Kafka: Cross-Cluster Data Mirroring
我们把 Kafka 集群间的数据复制叫做镜像(mirroring)。Kafka 内置的跨集群复制工具是 MirrorMaker。
1. 跨集群镜像的使用场景
-
区域集群与中心集群
一个公司会有多个数据中心,分布在不同的地域,每个数据中心都有自己的 Kafka 集群。有些应用程序只需要与本地 Kafka 集群通信,有些需要访问多个数据中心的数据,需要把其他数据中心的集群数据镜像到一个中心集群上。
-
冗余(DR)
作为 Kafka 主集群备份,当主集群不可用时,将客户端流量路由到备份集群。
2. 多集群架构
2.1 跨数据中心通信的情况
-
高延迟
Kafka 集群间通信延迟随着距离增加而增大
-
有限的带宽
数据中心广域网带宽资源一般比较有限
-
高成本
集群间通信成本更高
Kafka 服务端与客户端是按照单个数据中心进行设计,调优的,不建议跨多个数据中心部署 Kafka 集群。多数情况下,需要尽量避免向远程数据中心生成消息,如果必须这么做,需要接受高延迟的问题,并且客户端需要进行重试,增大缓冲区等来应对网络分区的风险。
对于跨数据中心通信的需求,建议在每个数据中心部署一个 Kafka 集群,并在集群间复制数据,而不是让应用程序通过广域网访问。
对于跨数据中心通信,有一些架构设计原则:
