IM 系统设计与实现
该文档是从字节离职后在美团的技术分享
1-介绍
IM(Instant Messaging 即时通讯)在我们日常生活中扮演者比较重要的角色,为我们的社交提供了很大的便利,我们基本上每天都会使用该系统,比如微信,QQ,大象,钉钉等。
作为 RD,我们可能或多或少思考过这套系统是如何实现的,消息收发流程是什么样的,为什么有些社交软件的群人数存在上限,我将结合之前的开发经验给大家分享一下 IM 背后的简单实现。
1-1 思考
在正式介绍 IM 系统实现之前,先给大家抛出一个问题。
如何实现微信朋友圈功能?
在 DDIA (数据密集型系统设计)这本书中有个示例,即 Twitter 实现发布消息的功能,与之类似。
使用 Redis 简单实现的其中一个思路是:为每个用户维护一个 zset( member: 动态,score: 动态发布时间),查看朋友圈时先拉取所有好友的最新动态(比如前十条,即 zset 的前 10 个数据),再对这些动态进行排序,并取出排序后的前 10 条;再次拉取,然后排序……
每次只拉取最新几条动态就进行排序的主要原因是内存限制。
1-2 特性
IM 系统一般具备哪些特性呢?如何评价一个 IM 的技术是否优秀呢?
通常来说,IM 系统应该具备以下几个特性:
-
实时性
顾名思义,即时通讯就是希望能够保证消息实时触达。A 给 B 发送消息,就是期望这条消息能够立马送达。那么对于一个 IM 系统来说,实时性是其关键特性,如果连这个特性无法满足,用户可能根本不会买账。
-
可靠性
关于可靠性这部分其实可以拆的更细,主要包括消息的有序性,不丢失,不重复。
当一个用户发了多条消息,对方也应该按序接收到对应的消息,如果消息发生错乱,很可能造成上下文完全不同的表达。除了保证顺序性,发出的消息也应该保证不会被丢弃,并且不能因为网络等一些问题导致发送的内容被重复接收。
-
安全性
IM 系统应该保证消息传输及存储的安全性,这对用户隐私来说相当重要。不管对于消息在网络传输还是存储到客户端本地,都应该进行消息的加密处理,保证消息内容不能被破解。
上面这些特性应该是每个 IM 系统都需要实现并且尽可能做到最优解,具体的实现方案各家有各家的解法,比如实时性这一项,在系统需要处理的消息量达到一定的级别之后,如何保证消息仍能够实时触达。
介绍完 IM 系统的特性,有必要提一个产品 Telegram。该产品在可靠性,实时性,安全性方面做的都非常优秀(加密算法,超大公开群等),目前只有客户端代码开源。
1-3 技术要点
既然一个 IM 系统的基本特性有了,我们在实现这些特性过程中主要关注哪些技术要点?
安全性这部分主要考虑一些加密算法,暂时先不讨论。
-
消息推送协议
一般为了保证消息收发的实时性,在消息传输过程中可供选择的方案一般有:轮询,长轮询,TCP,UDP,WebSocket 等。
轮询对服务端与客户端都额外增加较多的资源压力;长轮询可能存在消息推送延迟过高;UDP 数据传输可靠性存在问题,一般需要在应用层做二次处理;TCP,WebSocket 本质上差不多,只不过一个是传输层,一个是应用层,如果使用 TCP 的话需要包装一层应用层协议。
大部分情况下,大家都会优先选择 TCP 作为消息推送协议。
我们之前由于项目的特殊性,采用 TCP & WebSocket 两套协议
-
消息存储系统
消息收发完成之后需要进行存储,以便用户查看历史消息。分析下消息存储的特点:
- 消息写入后基本不要求再修改
- 对写入和读取的速度要求非常高
- 读请求大部分都集中在新消息,并且顺序读请求量高
- 消息的量级随着用户的增加而越来越大。
存储系统的选型值得考量,首先需要支持大容量,能够进行持久化(消息漫游),并且查询及写入效率不能较低,期望能够支持较高的 QPS。我们常用的存储系统有 Mysql && Redis,这两个系统各有优缺点,Redis 性能高,但是存储容量受限;Mysql 的查询写入效率瓶颈较低。那么如果两者结合呢,即 Redis 做缓存,Mysql 做持久化,看起来仍然不是最优解,还是会受限于 Redis 的容量与 Mysql 的性能。
关于分布式存储,Google 在 05 年左右发表了一篇论文 BigTable,介绍了其分布式 KV 存储系统的实现,根据描述来看 BigTable 既能实现高效查询,也能支持超大容量存储(10万级随机写 QPS,10亿级存储数据)。虽然没有开源,但是业界存在一些优秀的实现案例,比如 LevelDB,RocksDB 等,国内比较优秀的商业化产品 TiDB,美团内部的 Cellar 就是基于 LevelDB & RocksDB实现。
综合来看,这种分布式 KV 存储系统更值得选择。
关于之前内部的 ABase 系统没有找到公开资料,也是在 RocksDB 的基础上做了优化实现的。
-
消息可靠性保证
有序性,不丢失,不重复这些特性不只是服务端需要考虑,客户端在进行消息发送的时候也应该实现这些功能。
从服务端的角度来说,一般采用 MQ 作为传输组件,通过业务逻辑处理 + MQ 的基本特性基本能保证消息的可靠性;并且 MQ 的削峰填谷特性能够帮助我们应对激增的消息流量,同时实现各个服务端组件的解耦。之前的项目采用 Kafka 作为消息传输组件,主要利用 Kafka 高吞吐量 && 分区有序的特点。
大象的技术文档中只说明是 MQ,没有具体指名是哪一种,猜测也是 Kafka
上面三个点是我个人觉得一个 IM 系统在进行技术选型时应该重点考虑的;同步以下我之前参与的项目技术选型:消息推送采用 WebSocket,消息存储采用内部分布式 KV 存储组件,消息传输过程使用 Kafka。
2-概述
2-1 名词解释
| 名称 | 含义 | 备注 |
|---|---|---|
| 消息 | 由特定协议标识,用于在各个端之间传递 | 存在多种类型,文本消息,系统消息,多媒体消息等;由应用层制定消息协议格式 |
| 可见性 | 某个消息只允许特定的用户查看 | 全部可见,部分可见,自己可见等 |
| 会话 | 用户之间传递消息,则建立一条会话 | 消息传递的载体,每个消息都属于特定的会话 |
| 单聊 | 一对一产生的会话称为单聊 | 可以自己给自己发送消息 |
| 群聊 | 多人参与的会话称为群聊 | |
| 会话链 | 用于存储某条会话的所有消息,消息按产生时间有序存储 | 存储顺序以服务端接收为准 |
| 用户链 | 用于存储某个用户参与过的所有会话消息,消息按产生时间有序存储 | 单条用户链包含多个会话 |
| 写扩散 | 消息分发时需要写入参与该会话的所有用户的用户链 | 强调消息分发过程 |
| 读扩散 | 消息拉取时需要拉取当前用户参与的所有会话的会话链 | 强调消息拉取过程 |
关于读扩散,写扩散的概念可能暂时有些疑惑,后面会详细介绍。
2-2 消息模型
为了方便客户端与服务端之前的通信,需要对传递的消息制定具体的协议,一般来说,消息需要具备以下属性。

- MessageId:用于标识消息的唯一性
- MessageType:消息类型,可能是文本消息,多媒体消息等
- ConversionId:消息所属会话,会话是单聊还是群聊可以在 ConversionId 中标识,也可以新增字段
- Sender:消息发送者,对于系统消息可能存在特殊标识
- Receiver:消息接收者,对于群聊消息来说,可能为空
- MessageBody:消息的具体内容,不同的消息存在不同的结构体
- Visibility:消息的可见性(可能存在)
- ConversationIndex: 会话链消息索引
- UserIndex:用户链消息索引
上面这些信息基本能够标识消息收发过程中所需要的信息,不同的系统实现可能不一样,大象的实现方案 消息详解
2-3 消息收发模型
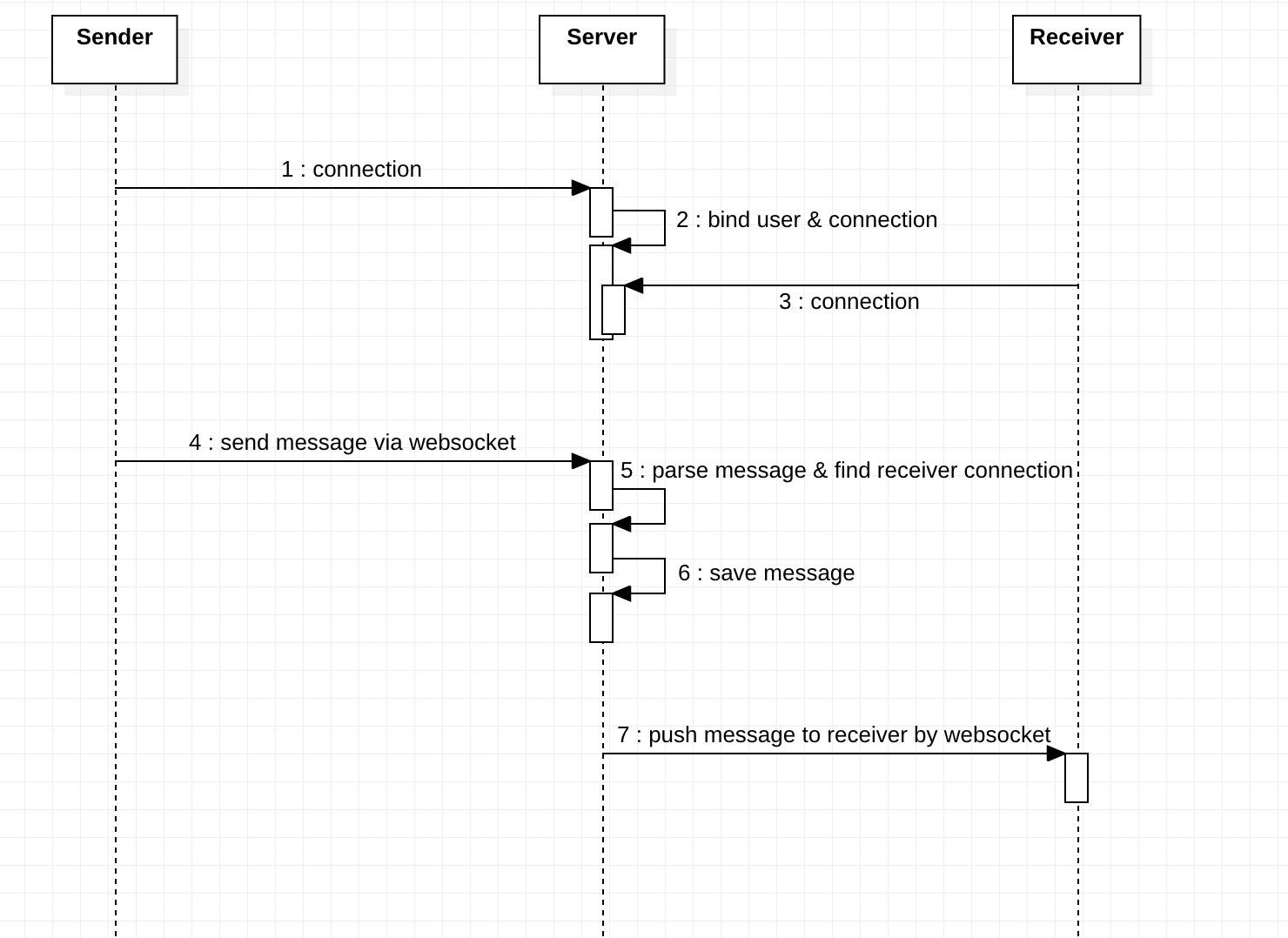
在选取 WebSocket 作为传输协议的前提下,基本的消息收发模型抽象起来比较简单。
- 发送方与接收方分别与服务端建立长连接,分配特定的 connectionId 用于标识该连接
- 在服务端内部将该 connectionId 与 用户信息 userId 进行绑定
- 发送者发送消息到服务端,其中包含接收人的 userId,消息的具体内容
- 服务端解析消息,找到接收方对应的长连接 connectionId
- 服务端将消息通过长连接推送给接收方
3-实现
前面基本介绍了技术选型及简单的模型抽象,下面我们介绍整个系统的具体实现。
3-1 消息路由与存储
名词解释中有一个叫做写扩散,这个动作发生在消息路由的过程,那么消息路由具体做哪些事情呢?
我们分析下消息模型的属性,首先消息属于某个会话,会话是消息的载体;同时消息也与用户绑定,每个消息都有它的发送者与接收者。因此,我们可以从两个维度看待消息:会话与用户。从这个观点出发,在消息路由与存储时,我们可以进行两个动作:
- 将消息路由到与会话相关的模块
- 将消息路由到与用户相关的模块
为了实现上面观点,可以为 Kafka 设置两个 Topic:User Topic && Conversation Topic;消息存储时也存在两条链:用户链 && 会话链。
我们使用 Kafka 作为消息的中转,主要利用其分区有序的特点,在 Kafka 每个 partition 中,消息有序存储,从而在服务端侧保证消息的有序性。
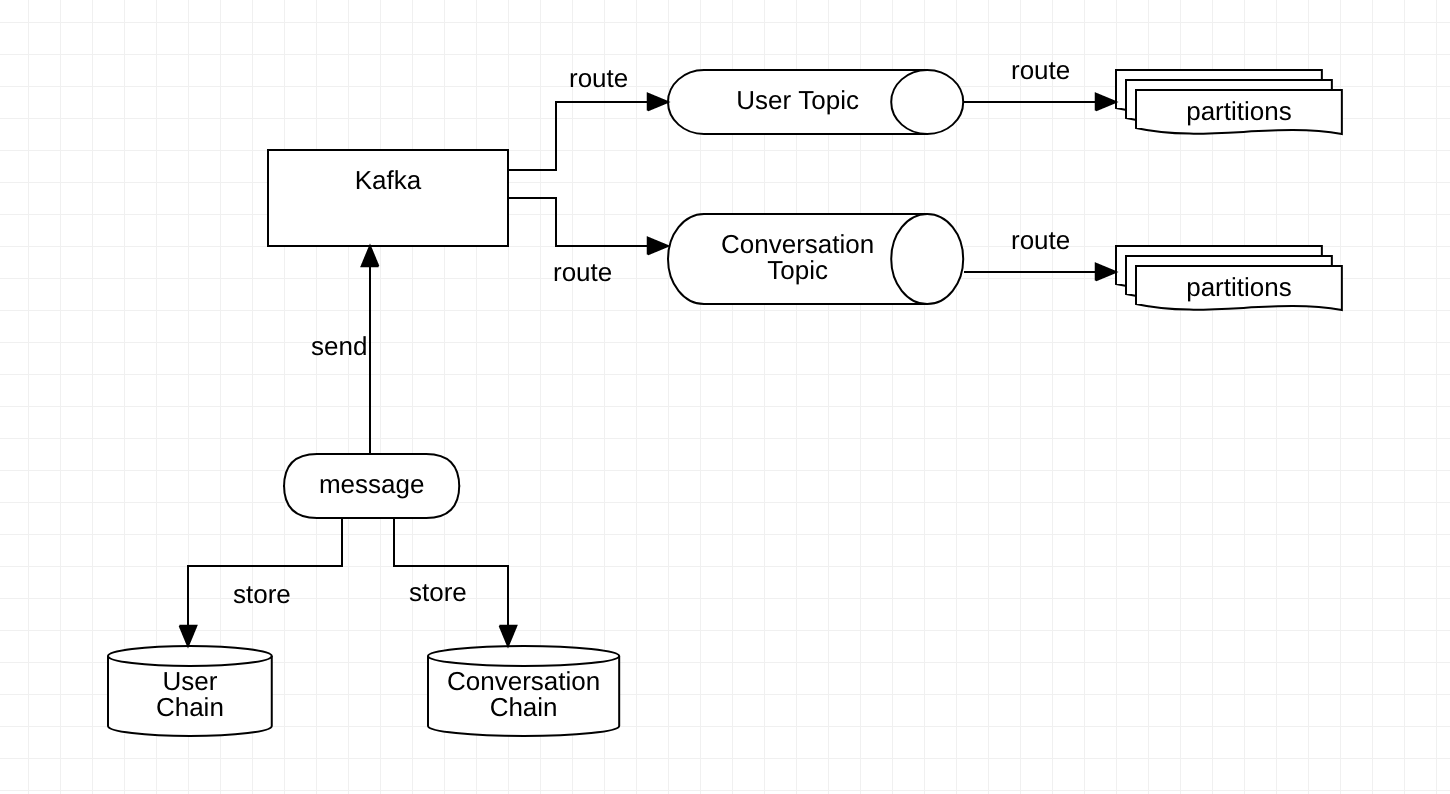
当路由到会话维度时,路由 key 为conversionId;当路由到用户维度时,路由 key 为 userId。
按照这样的路由规则之后,User Topic Partition 与用户链中均包含多个会话的消息(也被称为混链),而 Conversation Topic Partition 与会话链中只包含单个会话的消息(也被称为单链)。

3-2 消息分发
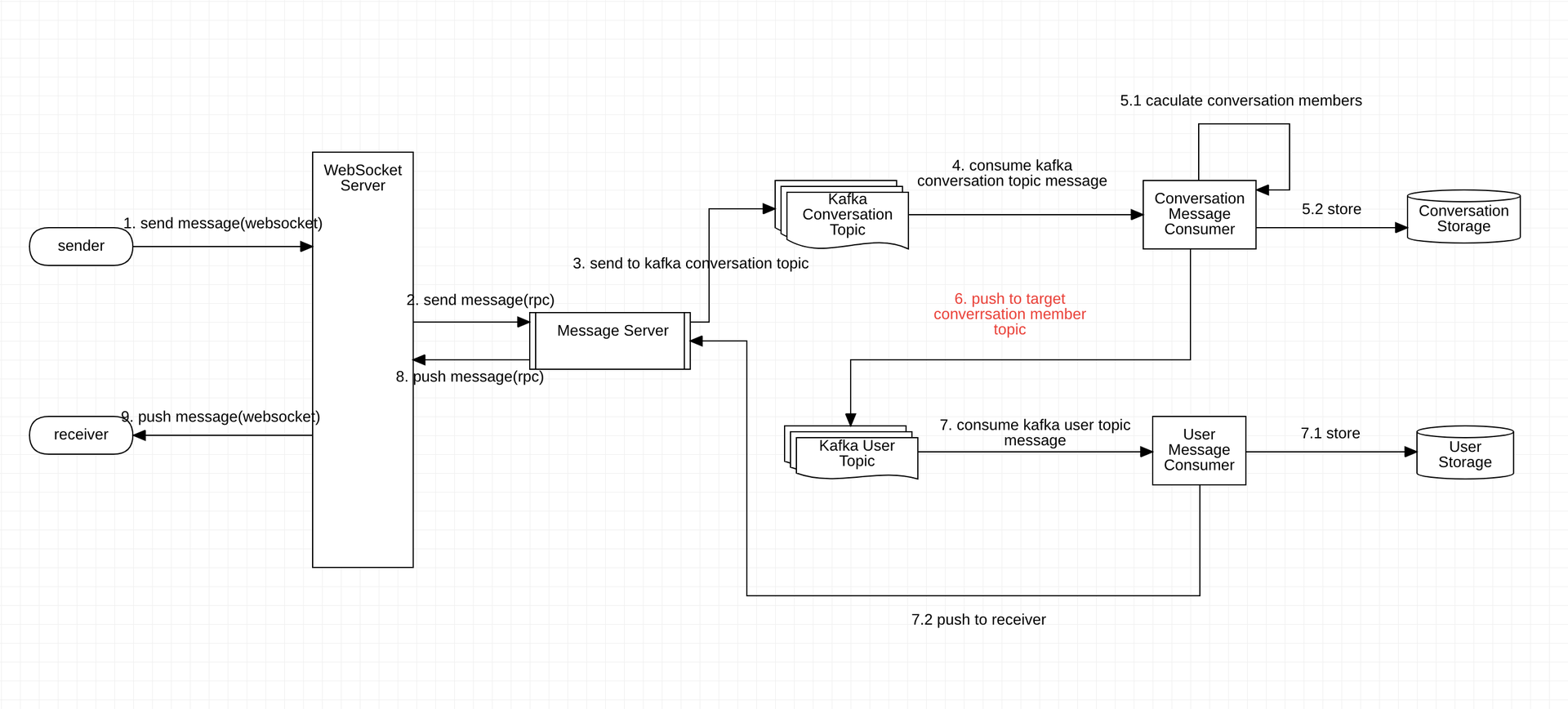
消息分发过程是整个系统中最重要的部分,性能的瓶颈一般在于分发策略的选择上,分发过程存在可以较多进行深入优化的点,基本的分发流程如下:
-
发送者通过长连接将消息发送到长连接服务器
-
长连接服务器通过 rpc 接口将消息发送到消息服务器
-
消息服务器收到消息后进行解析,同时生成 MessageId 标识消息的唯一性;根据消息中的 conversationId & 特定的路由规则,将该消息发送到 Kafka Conversation Topic 中特定的 Topic Partition 中。同一个会话的消息会路由到固定的 Partition 中,该步骤保证了消息的有序性。
-
每个 Conversation Message Consumer 线程会消费特定的 Partition,这一步也保证了消费消息的有序性。
-
-
计算当前会话的参与用户:单聊基本是2个人,群聊存在多个人;这里的目的是为了后续将该消息写入用户链中。
-
将消息有序写入会话链,同时生成该消息在当前会话链中的 index,以便后续进行消息查询。会话链消息有序存储,并且每个消息 index 单步递增。
-
-
根据 5.1 步骤计算的会话参与用户信息,将该消息写分别入对应的 Kafka User Topic 特定的 Topic Partition 中,该步骤同样保证了消息的有序性。
该步骤就是写扩散的开始,试想如果只是单聊,那么需要将消息分发写入两次;如果是10人的群聊,消息需要被写入10次;如果是10000人的群聊,消息需要被写入100000次……所以在我们使用一些社交软件时,可能会遇到群人数达到上限的情况;超大群是对整个IM系统性能的考验。
写扩散的次数取决于参与会话的人数,人数越多,扩散压力越大。针对这种扩散带来的压力,不同的产品有不同的优化策略:
-
放弃写扩散,消息只被写入会话链:这种策略会将压力转移到客户端(读扩散)
-
消息延迟发送:收到的消息暂时先置入延迟队列中,等到消息积累到一定数目或者一定延迟时间,再将消息进行分发,降低分发次数
-
大群拆小群:针对拆分的群单独做处理
-
针对消息的可见性确定路由规则:全员可见的消息放弃写扩散,部分可见的消息仍然进行扩散
-
……
-
- 每个 User Message Consumer 消费特定的 User Topic Partition
- 将消息有序写入用户链,同时生成该消息在当前用户链中的 Index,以便后续消息查询。用户链消息有序存储,并且每个消息 Index 单步递增。
- 将消息生成的用户链 Index && 会话链 Index 通过 rpc 返回给消息服务器。
-
消息服务器将服务端生成的消息信息返回给长连接服务器,包括 MessageId & UserIndex & ConversationIndex
- 根据接收者的用户信息匹配对应的长连接,并将服务端生成的信息传给接收者
消息的有序性通过 Kafka 分区有序 & 消费者线程按序消费/存储保证,并且每个消息在会话链与用户链中都存在特定的 Idnex,以便后续消息拉取。
在消息分发中存在扩散(fan-out),这个步骤有些系统会选择直接放弃,因为写扩散会导致在群聊人数较多的情况下影响系统的性能,但是直接放弃写扩散会将压力转移到客户端。
写扩散:如果我们将消息进行扩散并写入到用户链中,那么客户端在进行消息拉取的时候只需要拉取属于自己的用户链;用户链中包含多个会话消息,客户端只需要按序读取消息进行简单排列即可。
读扩散:如果消息放弃扩散从而不写入到用户链中,那么客户端在进行消息拉取的时候需要拉取所有当前用户参与过的会话链;每个会话链中只包含单个会话信息,客户端在拉取所有会话链之后需要做的工作就比较多了。
通过与大象同学交流得知,这部分实现应该主要是读扩散实现;大象最多支持群人数量级为十万
3-3 消息拉取
在消息分发过程中,会给每个消息生成特定的 ConversationIndex & UserIndex,分别标识该消息在会话链/用户链中的位置,客户端在进行消息拉取的时候主要就是根据 Index 拉取。
首先,客户端会维护当前收到的最新的 UserIndex/ConversationIndex,每次收到新的消息推送后,更新本地 Index,并拉取最新的消息。其次,拉取消息的策略根据用户当前的位置可能有所不同,比如说用户处于会话列表界面时,会拉取用户链;用户处于会话内部时,会拉取当前会话链。
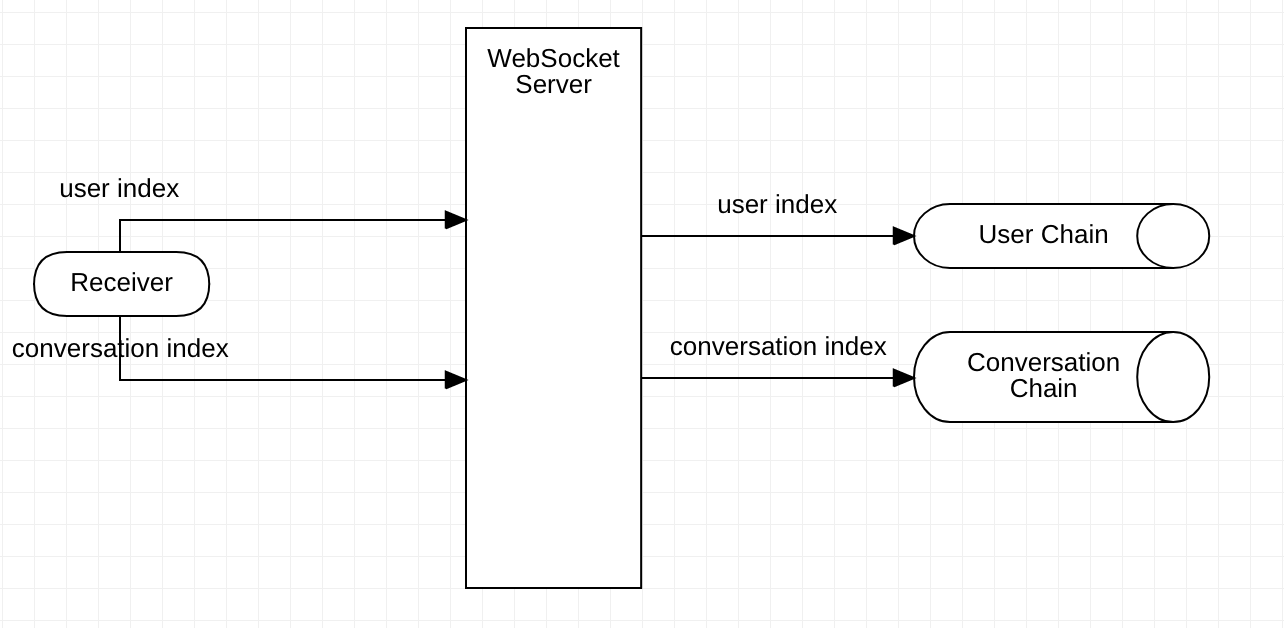
如果采取读扩散拉取消息的话,流程图如下:
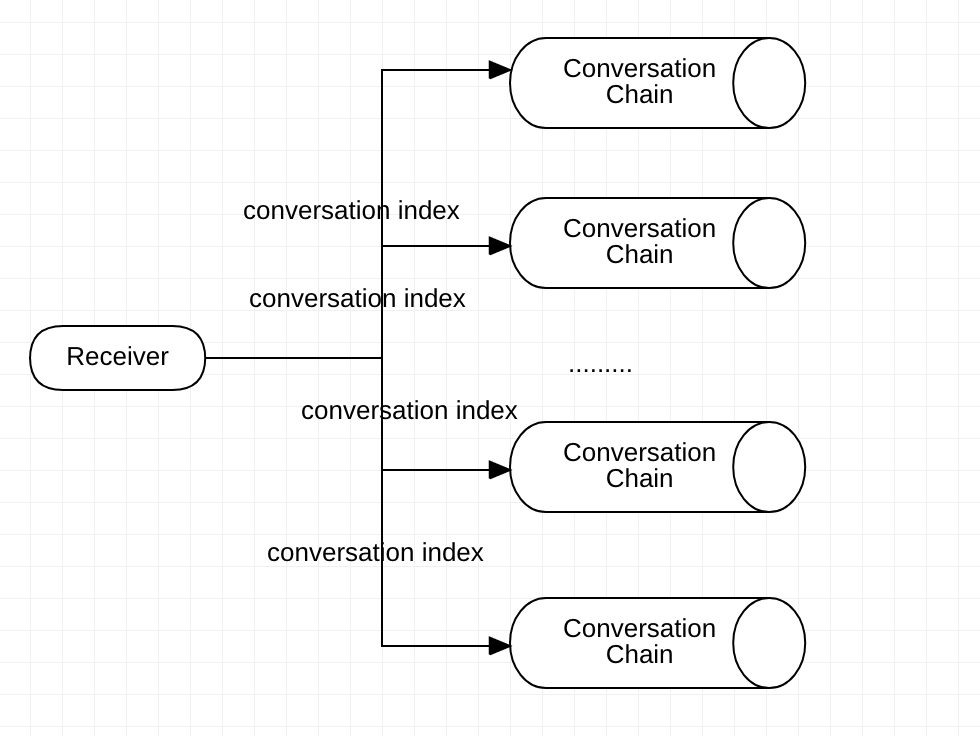
消息分发模式非不同决定了消息拉取的策略
4-FAQ
-
消息内容主体在会话链与用户链分别存储吗
消息主体只单独存一份,用户链与会话链中只保存消息标识;在用户拉取消息时再进行消息拼装
-
Kafka 分区数目变更或者重启如何处理
kafka 重启不会对消息重新消费产生影响,每个消费者都记录消费的 offset,支持重新消费。
分区数目变更会导致消息错乱,因此在系统搭建的时候就需要根据业务预估容量确定分区数目,保证后续不会变更。
-
部分可见的消息如何处理
最常见的部分可见消息一般是指系统消息,比如有人给你的消息进行点赞,就会收到个人可见的系统通知。
对于部分可见的消息,通常是在消息进行分发的时候进行选择性分发,只将消息写入可见用户的用户链,不可见用户的用户链中不存在这条消息。
如果采取读扩散的话,会在会话拉取的时候进行过滤。
-
如何保证客户端发送消息的有序性
客户端维护一个消息发送队列,类似于TCP发送队列,支持超时重传,并且客户端发送的消息中会携带一个 ClientMessageId ,对于特定的 ClientMessageId 以服务端收到的顺序为准
-
Receiver 离线怎么处理
使用 Google FCM 的离线推送,将最新的消息 Index 推送给 receiver,等用户重新上线之后再进行拉取
-
用户换机登录如何处理
如果采用的是写扩散模式,那么用户只需要拉取自己的用户链即可;如果采用的是读扩散模式,用户需要拉取所有会话链。读扩散模式会在换机登录时给客户端带来较大的压力。
关于消息拉取的数目,一般会设定默认的消息漫游时间,有的是一个星期,三个月或者六个月
-
大群优化策略
虽然针对大群存在各种各样的优化策略,但是大部分都会采用大群读扩散的模式,降低服务端写扩散的压力,因为一个人参与的大群数目可能不是特别多,客户端的压力不是很大。
-
长连接维持
采用心跳包,具体的间隔可能受到 ISP 的限制
-
长连接的数目
限制长连接数目的主要因素是每个连接所占用的内存,因此之前我们的优化主要集中在 TCP/WebSocket 默认分配的发送缓存;支持单机几十万连接
-
如何支持多设备同时在线
一般情况下长连接服务会维护 user -> devices 的映射,在用户登录/退出时会更新该映射,那么消息在推送时会选择当前在线的设备进行推送
5-总结
上面基本简单介绍了一个IM系统的实现过程,不同的业务在技术选型上会有很大的不同,本文只是阐述个人在开发IM系统时的经验;其实关于IM系统其实有较多的技术细节需要考虑,不能一一说明。
回到之前留的思考,其实就是读扩散与写扩散之间策略的权衡。