Linux Kernel: Process Address Space
1-概述
操作系统在对进程进行内存分配时,会根据进程的状态有不同的处理方式。
- 进程处于内核态,则立即分配内存;并且假定所有的内存分配函数都不会产生错误(信任内核)
- 进程处于用户态,则推迟动态内存的分配;用户进程时不可信任的,分配过程可能会产生异常
关于两种状态下内存分配时机的不同出于以下原因:
- 内核时操作系统中优先级最高的成分。如果内核请求动态内存,则必定有充分的理由,所以应该立即满足该请求
- 用户态进程对内存的请求被认为是不紧迫的。当进程获得动态内存之后,并不意味着很快会对这些内存进行访问;因此,内核一般总是尽量推迟给用户态进程分配动态内存
内核如何实现对进程动态内存的推迟分配?当用户态进程请求动态内存时,并没有获得请求的页框,而仅仅获得对一个新的线性地址区间的使用权,而这以线性地址区间就成为进程地址空间的一部分,该区间叫做线性区(memory region)。
2-进程的地址空间
进程的地址空间(address space)由允许进程使用的全部线性地址组成。每个进程看到的线性地址集合是不同的,一个进程所使用的地址与另一个进程所使用的地址之间没有关系。
内核可以通过增加或者删除某些线性地址区间来动态地修改进程的地址空间。
每个进程的地址空间是整个虚拟地址空间的子集
内核通过线性区资源来表示线性地址区间,线性区由起始线性地址,长度及一些访问权限来描述。
