新 leader?而这就是共识算法(consensus)需要做的。
6-1 Introduction to consensus
对共识问题的简单描述:几个节点想要对某个值达成一致(aggreement)。
一个或者多个节点可能会提议(porpose)一个值,共识算法将决定(decide)其中一个值。共识算法保证决定的值是从提议的值中选取,所有节点都决定相同的值(除了故障节点)。并且最终决定的值是不变的(当节点决定了某个值,就不会改变)。
需要说明,共识(consensus)与全序广播(total order broadcast)是等价的:
- 为了将全序广播转化为共识,想要提议 value 的节点需要将其广播,全序广播传递的第一条消息被认为是决定值
- 为了将共识转化为全序广播,使用共识协议的一个单独实例来决定发送的消息。想要广播消息的节点会在一轮共识中提议该消息。共识算法之后确保所有节点对将要发送的消息序列达成一致
两个最著名的共识算法:Paxos & Raft。最初的 Paxos 只会对单个值达成共识。Multi-Paxos 是 Paxos 的推广,提供 FIFO-total order 广播。Raft 默认提供 FIFO-total order 广播。
6-1-1 Consensus system models
共识算法的关键取决于系统模型。Paxos & Raft 假设系统模型为:
- 网络:fair-loss link
- 节点行为:crash-recovery
- 同步模型:partial synchrony
对于网络及节点行为的假设可以削弱为为拜占庭模型,此类算法用于区块链中。然而,拜占庭容错共识算法比非拜占庭算法复杂得多,效率更低。因此我们更专注于 fair-loss link & crash-recovery 算法,这些算法在实际环境中很有用(比如受信网络的数据中心)。
另一方面,同步模型的假设不能从 partial synchrony 削弱为 asynchrony。因为共识算法需要故障检测器(failure detector),而故障检测器需要本地时钟来触发超时。如果没有时钟,那么确定性共识算法可能不会终止。事实上已经证明,任何确定性异步(asynchronous)算法都不能解决保证终止的共识问题。这一事实被称为 FLP Result,该理论是分布式系统中最重要的理论之一。
There is no deterministic consensus algorithm that is guaranteed to terminate in an asynchronous crash-stop system model.