- 每个数据中心至少一个集群
- 每两个数据中心间数据复制要做到每个消息只复制一次(除非异常重试)
- 如果有可能,尽量从远程数据中心读取数据,而不是向远程数据中心写数据
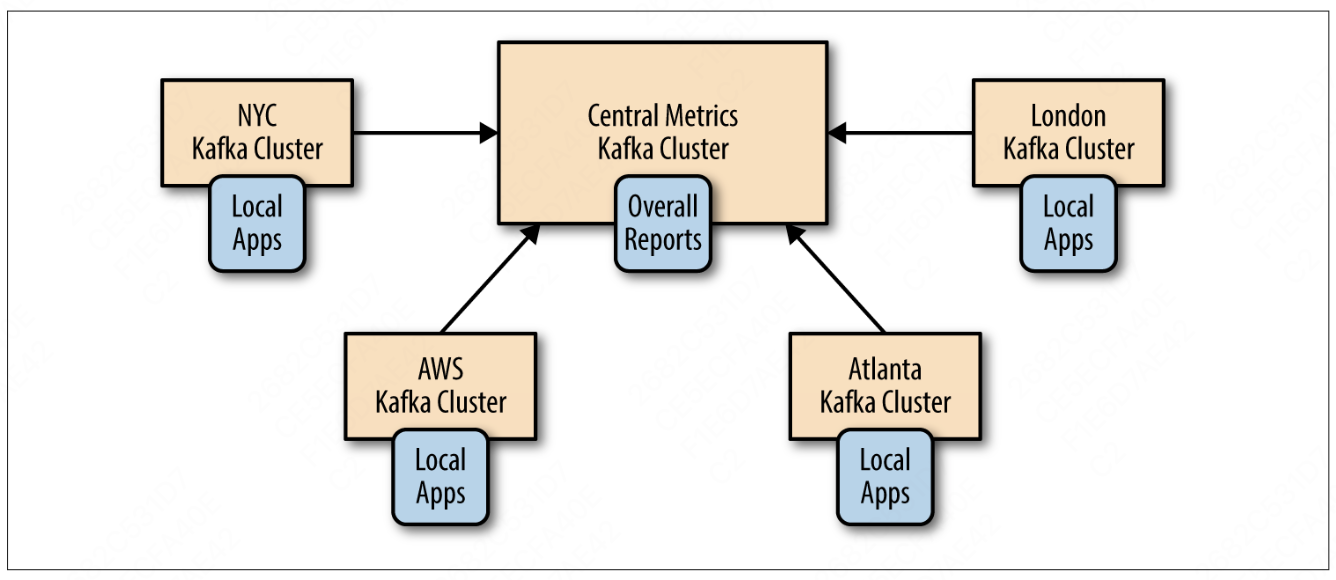
2.2 Hub & Spoke 架构
这种架构适合一个中心 Kafka 集群对应多个本地集群的情况。
如果只有一个本地集群,那么系统就剩两个集群:Leader 集群与 Follower 集群。
Hub & Spoke 架构的优势:
- 数据只会在本地数据中心生成,且每个数据中心的数据只会被镜像到中央数据中心一次
- 只处理单个数据中心数据的应用程序可以部署在本地数据中心内,需要处理多个数据中心数据的应用程序需要部署在中央数据中心内
- 数据单向复制,且消费者总是从同一个集群中读取数据,因此易于部署,监控
缺点:
- 数据访问具有局限性:一个数据中心的应用程序无法访问另一个数据中心的数据。
采用这种架构时,每个数据中心的数据都需要被镜像到中央数据中心上。
2.3 双活架构
当两个或者多个数据中心需要共享数据且每个数据中心都可以生产和读取数据时,可以采用双活(active-active)架构。
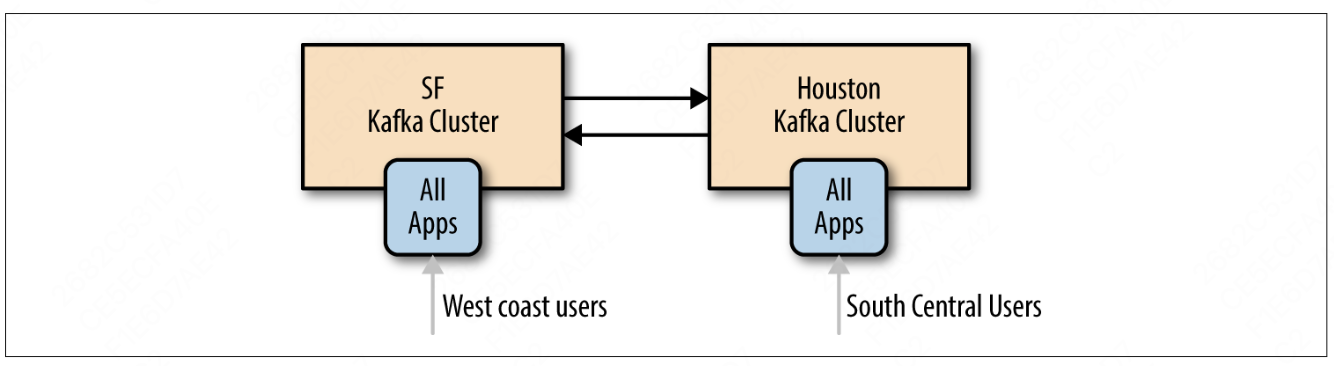
这种架构的优势:
- 就近提供服务,性能较好
- 冗余 & 弹性:每个数据中心提供全量数据,当一个数据中心不可用时,可以把用户重定向到另一个数据中心
缺点:
- 需要解决数据冲突,数据一致性,数据回环复制等问题
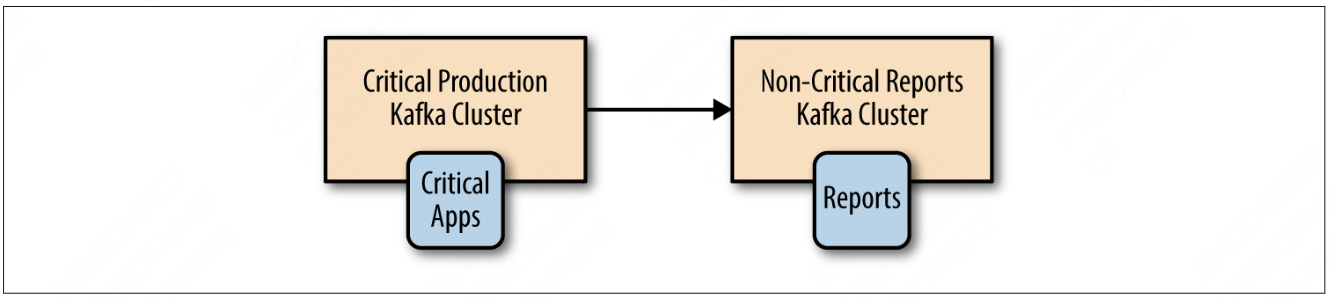
2.4 主备架构
有时候,使用多个集群只是为了灾备。
- 两个集群包含相同的数据,平常只使用其中一个集群。当提供服务的集群不可用时,可以使用备份集群
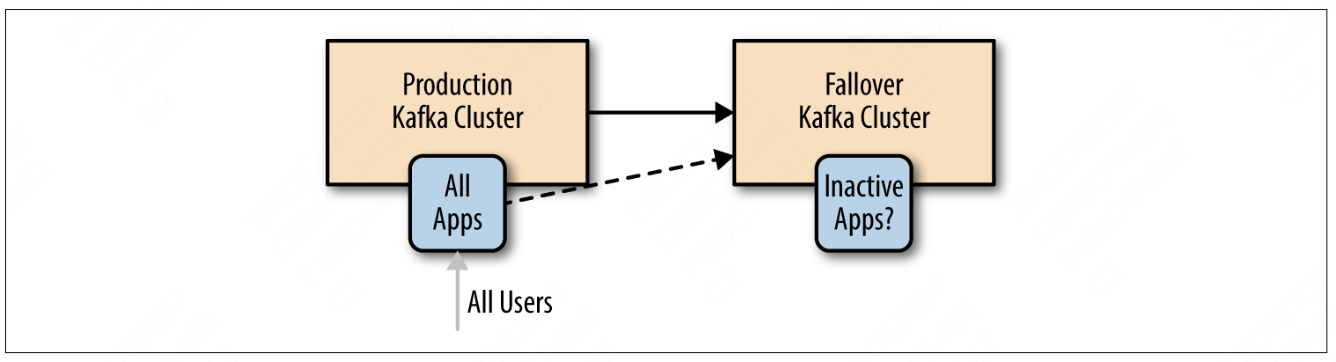
主备架构的优势:
- 易于实现:不需要担心数据冲突等问题
缺点:
- 资源占用:大部分时间内,备份集群什么工作都不会处理
3. MirrorMaker
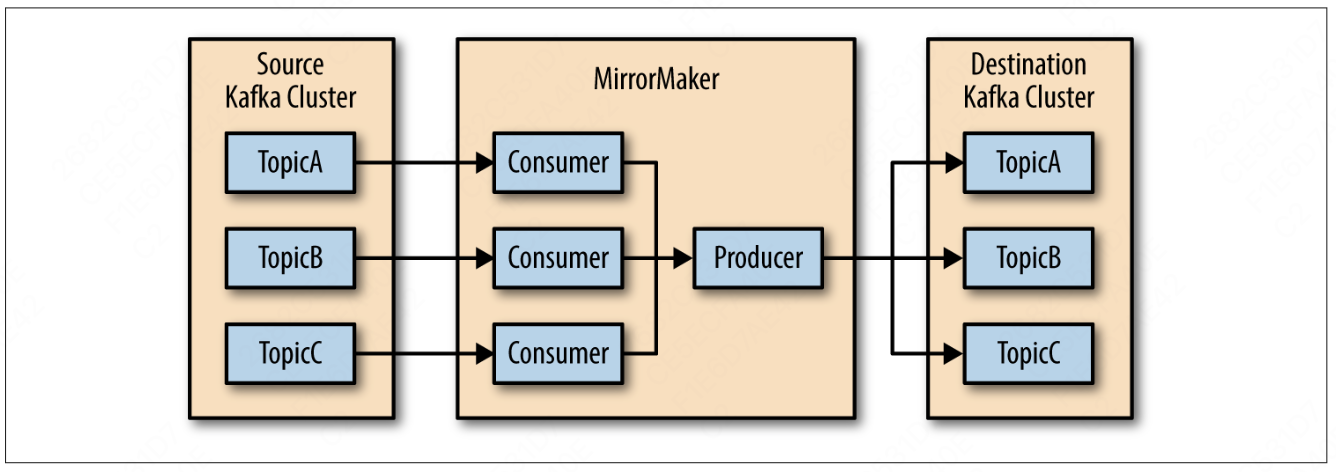
Kafka 提供了一个简单的工具,用于在两个数据中心间镜像数据,这个工具是 MirrorMaker。
- MirrorMaker 包含一组消费者,同属一个消费者群组,用于从主题上读取数据
- MirrorMaker 包哈一个单独的生产者
镜像流程:
- MirrorMaker 为每个消费者分配一个线程,消费者从源主题分区上读取数据
- 消费者通过公共的生产者将数据发送到目标集群上,并等待目标集群的确认
- 目标集群确认后,消费者再通知源集群提交这些消息的偏移量(保证不丢失消息,但是可能会少量重复)