线性区的起始地址与长度必须是 4096 的倍数,使得每个线性区所识别的数据能够完全填满分配给它的页框
进程获取新的线性区一些典型情况
- 控制台输入一条命令,Shell 进程创建新的进程区执行该命令,从而使新的地址空间分配给了新的进程
- 正在运行的进程装入一个新的程序,这种情况下该进程之前所使用的线性区被释放,并且新的线性区被分配给该进程(exec() 函数的执行)
- 正在运行的进程对一个文件执行内存映射,此时内核会给该进程分配一个新的线性区来映射该文件
- 进程的用户态堆栈被耗尽,需要扩展该线性区的大小
- 进程创建一个 IPC 共享线性区与其他进程共享数据,这种情况下,内核给该进程分配一个新的线性区来实现
- 进程主动调用 malloc() 函数扩展自己的动态区

创建,删除线性区相关系统调用
内核需要确定一个线程当前所拥有的线性区(即进程地址空间),以便能够区分两种不同的无效线性地址:
- 由编程错误引发的无效线性地址
- 由缺页引发的无效线性地址:即使该线性地址属于进程的地址空间,但是对应于这个地址的页框仍然待分配
3-内存描述符
与进程地址空间相关的全部信息都包含在内存描述符(memory descriptor)中,内存描述符又被进程描述符所引用;内存描述符类型为 mm_struct。
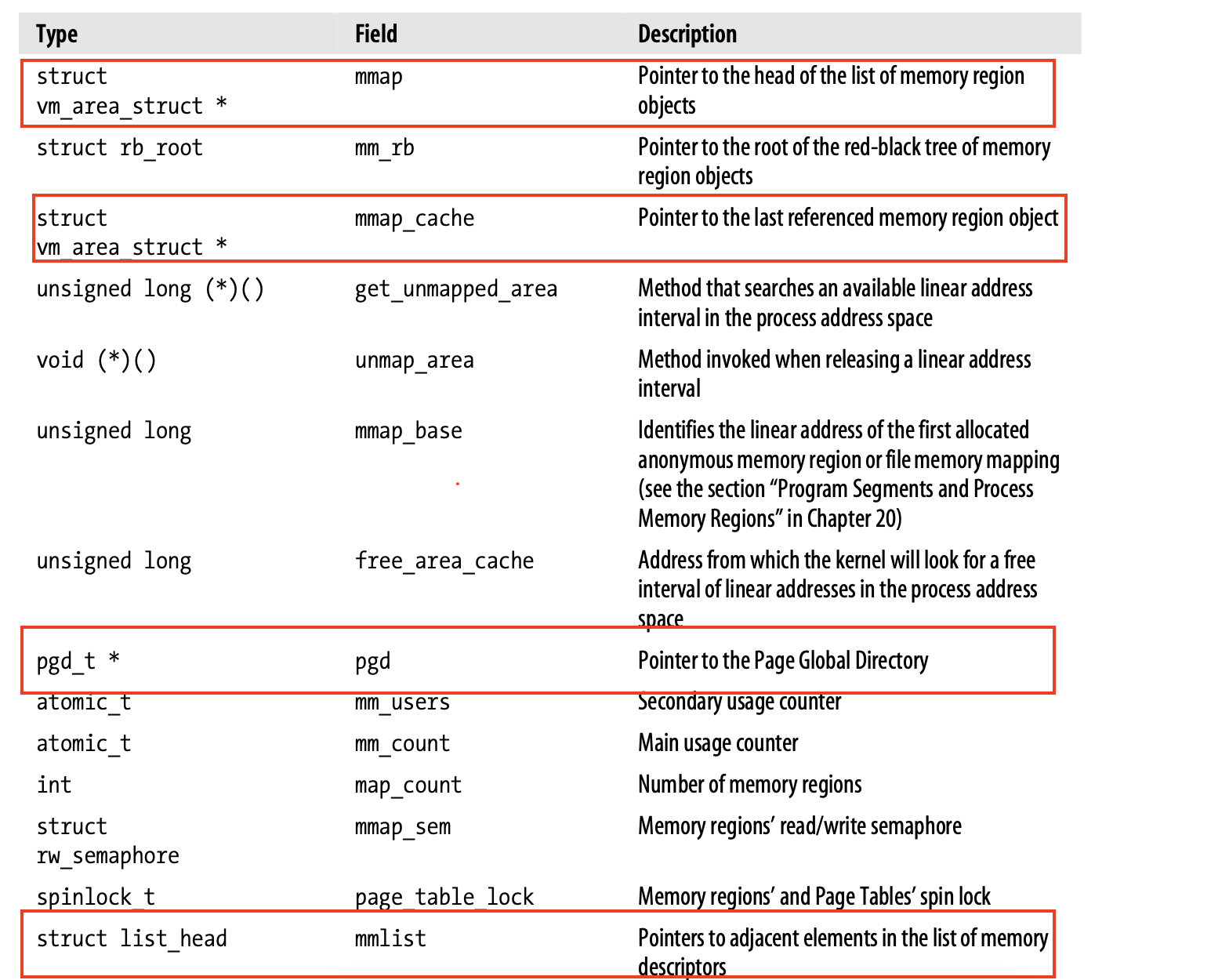