6-1-2 Leader election
大多数共识算法的核心是选举(elect)流程:当现存 leader 节点不可用时,需要选举一个新的 leader。不同共识算法之间的选举细节有所不同,我们将重点讨论 Raft 算法采取的方法(对其他算法也有借鉴意义)。
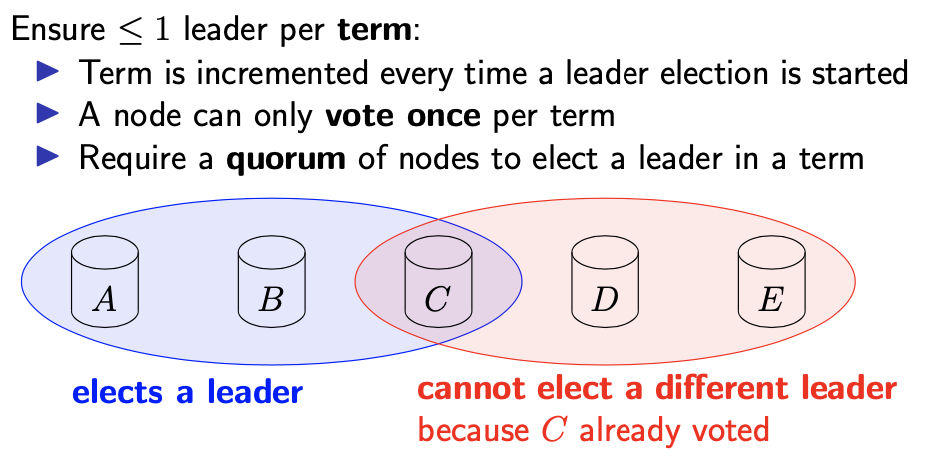
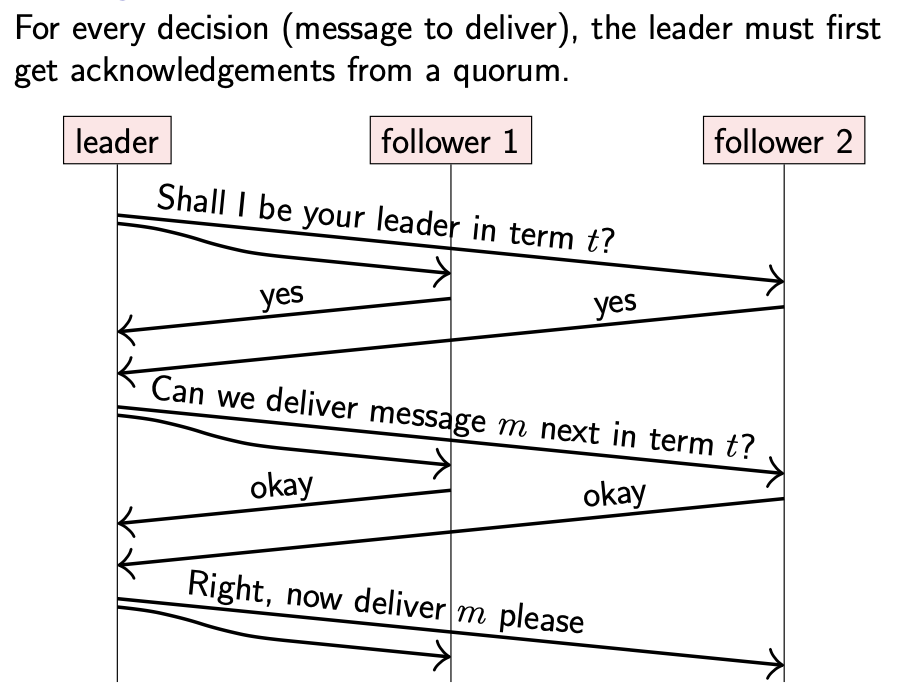
当其他节点检测到 leader 不可用时(通常是因为持续一段时间没有从 leader 收到任何消息),就会发起 leader 选举流程。其中一个节点成为候选人(candicate),并要求其他节点投票是否接受该候选人作为新的 leader。如果法定数目(quorum)的节点投票给该候选人,那么其就会成为新的 leader。
如果使用的是 majority quorum,只要大多数节点可用并且相互间可以通信,投票就会成功。
如果同时存在多个 leader,不同的 leader 做的决定可能不一样,会导致违反全序广播的安全属性(被称为 split brain)。因此,我们期望在进行 leader 选举时,任何时候都只会有一个 leader。在 Raft 算法中,“任何时候”的概念用任期(term)来表述:term 是一个整数,在开始进行 leader 选举时递增。当 leader 当选时,投票算法能够保证在特定任期(term)内只会有一个 leader。
不同任期内有不同的 leader
6-1-3 Can we guarantee there is only one leader?
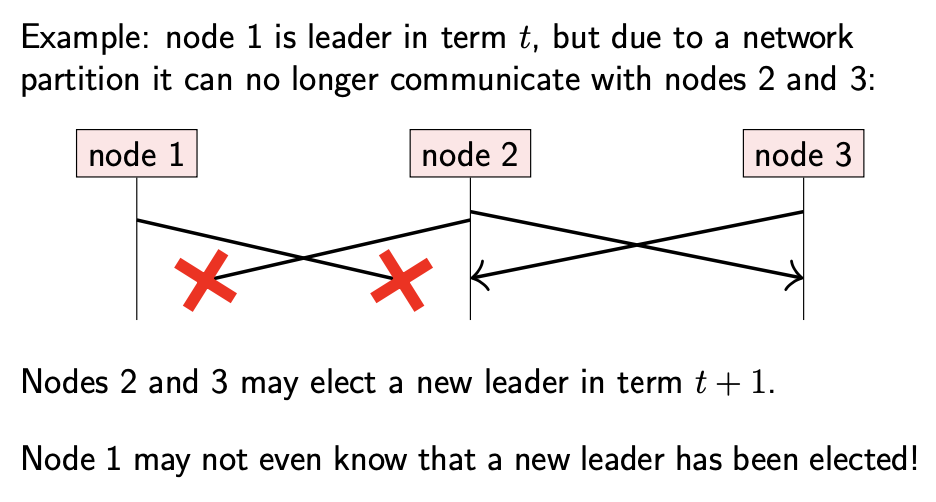
我们之前讨论过,在 partially synchronous 系统中,基于超时的故障检测器可能不准确:比如由于网络延迟增加,可能会将一个功能正常的节点标识为故障。考虑下面一个场景:
- node 1 是任期 t 内的 leader;node 1 与 node 2, 3 之间的网络暂时中断
- node 2, 3 可能会检测到 node 1 故障,并在任期 t+1 内选举新的 leader;虽然 node 1 仍在正常运行
- node 1 可能并没有注意到网络故障,也不知道已经选举出新 leader
- 因此,有两个节点都认为自己是 leader
