Kafka: Meet Kafka
1.1 发布订阅消息系统
发布订阅消息系统的一个特点是,消息的发送者不会直接把消息发送给接收者。发送者以某种方式对消息进行分类,接收者订阅它们,以便接收特定类型的消息。
发布订阅系统一般有一个 Broker:发布消息的中心点。
1.2 Kafka 登场
Kafka 一般被称为“分布式提交日志”或者“分布式流平台”。
在数据库中,提交日志用来提供事务的持久化记录,可以通过回放这些日志还重建系统状态。
Kafka 的数据是按照一定顺序持久化保存的,可以按需读取。同时,Kafka 的数据分布在整个系统中,具有数据故障保护,性能伸缩的能力。
1.2.1 消息与批次
Kafka 的数据单元被称为“消息”。
- 消息由字节数据组成,因此消息内容没有特殊的含义或格式。
- 消息有一个可选元数据,被称为“键”。键也是一个字节数组,没有特殊含义。
当消息以一种可控的方式写入不同的分区时,会使用键,保证相同键的消息被写到相同的分区上。
“批次”是一组消息,这些消息属于同一个主题与分区。将消息按照批次写入到 Kafka,可以减少网络开销,有效提高效率。不过,批次大小需要在消息延迟与吞吐量之间进行权衡:
- 批次越大,单位时间内处理的消息就越多;相应的,单个消息的延迟就越大
批次数据会被压缩,以提升传输与存储能力,但需要更多的计算处理
1.2.2 模式
对 Kafka 的来说,消息只是一些字节数组,难以理解,因此希望可以结构化定义消息内容。