- mmap 字段指向线性区对象的链表头
- mmap_cache 指向队后一次引用的线性区对象
- pgd 指向页全局目录
- map_count 表示线性区的个数
- mmlist 指向内存描述符链表中的相邻元素
- mlist
所有进程的内存描述符存放在一个双向链表中,每个内存描述符中的 mmlist 字段存放了链表相邻元素的地址。其中链表的第一个元素是 init_mm 的 mmlist 字段,而 init_mm 是初始化阶段进程 0 所使用的内存描述符。
为了实现多处理器对内存描述符链表的安全访问,引入了自旋锁
4-线性区
在内存描述符中 mmap 指向线性区对象的链表头,类型为 vm_area_struct;该类型表示的数据结构为线性区描述符,每个线性区描述符表示一个线性地址空间。vm_area_struct 类型的一些关键字段:
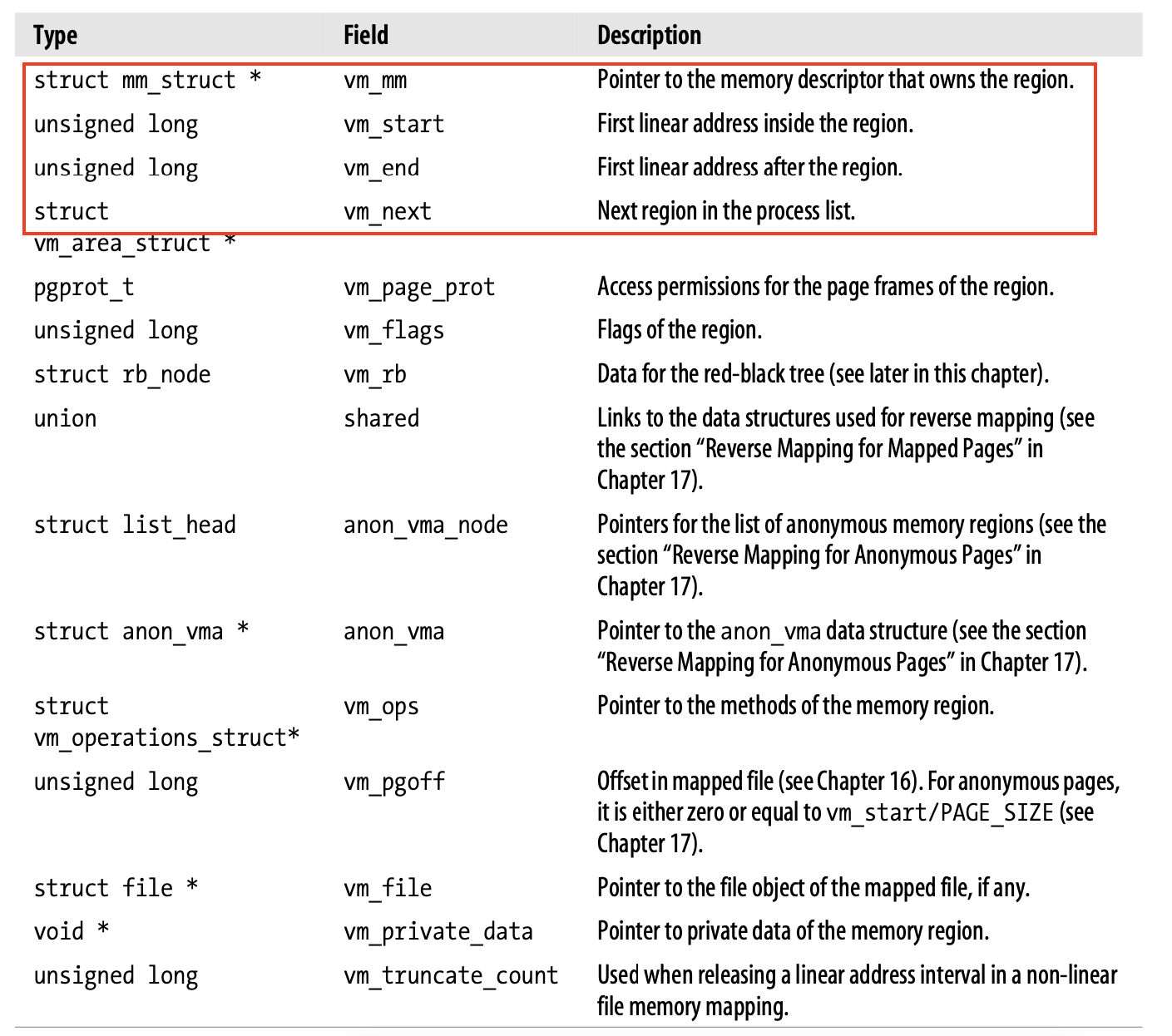
- vm_mm 字段指向拥有该区间的进程的内存描述符
- vm_start 表示该区间包含的第一个线性地址
- vm_end 表示该区间之外的第一个线性地址;所以 vm_end - vm_start 表示线性区的长度
- vm_next 表示进程拥有的线性区链表的下一个线性区
进程拥有的线性区从不重叠,并且内核尽量把新分配的线性区与紧邻的现有线性区进行合并。