由于这个原因,即使一个节点已经当选 leader,也需要谨慎操作。因为在任何时候,系统内都可能包含另一个更大任期(term)并且其从未感知到的 leader。如果任何操作只需要 leader 同意,那么就会变得不安全。相反,当 leader 想要决定下一条准备发送的消息时,必须再次请求其他节点以得到法定节点数(quorum)的确认。

- 在第一次往返中,由于其他两个节点的投票,左侧节点当选为 leader,任期为 t
- 在第二次往返中,leader 提议下一条将要发送的消息,这两个 follower 确认没有比任期 t 更大的 leader 存在
- 最后,leader 发送消息 m 并广播给 followers,以此来保证之间的一致
如果另一个新的 leader 当选,那么旧 leader 就可以通过第二次往返中的确认消息发现新 leader。因为至少有一个节点参与第二轮 leader 选举并投票给新 leader。因此,即使多个 leader 可能同时存在,旧 leader 将不可能再决定新的消息,从而确保算法的安全性。
6-2 The Raft consensus algorithm
原文在这部分详细介绍了 Raft 算法的实现,鉴于 Raft 论文更详细,因此不在此处讨论
7-Replica consistency
在上文我们已经了解到两种复制方式:1. 使用 read/write quorum;2. 通过全序广播实现状态机复制。我们期望副本对相同的数据保持一致,但是没有准确定义 “consistent” 的含义。
“consistency” 在不同的上下文中具有不同的含义:
- 在事务中,ACID 中的 C 代表一致性,即状态的属性:数据库处于一致或者不一致的状态是指,该状态满足或者违反了应用程序定义的某些不变量。
- 在复制上下文中,我们非正式地使用一致性来表示副本之间的关系:期望一个副本与另一个副本保持一致。
由于对一致性没有一个真正的定义,我们讨论的是各种一致性模型(consistency models)。之前介绍过一个一致性模型,read-after-write consistency:限制了同一节点写入同一项数据后的读取值。
7-1 Two-phase commit
首先讨论分布式事务(distributed transaction)的一致性问题:在多个节点上进行读写的事务操作。分布在这些节点上的数据可以是同一数据集的副本,也可以是一份数据集的不同子集;分布式事务对这两种情况都适用。
事务的关键性质是原子性(atomicity)。当一个事务跨越多个节点时,我们仍然期望整个事务具有原子性:要么所有节点必须提交事务并持久化更新操作,要么所有节点必须中止事务并丢弃或回滚其更新。因此,需要不同节点就事务是提交还是放弃达成一致(agreement)。