消息模式(Schema)有多种选项,如 JSON,XML;不过它们缺乏强类型处理能力,版本之间的兼容性也不好。
最常用的 Kafka 消息模式是 Apache Avro:
- 紧凑的序列化格式
- 模式与消息体分开;当模式发生变化时,不需要重新生成代码
- 支持强类型与模式进化,向前向后均兼容
数据格式的一致性,消除了消息读写操作之间的耦合性。
1.2.3 主题与分区
消息通过主题(Topic)进行分类,主题可以被分为若干个分区(Partition)。消息以追加(Append)的方式写入分区,然后以先入先出的顺序读取。
一个主题通常有多个分区,因此无法保证在主题范围内消息的有序性,但是可以保证消息在单个分区内有序。
如下所示,消息被追加到每个分区的尾部:
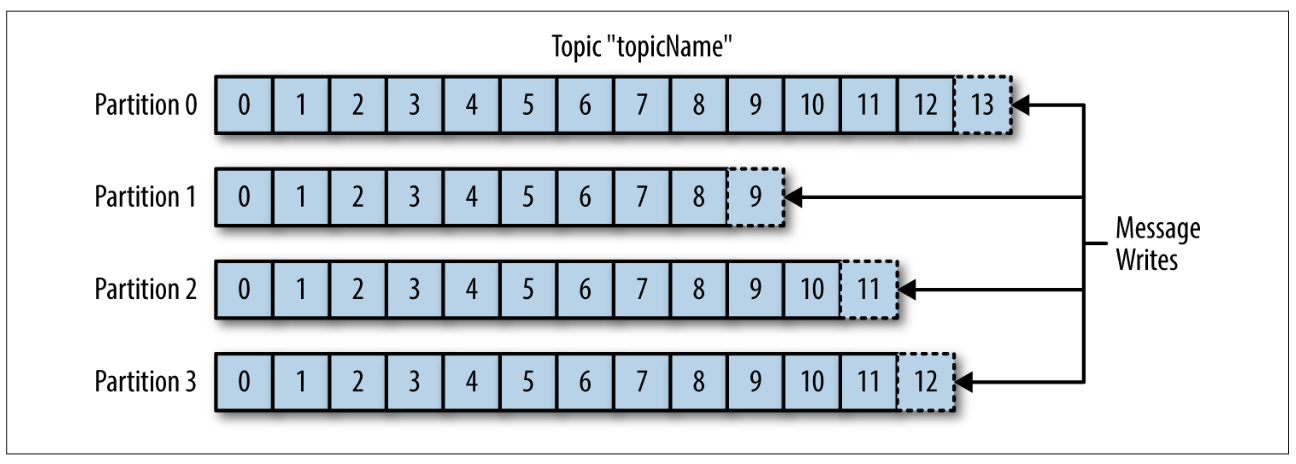
很多时候,人们会把一个主题的数据看作流,而不管主题中包含多少个分区。流可以看作一组从生产者移动到消费者的数据。
1.2.4 生产者与消费者
Kafka 的生产者分为两种类型:
-
生产者
生产者创建消息:一般情况下,消息会被发送到特定的主题,默认会把消息均衡地分布到主题的各个分区上(具体被分配到哪个分区并不重要)。
不过,也可以为消息指定分区,通过消息键与分区器将其映射到指定的分区。
-
消费者
消费者读取消息:可以订阅一个或者多个主题,并按照消息生成的顺序读取它们。
消费者通过检查消息偏移量(Offset)来判断消息是否已经被读取过。消费者把每个分区最后读取的消息偏移量保存在 Zookeeper 或者 Kafka 上,以保证在消费者重启之后可以从之前的位置继续消费。
偏移量是消息的元数据,是一个不断递增的整数值。在 Kafka 创建消息时,会设置其偏移量。
在给定的分区内,消息的偏移量是唯一的
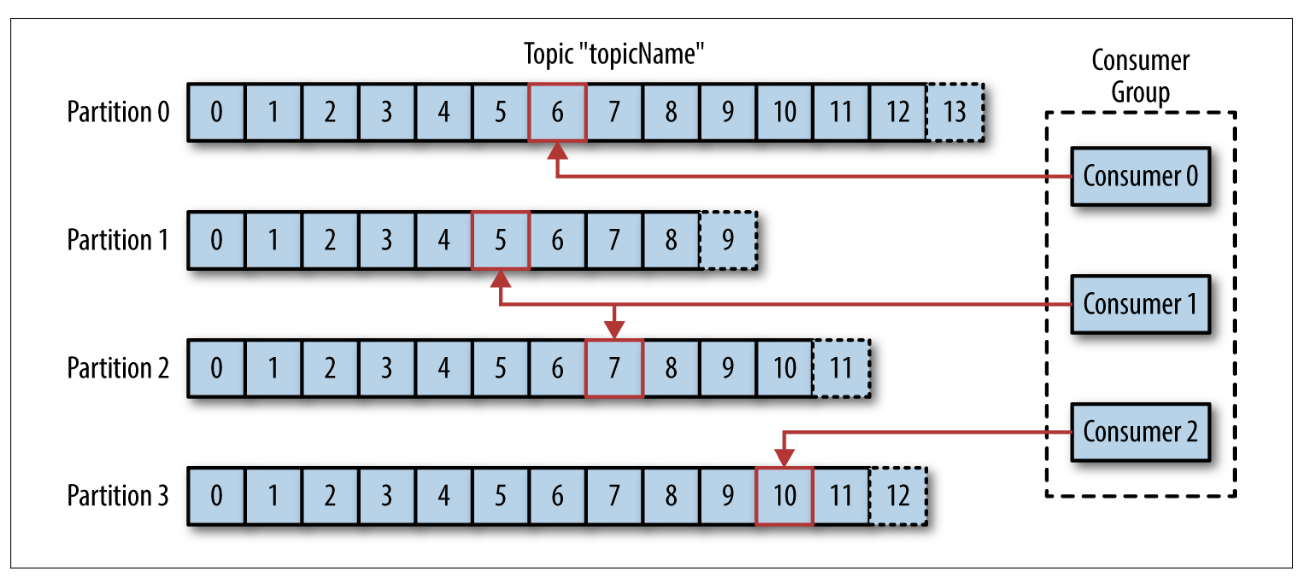
消费者是消费者群组的一部分;消费者群组保证每个分区只会被一个消费者读取,消费者与分区之间的映射关系被称为消费者对分区的所有权关系。通过这种方式,消费者可以消费包含大量消息的主题,并且当一个消费者失效时,其他消费者可以接管失效消费者的工作。
如下所示,消费者群组与分区的关系:
1.2.5 Broker 与集群
一个独立的 Kafka 服务器被称为 Broker。
- Broker 接收生产者的消息,为消息设置偏移量,并将消息保存到磁盘
- Broker 对消费者读取分区的请求,返回已经提交到磁盘上的消息
单个 Broker 可以处理上千个分区以及每秒百万级的消息量
Broker 是集群的组成部分,每个集群都有一个 Broker 同时充当集群控制器的角色。
- 集群控制器自动从集群的活跃成员中选出来
- 集群控制器负责集群管理工作,如将分区分配给 Broker,监控 Broker 等
在集群中,一个分区从属一个 Broker,该 Broker 被称为该分区的 Leader。同时,可以对分区进行复制,分区副本可以被分配给多个 Broker。复制机制为分区提供了消息冗余,如果 Leader 失效,其他 Broker 可以接管领导权;相关的生产者及消费者都需要迁移到新的 Leader。
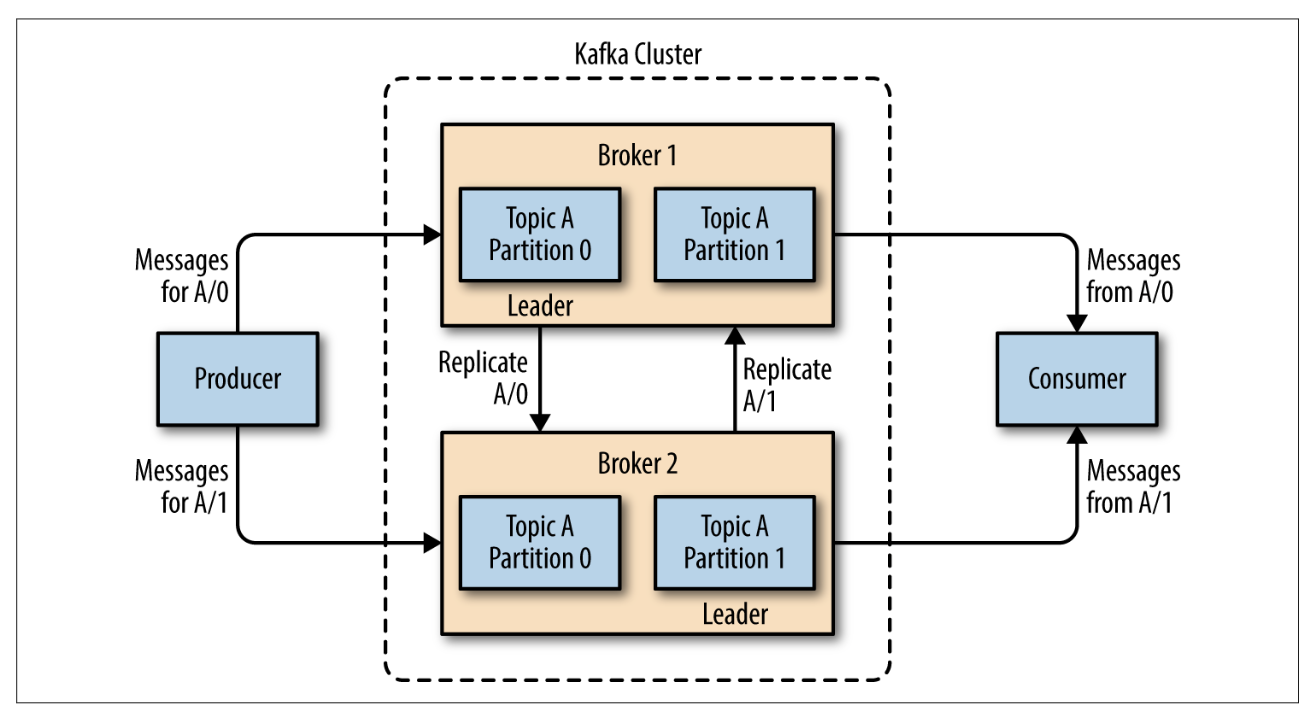
Broker 中的消息可以通过一些参数设置保留时间,过期的消息会被删除。
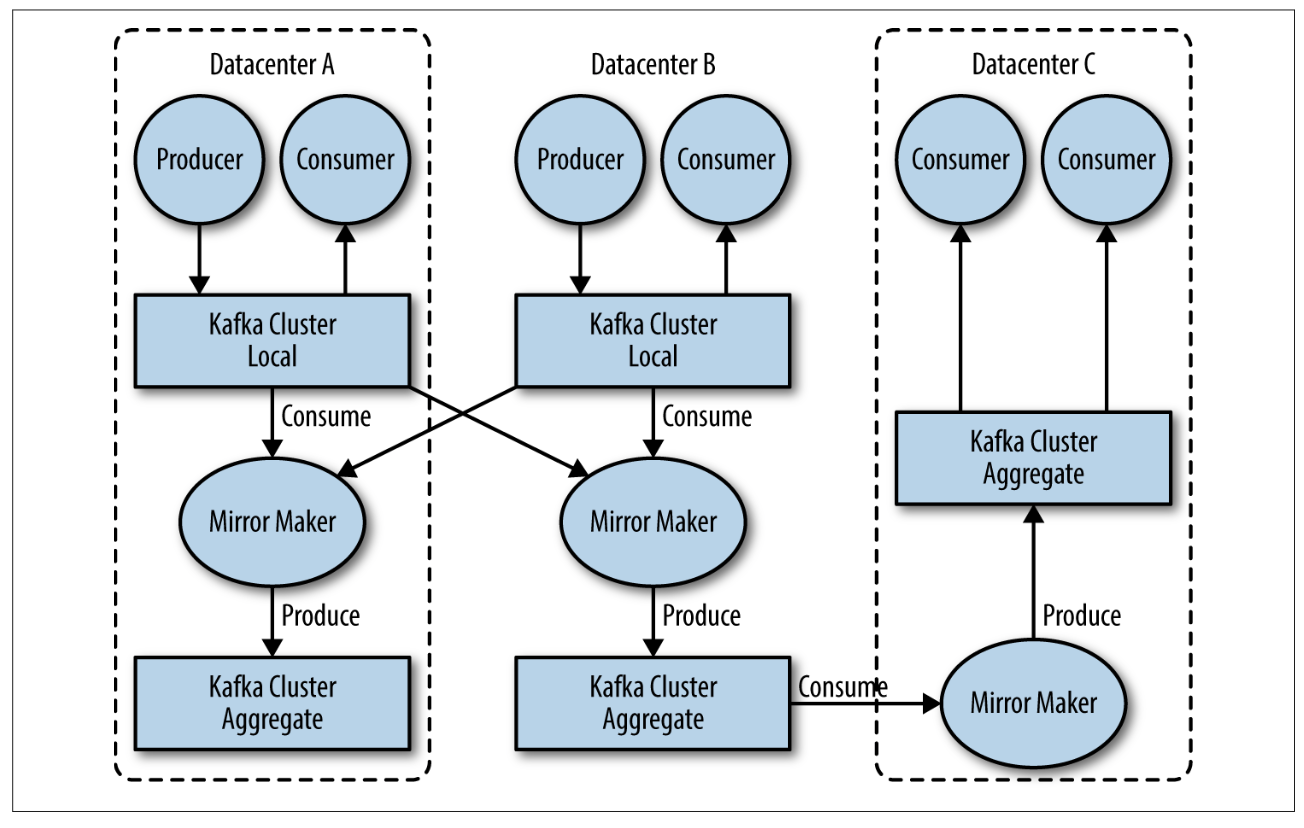
1.2.6 多集群
有以下需求时,可以使用多集群:
- 数据类型分离
- 安全需求隔离
- 多数据中心(容灾恢复)
在多数据中心内部署多个集群时,可以通过 MirrorMaker 工具实现集群间数据复制功能。
1.3 Why Kafka?
-
多个生产者
支持多个生产者往单个主题或者多个主题发送消息,适合从多个系统中收集数据
-
多个消费者
支持多个消费者从一个消息流上读取数据,且消费者之间互不影响。同时,消费者群组内的消费者共享消息流,并且保证对于整个群组,每个消息只被处理一次。
-
基于磁盘的数据存储
消息被保存到磁盘上,并且每个主题可以设置单独的保存规则,以满足不同消费者的需求。
数据持久化可以保证消息不丢失,允许消费者非实时地读取消息。
-
伸缩性
为了支持大量数据处理,Broker 集群支持灵活扩展。
-
高性能
通过横向扩展生产者,消费者及 Broker,使得 Kafka 在处理大量消息时可以保证亚秒级延迟。