如果两个相邻区的访问权限匹配,则这两个线性区可以被合并
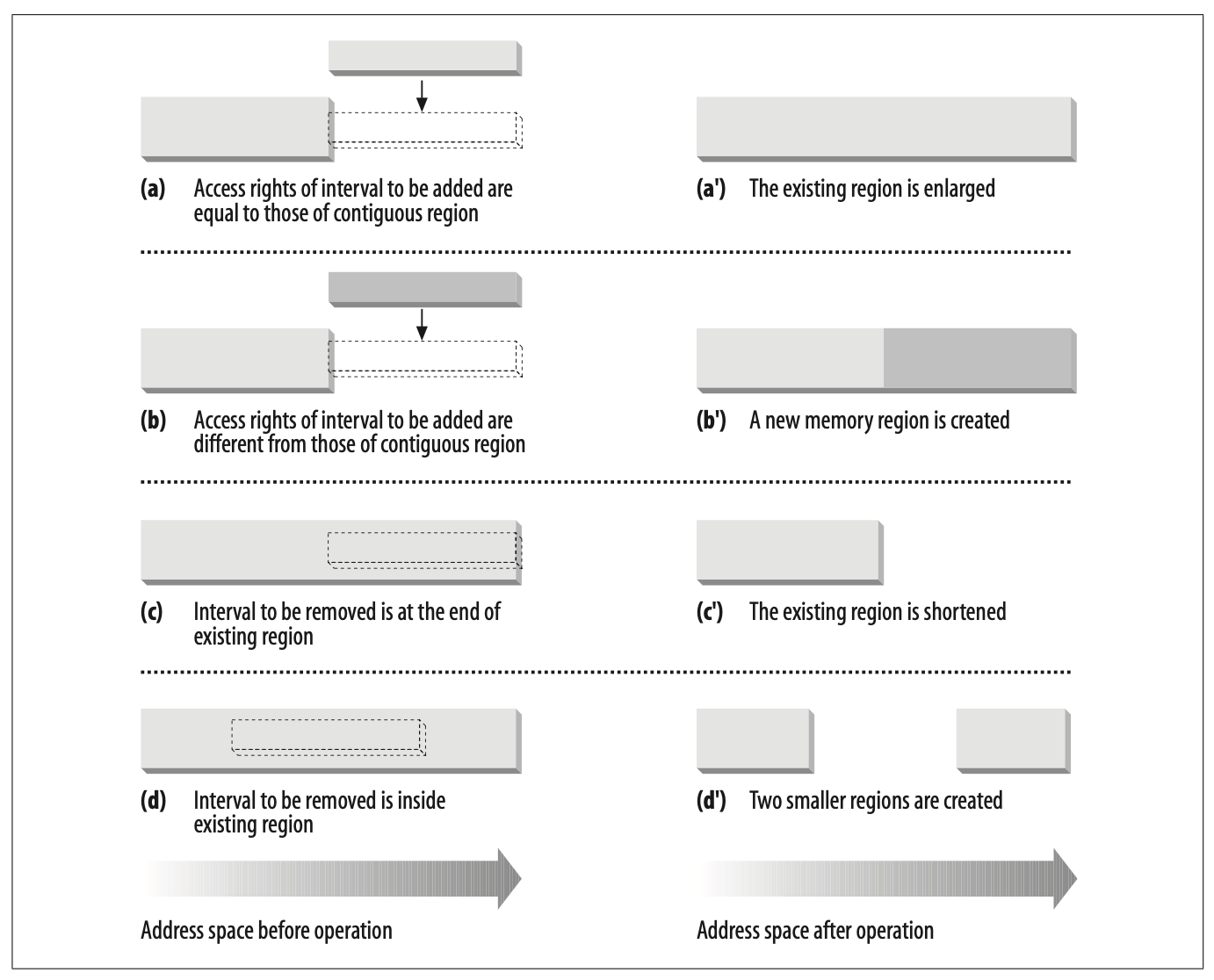
- 新的线性区加入到进程的地址空间时,内核将其与一个已经存在的线性区进行合并扩大
- 如果不能合并,则创建一个新的线性区
- 从进程的地址空间中删除一个线性地址空间,调整线性区的大小
- 删除一个线性地址空间后,可能会导致一个线性区变成两个比较小的线性区
4-1 线性区数据结构
进程拥有的线性区通过链表链接在一起,并按照内存地址升序排列。链表中前后两个线性区并不一定保持线性地址的连续,中间可以由未使用的地址分隔开。
内核通过进程的内存描述符的 mmap 字段查找线性区,该字段指向链表中第一个线性区描述符;内存描述符中的 mmap_count 表示进程拥有的线性区数目,默认最大数目为 65536
进程的地址空间,内存描述符及线性区链表之间的关系如下:
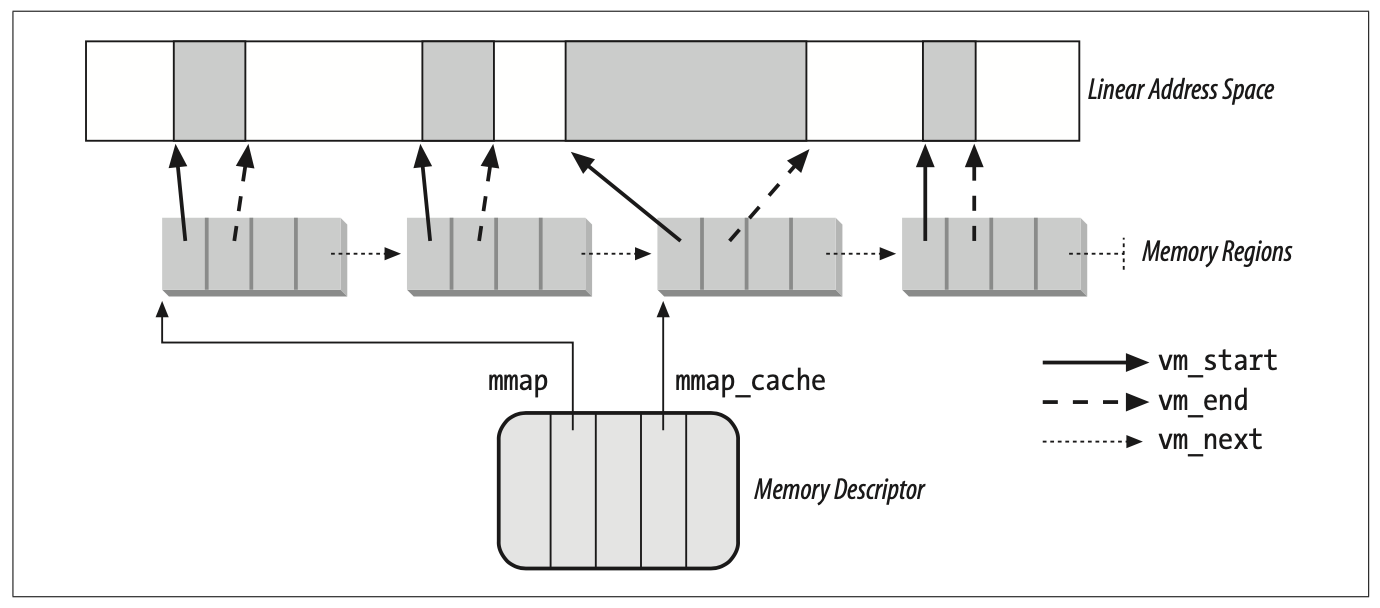
内核需要经常判断一个线性地址属于哪个线性区。如果通过查找有序线性区链表的话,需要从首个线性区进行扫描,直到找到包含该线性地址的线性区,时间复杂度为 O(n)。
为了加速该查询动作,Linux 还使用红黑树存放进程的线性区;所以线性区的保存存在两种方式:链表 & 红黑树。一般来说,红黑树用来判断一个线性地址的线性区,链表用来扫描整个线性区集合。
4-2 页与线性区