这里说的一致与第 6 节介绍共识所说的一致并不相同,尽管两者看起来都是达成某种协议。下图介绍两者的区别:

确保多个节点间实现原子提交最常见的算法是 Two-phase commit (2PC)。
也有个 three-phase commit protocol,不过其假设了不切实际的同步模型,因此不讨论
两阶段提交的流程如下:
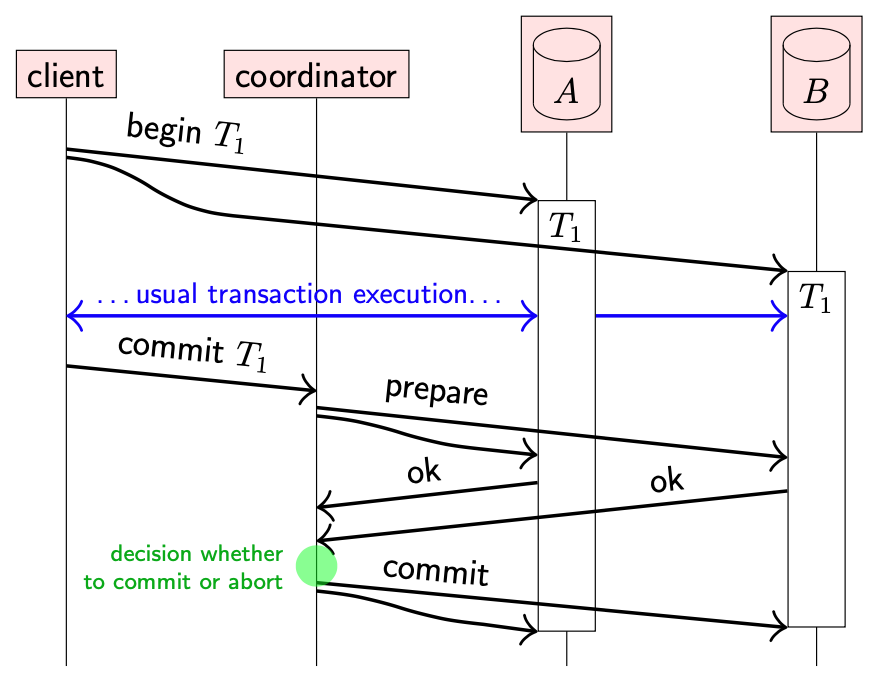
- 当使用两阶段提交时,client 首先在参与事务的每个副本上执行常规的单节点事务,并在这些事务中执行正常的读写操作
- 当 client 准备提交事务时,会向 transaction coordinator 发送提交请求:coordinator 是用于管理两阶段提交的节点(在某些系统中,coordinator 是 client 的一部分)
-
阶段一:coordinator 首先向参与事务的每个副本发送一个 prepare 消息;每个副本回复其能否提交事务
副本此时还没有真正提交事务,但是必须能够保证在阶段二收到 coordinator 的确定之后能够提交事务。这意味着,副本必须将事务的所有更新写入磁盘,并在回复 prepare 消息之前检查任何完整性约束,同时继续为事务保留任何锁。
- coordinator 收集响应,并决定是否真正提交事务。如果所有节点回复 ok,coordinator 决定提交事务。如果任意节点想要中止事务,或者任意节点在指定超时时间没有回复,那么 coordinator 决定中止事务。
- 阶段二:coordinator 将最终决定发送给所有副本,副本收到后按照指示提交或中止事务。如果决定要提交,每个副本都保证能够提交事务(之前的 prepare 请求奠定了基础)。如果决定中止,副本将回滚事务。
两阶段提交的问题是,coordinator 存在单点故障(single point of failure)。coordinator 可以将提交/中止事务的决定写入稳定存储中,以应对节点崩溃。但是可能会有很多事务在 coordintor 节点崩溃时,已经准备好单还没来得及提交或中止。任何不确定的事务只能等到 coordinator 恢复之后才能结束:参与事务的节点不能单方面决定提交还是中止事务,因为可能会导致与 coordinator & 其他节点间的不一致,从而违反原子性。
通过使用共识算法或者全序关系广播可以避免 coordinator 单点故障。下图展示了基于 Paxos Commit 实现两阶段提交容错机制:


核心思想是,每个参与事务的节点通过全序广播传播自己对于提交还是中止事务的投票。
如果节点 A 怀疑节点 B 已经故障(比如在超时时间内没有收到节点 B 的投票),那么节点 A 可能尝试代表 B 投中止票。这就引入了一个竞争条件:如果节点 B 因为延迟,可能会在 A 代表自己投票的同时,广播自己的提交票。
所有投票都会通过全序广播发送给每个节点,每个接受者独立计算投票。
7-2 Linearizability
原子提交协议是在出现故障时,保证多个副本间一致性的一种方法:确保所有事务参与者要么提交要么中止事务。然而,当多个节点并发读取 & 修改共享数据时,仅仅靠所有节点采取相同的提交或中止决定是不够的。
接下来介绍用于并发系统的一致性模型,被称为 Linearizability。当提到 linearizability 时,人们有时会说强一致性(strong consistency),不过强一致性的概念相当模糊,不准确。我们使用 linearizability,因为其具有准确的定义。Linearizability 的非正式定义如下:

Linearizability 的概念不仅在分布式系统中有用,并且在单机共享内存并发中也很有用。值得注意的是,在具有多个 CPU 的计算机上,内存访问默认不满足 linearizability。因为每个 CPU 都有自己的缓存,在一个 CPU 上的更新并不会立即反映在另一个 CPU 的缓存中。因此,单机也表现的有点像复制系统。
需要注意 Linearizability 与 Serializability 并不相同,虽然都意味着按照顺序排列。
- Serializability 意味着事务执行与某些串行顺序执行的效果相同,但是并没有定义顺序是什么
- Linearizability 定义了操作必须返回的值,并且取决于操作的并发性与相对顺序
系统可以同时提供 Linearizability & Serializability:这两者结合被称为 strict serializability 或 one-copy serializability。
Linearizability 的主要目的是保证节点能够获取系统的最新状态:不会访问到过期的数据。之前讨论的写后读一致性虽然也能保证读取最新的值,但是该一致性模型的读写操作发生在同一个节点;而 Linearizability 将其推广到不同节点同时进行的操作。
7-2-1 ABD: Making quorum reads/writes linearizable