页既表示一组连续的线性地址,也表示这组地址中所存放的数据;页的大小一般为 4KB,其中 0~4095 之间的的线性地址区间称为第 0 页,依此类推。
线性区由一组号码连续的页组成,起始地址与长度均为 4096 的倍数。
4-3 线性区访问权限
页相关的标志有三种:
- 每个页表项中存放的标志:read&write, present, user&supervisor
- 存放在每个页描述符 flags 字段中的一组标志
- 线性区中与页有关的标志,存放在线性区描述符中的 vm_flags 字段中;用于给内核提供有关这个线性区全部页的信息

5-缺页异常处理
缺页异常处理程序需要区分由编程错误引起的缺页异常,与引用属于进程地址空间但尚未分配物理页框的页所引起的异常。
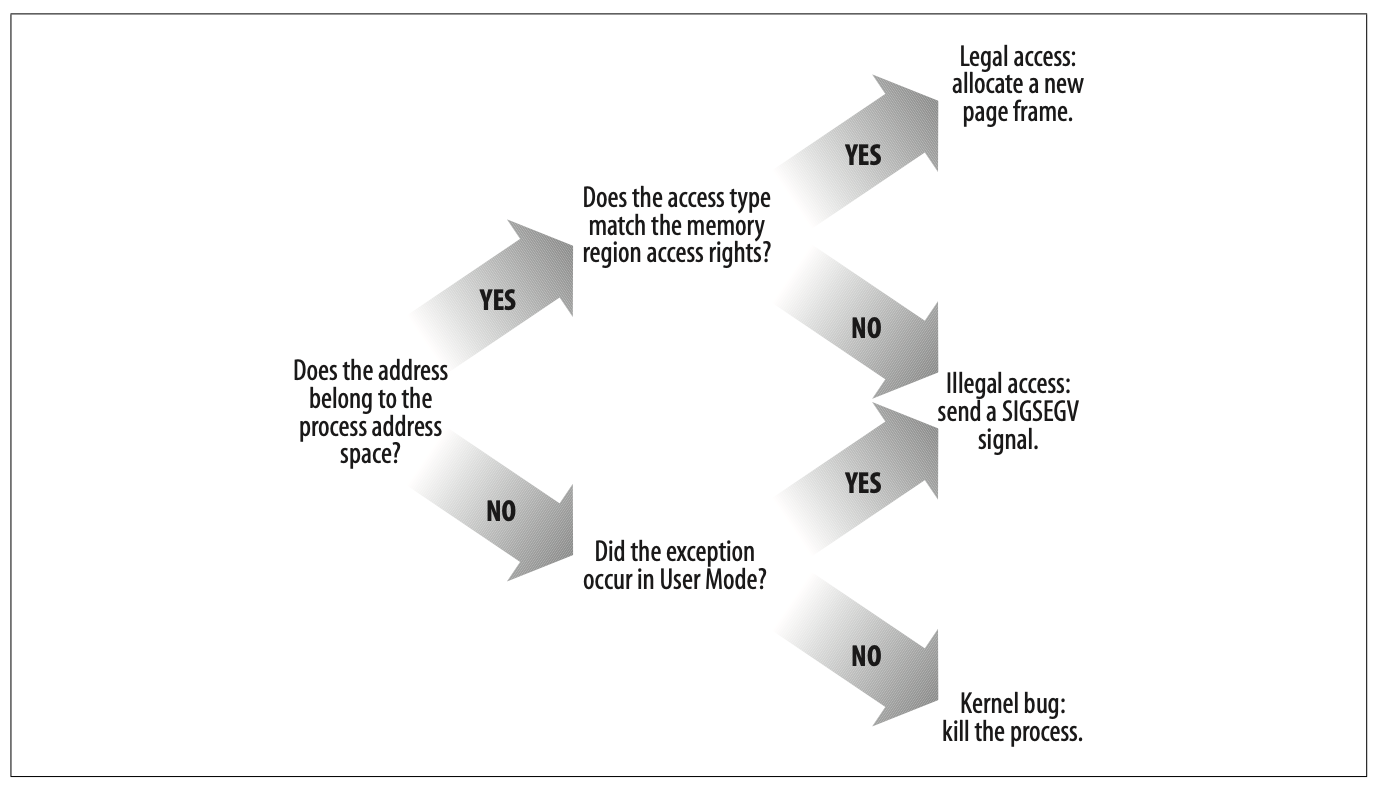
5-1 请求调页
请求调页指的是一种动态内存分配技术,把页框的分配推迟到不能再推迟为止。
一直推迟到进程要访问的页不在 RAM 中时为止,由此引起缺页异常
请求调页背后的原因是:
- 进程开始运行时并不访问其地址空间中的全部地址(有时候有些地址永远没有被访问)
- 由于程序的局部性原理保证了程序在执行的每个阶段,真正引用的进程页只有一小部分,因此临时用不着的页所在的页框可以由其他进程所使用
请求调页技术增加了系统中空闲页框的平均数,更好地利用了空闲内存,并且提高了系统的吞吐量。
不过,请求调页也带来了额外的开销:
- 请求调页引发的缺页中断必须由内核处理,浪费了 CPU 的周期
不过,缺页中断的概率比较小
被访问的页不在主存中的原因可能是进程从未访问过该页,或者该页对应的页框已经别内核回收了。
5-2 写时复制
当 fork() 系统调用触发时,会创建一个子进程。Linux 之前的实现是将父进程的地址空间原样复制一份分配给子进程。该复制操作耗时比较大。
现在的 Linux 内核采用写时复制(copy on write)技术实现:父进程与子进程共享页框而不是复制页框;当页框被共享时,不能被修改。无论子进程还是父进程如果尝试写一个共享的页框,会产生一个异常,此时,内核会把这个页复制到一个新的页框中并标记为可以写。原来的页框仍然是写保护:当其他进程试图写入时,内核检查写进程是否是该页框的唯一属主,如果是,则把该页框标记为对这个线程是可写的。
6-堆管理
每个 Linux 进程都拥有一个特殊的线性区,即所谓的堆(heap)。堆用于满足进程的动态内存请求。
进程可以使用以下 API 实现请求释放动态内存:
malloc(size) // 请求 size 个字节的动态内存;如果分配成功则返回分配内存的第一个字节的线性地址
free(addr) // 释放 malloc 分配的起始地址为 addr 的线性区
brk(addr) // 直接修改堆的大小,返回线性区的新的结束地址