从 client 的角度来看,每次操作都需要花费一些时间。假设操作的开始时间是应用程序发出请求的时刻,结束时间是操作结果返回到应用程序的时刻。在开始与结束之间,可能会发生各种网络通信操作。
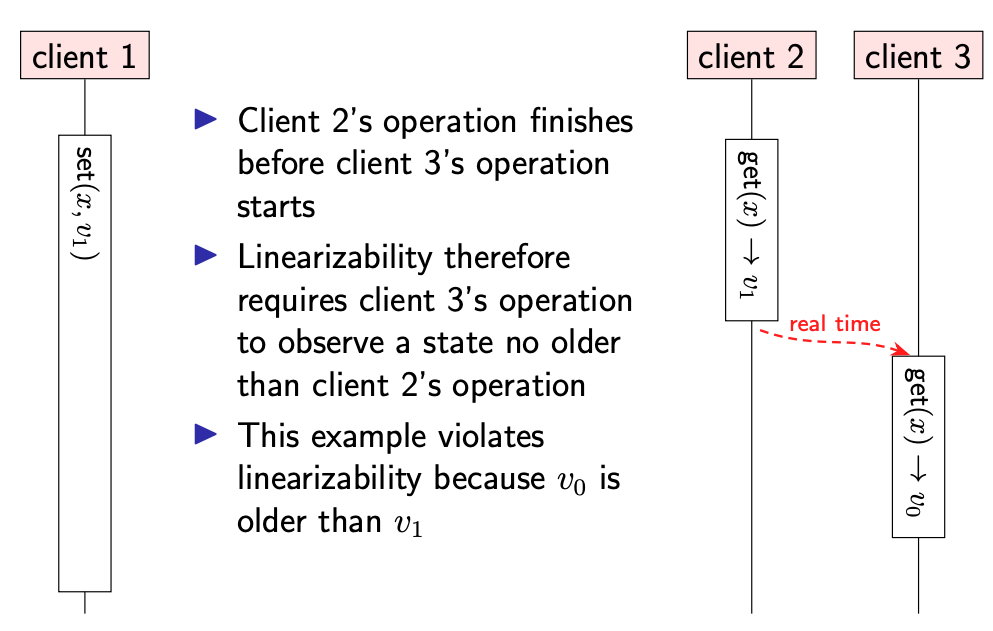
我们把 client 读写操作的时间段看作一个矩形,在矩形内记录下操作的影响:set(x,v) 表示将 x 更新为 v,get(x) → v 表示读取 x 的返回结果为 v。
Linearizability 不仅涉及 get 操作与前一个 set 操作的关系,还可以一个 get 操作与其他操作关联。下面是使用 quorum 进行读写操作,但并不满足 Linearizability 的示例。
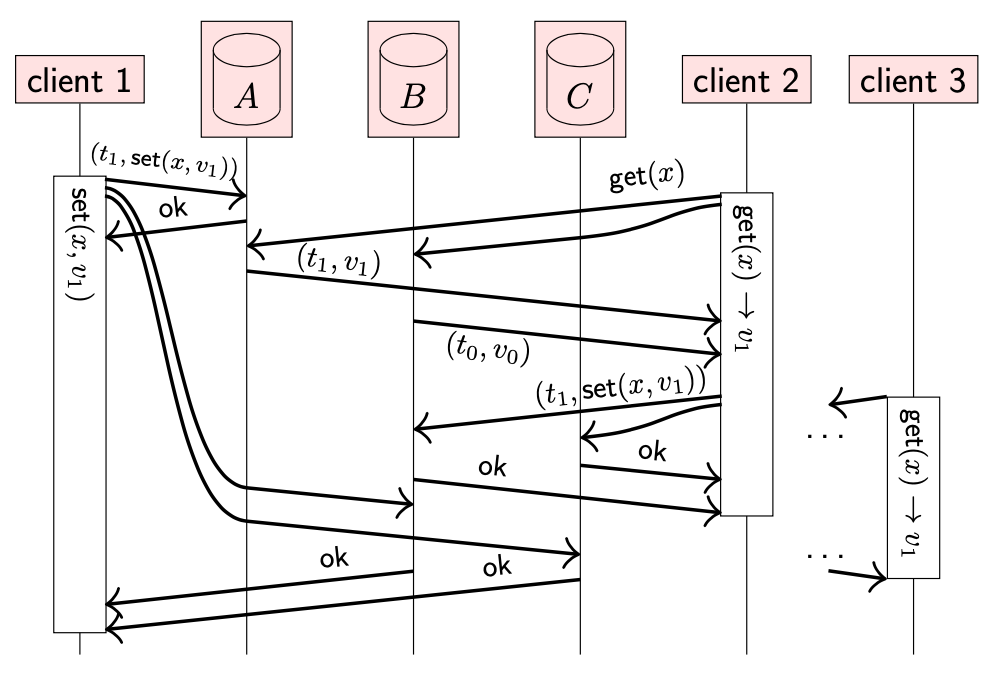
注意不同操作的返回结果
- client 2 的操作在 client 3 开始前就完成,但是 client 2 读取到了新值,client 3 却读取到了旧值
- 该结果违反了 Linearizability
Quorum 读写也可以满足 Linearizability。
- 简单起见,假设 set 操作只能由一个指定节点执行(稍后会移除该假设)
- set 操作与之前一样:发送给所有副本,并等待 quorum 节点确定
-
对于 get 操作由额外的要求:client 将读取请求发送给所有副本,并等待回复。如果某些节点的回复比其他节点新,client 必须将最新值回写给所有未响应最新值的副本:read repair。只有在 client 确认最新值存储在 quorum 副本之后才能结束。
该方法被称为 ABD 算法:保证了线性读写,因为每当读写操作完成之后,读写操作的值都存在 quorum 副本中,因此后续的 quorum 读都能保证获取到该值(或者之后的值)。
7-2-2 Linearizable compare-and-swap (CAS)
ABD 算法虽然能提供线性化,但是其写操作可能会覆盖数据项的值,不管之前是什么值,被称为 blind write。如果多个 client 并发更新同一个数据,ABD 算法会采用 LWW(last write win)冲突解决策略:只有一个值被保留,其他值被丢弃。
在一些应用中,我们期望只有在数据项没有被其他节点并发修改时才进行覆盖操作,可以通过原子的 CAS(compare-and-swap)操作来实现。那么如何在分布式复制系统中实现线性化 CAS 操作?
Linearizability 的目的是使系统表现得好像只有一份数据副本,系统操作都是原子的。虽然该系统实际上是复制系统。这使得 CAS 成为线性化上下文中应该支持的操作。
通过使用全序广播,可以实现线性化 & 存在复制系统中的 CAS 操作。只需要广播每一个需要执行的操作,并在消息到达后执行该操作,类似状态复制机。

7-3 Eventual consistency
Linearizability 是分布式系统中非常方便的同步模型,因为它保证了系统的表现看起来像是只有一份数据副本,即使实际上是分布式复制系统。使得应用程序可以忽略分布式系统中的复杂性。然而这种强一致的保证有一定成本,因此 Linearizability 并不一定适合所有程序。
- 性能成本:ABD 算法与以全序广播为基础的线性 CAS 算法都需要通过网络发送大量消息,并且由于网络延迟需要长时间等待
- 可扩展性(scalability)成本:在需要 leader 对更新操作进行序列化的算法中,如 Raft,leader 可能会称为瓶颈,限制单位时间内可以执行的操作数量
也许线性化最大的问题是,每个操作都需要与 quorum 副本进行通信。如果一个节点暂时无法与足够多的节点通信,那么其将不能进行任何操作。尽管该节点正常运行,由于网络故障导致其实际不可用。
考虑这个场景,我们的手机,平板,电脑等都有日历程序,不同设备之间可以相互同步日程。假设当前设备离线后我们像要更新日程,如果该应用程序的复制协议是线性化的,那么我们将无法进行更新操作,因为离线设备无法与 quorum 节点通信。相反,日历程序允许设备离线的情况下更新日程,并在后台稍后将更新同步。
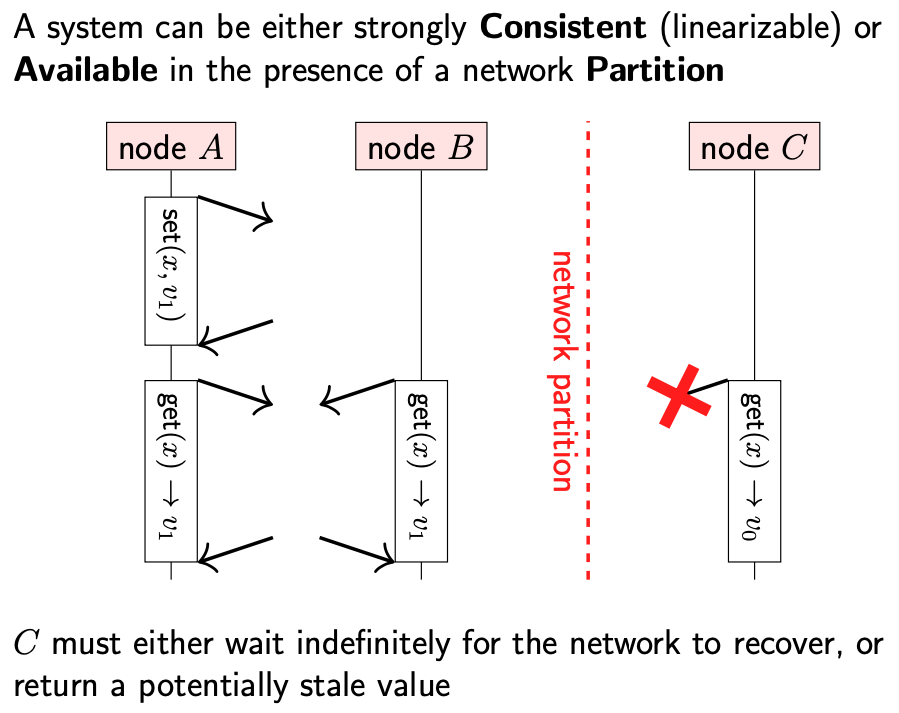
这种权衡被称为 CAP 理论(consistency, availability, and partition tolerance)。CAP 理论指出,当出现网络分区时,我们需要作出选择:
- 如果选择线性一致性,那么一些节点就不能响应请求,因为其不能与 quorum 节点通信
- 也可以选择让副本继续响应请求,即使不能与其他副本进行通信。这种情况下,系统继续可用,但是不能保证线性一致性
有时,CAP 理论被表述为 “从3个中选择2个”,这种表述误导性。在不存在网络分区的情况下,系统可以同时保证 linearizable & available。只有在网络分区存在的情况下才需要强制选择。
允许每个副本仅根据其本地状态处理读写操作,而无需等待与其他副本通信的方法被称为乐观复制(optimistic replication)。
针对乐观复制系统提出了各种一致性模型,最著名的是最终一致性(eventual consistency)。最终一致性的定义为:
- 如果没有对对象进行新的更新操作,最终所有读取操作都将返回上次更新的值
该定义比较弱:如果更新从未停止,那么该表述的前提假设就不成立
一个稍微强一点的一致性模型被称为 strong eventual consistency。它基于这样一种思想:当两个副本通信时,它们会收敛到同一状态(但是没有保证时间)。

在最终一致性和强最终一致性中,可能存在不同的节点同时更新同一对象,从而导致冲突。有许多算法被提出用来自动解决该冲突,比如 last-writer wins,或者合并冲突。
下图是对我们讨论的一致性模型的总结: