Linux Kernel: Processes
进程被定义为程序执行的一个实例。在 Linux 中,通常把进程称为任务(task)或者线程(thread)。
如果有 n 个用户同时运行 vim 命令,那么就会有 n 个独立的进程;尽管它们共享同一个可执行代码
1-进程 & 轻量级进程 & 线程
从内核角度来看,进程是系统资源(CPU 时间,内存等)分配的实体。
当一个进程创建时,几乎与父进程相同。子进程接受父进程地址空间的一个逻辑拷贝,并从进程创建系统调用的下一条指令开始执行与父进程相同的代码。尽管父子进程可以共享含有程序代码的页,但是它们有各自独立的数据拷贝(堆 & 栈),因此,子进程对一个内存单元的修改对父进程是不可见的(反之亦然)。
父子进程的地址空间采用 copy on write 机制
现代 Unix 系统支持多线程应用程序:一个进程由几个用户线程组成,每个线程都代表进程的一个执行流。
大部分多线程应用程序都是基于 POSIX thread 标准库实现
从 Linux 内核来看,多线程应用程序仅仅是一个普通的进程。多线程应用程序多个执行流的创建,处理,调度等都是在用户态进行的。这种实现方式存在不足:假设一个应用进程中存在两个线程,A 线程在执行部分流程之后需要暂停执行,并等待 B 线程的执行结果。如果 A 线程只是简单的触发阻塞系统调用,试图将 CPU 交给 B,那么 B 线程也会被阻塞(它们同属于一个进程)。相反,A 线程必须使用比较复杂的非阻塞技术来确保进程仍然是可运行的。
Linux 使用轻量级进程(lightweight process)来实现对多线程应用程序更好的支持。两个轻量级进程基本上可以共享一些资源,如地址空间,打开的文件等。只要其中一个轻量级进程修改了共享资源,另一个就能立即查看这种修改。
实现多线程应用程序的一个简单方式就是把轻量级进程与每个线程关联起来。线程之间可以通过简单共享同一内存地址空间,同一打开文件集等来访问相同的应用程序数据结构集;同时,每个线程都可以由内核单独调度,以便阻塞一个线程的同时,另一个线程仍然是可运行的。
2-进程描述符
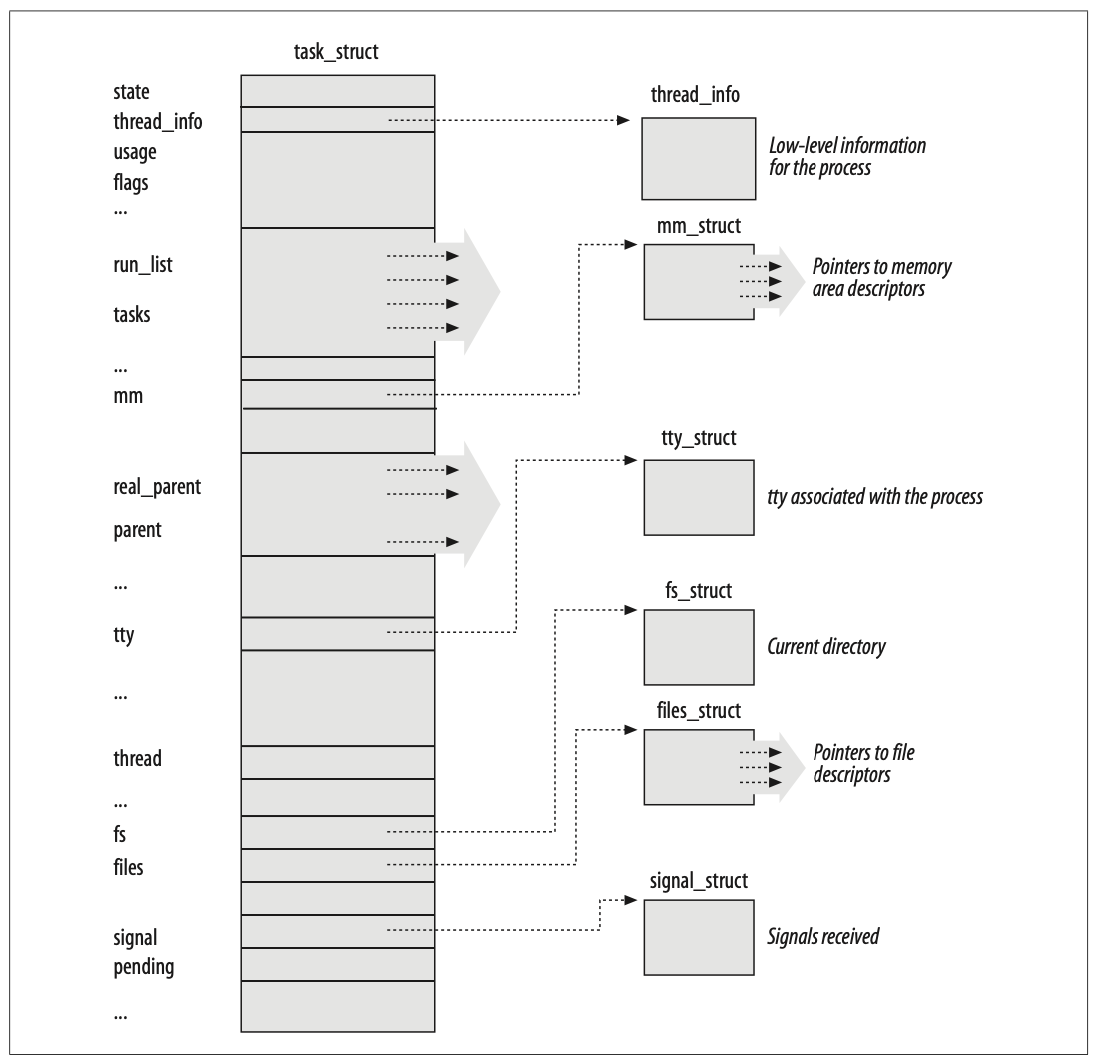
进程描述符包含了与进程相关的所有信息,类型为 task_struct。
2-1 进程状态
进程描述符中的 state 字段标识了进程当前所处的状态(某一时刻只能处于一种状态下)。
- 可运行状态(TASK_RUNNING)
- 进程要么正在 CPU 上执行,要么准备执行
- 可中断的等待状态(TASK_INTERRUPTIBLE)
- 进程被挂起(休眠),直到某个条件变成真。产生一个硬件中断,释放进程正等待的系统资源或者传递一个信号都可以是唤醒进程的条件(进程的状态被重新置为 TASK_RUNNING)
- 不可中断的等待状态(TASK_UNINTERRUPTIBLE)
- 与可中断的等待状态蕾西,但是有一点不同,把信号传递到休眠进程并不能改变进程的状态(该状态只会在一些特定的情况下使用)
- 暂停状态(TASK_STOPPED)
- 进程的执行被暂停:当进程收到 SIGSTOP, SIGTSTP, SIGTTIN or SIGTTOU 信号后,进入暂停状态
- 跟踪状态(TASK_TRACED)
- 进程的执行已由 debugger 程序暂停
- 僵死状态(TASK_ZOMBIE)
- 进程的执行被终止,但是父进程还没有发布 wait4() or waitpid() 系统调用来返回有关死亡进程的信息
- 僵死撤销状态(EXIT_DEAD)
- 最终状态:由于父进程刚发出 wait4() or waitpid() 系统调用,因而进程被系统删除
2-2 标识进程
一般来说,每个能够被独立调度的执行上下文都必须拥有它自己的进程描述符。
即使是轻量级进程也有 task_struct 结构
进程与进程描述符之间一一对应,因此常用 32 位的进程描述符地址(线性地址)标识一个进程。
进程描述符指针指向该地址
此外,Unix 操作系统还使用进程标识符 processID(PID)来标识进程,PID 存放在进程描述符的 pid 字段中。
PID 被顺序编号,并且被循环使用
Linux 把不同的 PID 与系统中的每个进程或者轻量级进程相关联;同时 Unix 希望同一组中的线程有共同的 PID(一个多线程应用程序的所有线程拥有相同的 PID)。因此,Linux 引入线程组的方式,一个线程组的所有线程使用和该线程组的领头线程(thread group leader)相同的 PID,即该组中的第一个轻量级进程的 PID,被存放在进程描述符中的 tgid 字段中。
一个多线程应用的所有线程共享同一个 PID
2-2-1 进程描述符处理
内核把进程描述符存放在动态内存中,而不是分配给内核的内存区。对每个进程,Linux 都把两个不同的数据结构紧凑地存放在一个单独为进程分配的存储区域内:1. 与进程描述符相关的小数据结构 thread_info,线程描述符; 2. 内核态的进程堆栈。这块存储区域通常占据两个页框。
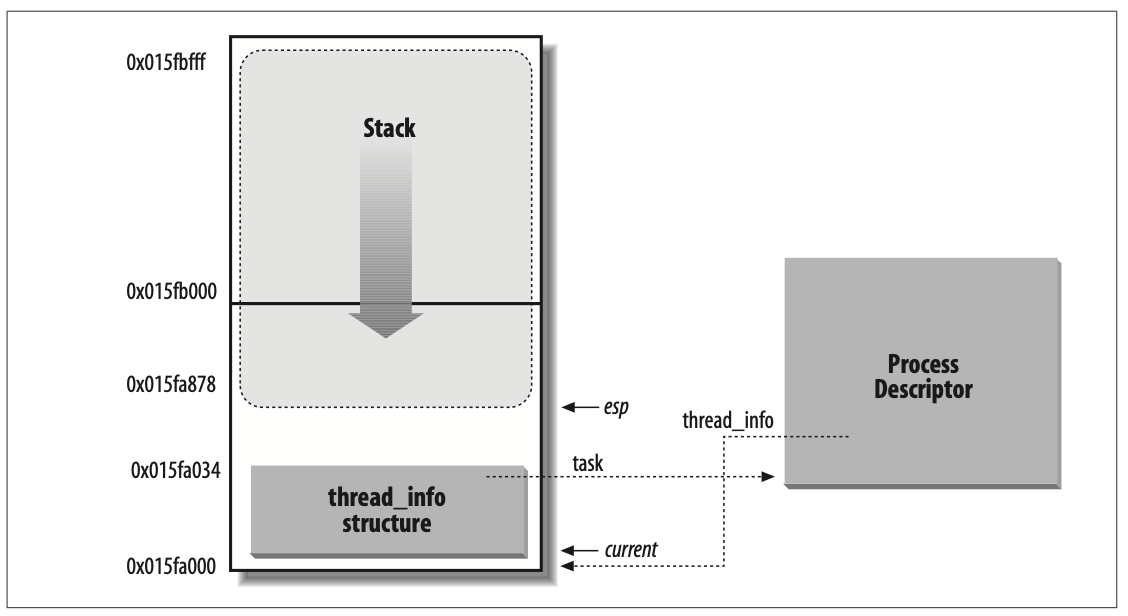
分别通过 task 与 thread_info 字段使 thread_info 结构与 task_struct 结构互相关联
2-2-2 进程链表
进程链表是一个双向链表,如下图:
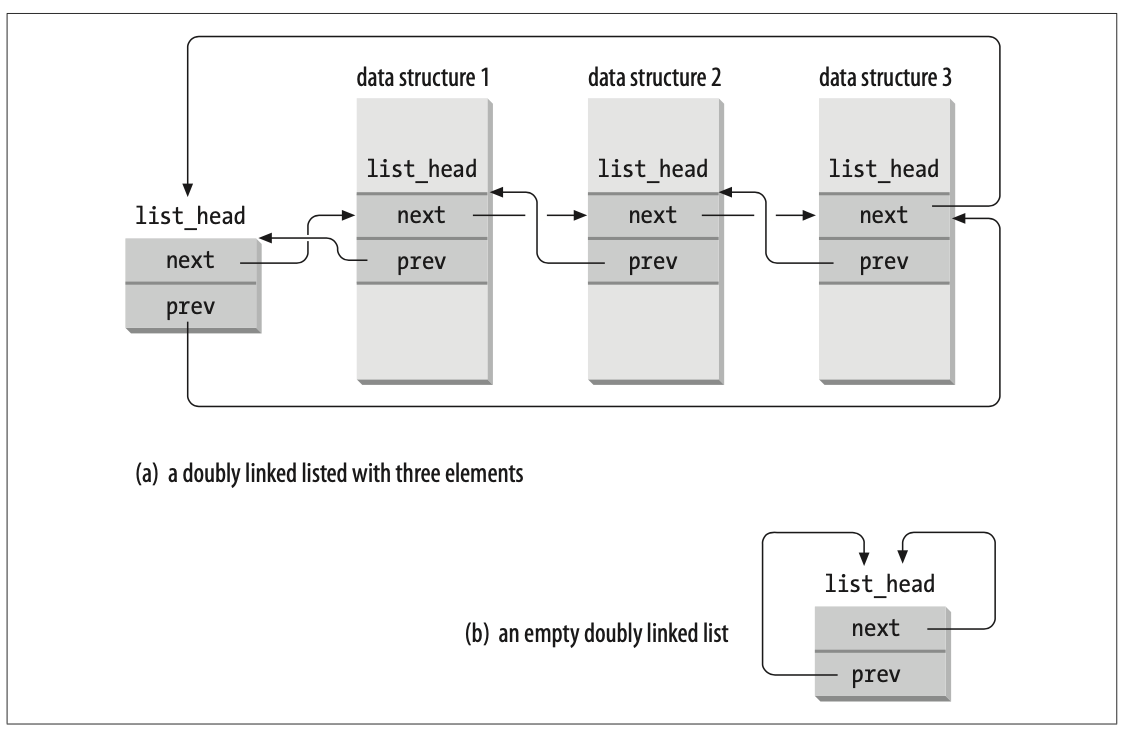
进程双向链表把所有的进程描述符链接起来;每个 task_struct 结构都包含一个 list_head类型的 tasks 字段,该类型的 pre & next 字段分别指向前面和后面的 task_struct 元素。
进程链表的头是 init_task 描述符,它是 0 进程的进程描述符
2-2-3 TASK_RUNNING 状态的进程链表
当内核试图切换新的进程在 CPU 上运行时,必须只考虑可运行进程(即处在 TASK_RUNNING 状态的进程)。
早期的 Linux 版本把所有可运行的进程都放在同一个运行队列中,导致维护链表中的进程按照优先级排序开销过大。Linux 2.6 实现的运行队列期望调度程序能够在固定的时间内选出最佳可运行的进程(与队列中可运行的进程数无关)。
为了实现该目的,建立多个可运行进程链表,每种进程优先权对应一个不同的链表。
一共有 140 个不同的队列
2-3 进程间的关系
程序创建的进程具有父子关系,一个父进程的多个子进程之间具有兄弟关系。
进程 0 和进程 1 是由内核创建的,进程 1 (init)是所有进程的祖先
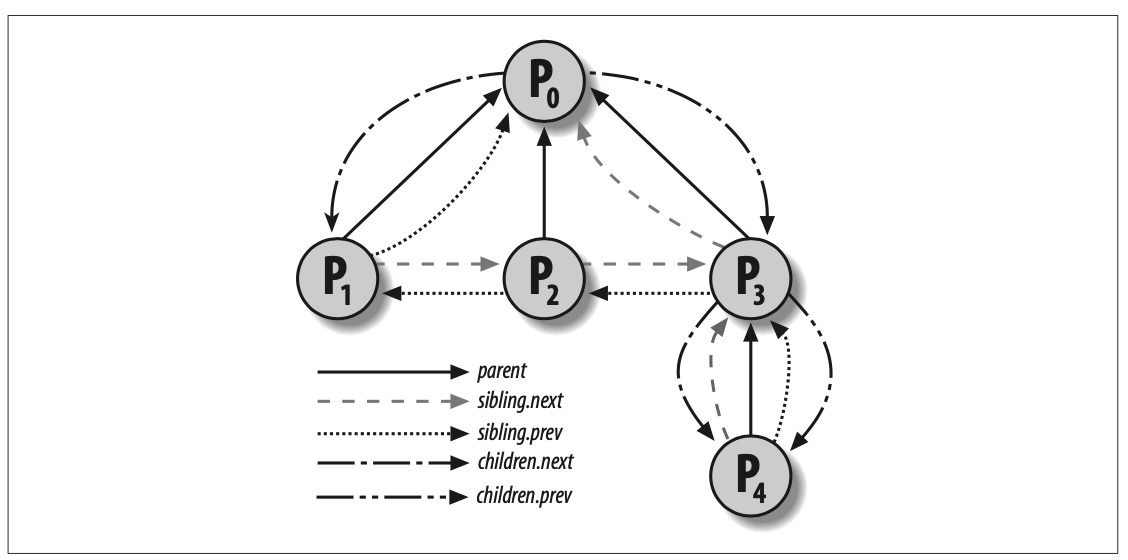
进程之间还存在其他关系:
- 一个进程可能是一个进程组或者登录会话的领头进程
- 也可能是一个线程组的领头进程
- 也可能跟踪其他进程的执行
2-4 如何组织进程
Linux 对不同状态的进程有不同的组织方式:
- 运行队列链表把处于 TASK_RUNNING 状态的所有进程组织在一起
- 没有为 TASK_STOPPED, EXIT_ZOMBIE 和 EXIT_DEAD 状态的进程专门建立链表:对这些状态的进程访问比较简单
- 根据不同的特殊事件把处于 TASK_INTERRUPTIBLE 和 TASK_UNINTERRUPTIBLE 状态的进程细分为很多类别,每一类都对应一个特殊的事件
2-4-1 等待队列
进程必须经常等待某些事件的发生,例如,等待一个磁盘操作的终止,等待释放系统资源或者等待事件经过固定的间隔;等待队列实现了在事件上的条件等待:希望等待特定事件的进程把自己放进合适的等待队列中,并放弃控制权。因此,等待队列表示一组休眠的进程,当某一条件变成真时,由内核唤醒它们。
等待队列在中断处理,进程同步及定时方面由很大作用
等待队列也是由双向链表实现,其元素包括指向进程描述符的指针。每个等待队列都有一个等待队列头(wait queue head),而等待队列头是一个类型为 wait_queue_head_t 的数据结构:
struct __wait_queue_head {
spinlock lock; // 自旋锁
struct list_head task_list; // 双向链表:等待进程链表的头
}
等待队列是由中断处理程序和一些内核函数修改的,因此必须对其双向链表进行保护以避免并发带来的异常。同步操作是通过等待队列头中的自旋锁实现的。
等待队列链表中的元素类型为 wait_queue_t:
struct __wait_queue {
unsigned int flags;
struct task_struct *task; // 进程描述符
wait_queue_func_t func;
struct list_head task_list;
}
等待队列中的每个元素代表一个休眠的进程,该进程等待某一事件的发生;进程描述符地址存放在 task 字段中;task_list 字段表示等待相同事件的进程链表;func 字段表示进程应该用什么方式唤醒。
等待队列中的进程有两种类型:
- 互斥进程(flags = 1):由内核有选择地唤醒
- 如等待访问临界区资源的进程
- 非互斥进程(flags = 0):总是在内核事件发生时唤醒,即一次会唤醒全部非互斥进程
- 比如等待磁盘传输结束的一组进程,一旦磁盘传输完成,所有等待进程都会被唤醒
2-4-2 等待队列的操作
通过调用特定函数(add_wait_queue(), add_wait_queue_exclusive() 等)可以把进程添加到等待队列或者从等待队列中移除(remove_wait_queue())
需要等待某个条件的进程可以调用以下函数将自己添加到等待队列中:
-
sleep_on():该函数把当前进程的状态设置为 TASK_UNINTERRUPTIBLE,并把它插入到特定的等待队列。之后,它调用调度程序,而调度程序重新开始另一个程序的执行。当休眠的进程被唤醒时,调度程序重新开始执行 sleep_on() 函数,把该进程从等待队列中删除
void sleep_on(wait_queue_head_t *wq){ wait_queue_t wait; init_waitqueue_entry(&wait, current); current_state = TASK_UNINTERRUPTIBLE; add_wait_queue(wq, &wait); //插入等待队列的头部 schedule(); // 调用调度程序执行其他进程 remove_wait_queue(wq, &wait); // 被唤醒后重新执行 } -
interruptible_sleep_on():与 sleep_on() 函数一样,只不过是把进程的状态设置为 TASK_INTERRUPTIBLE;因此,接受一个信号就可以唤醒当前进程
-
sleep_on_timeout() & interruptible_sleep_on_timeout() 与上面的函数类似,但是允许调用者定义一个时间间隔,过了这个时间间隔之后,进程将由内核唤醒。为了实现该功能,这两个方法调用的时 schedule_timeout() 函数而不是 schedule() 函数
-
prepare_to_wait(), prepare_to_wait_exclusive() 和 finish_wait() 函数提供了另一种途径使得当前进程在一个等待队列中休眠;典型用法如下:
prepare_to_wait_exclusive(&wq, &wait, TASK_INTERRUPTIBLE); ... if(!condition) schedule(); finish_wait(&wq, &wait); // 进程被唤醒后从该处执行 -
wait_event() & wait_event_interruptible() 使得调用进程在等待队列上休眠,直到修改了给定条件为止
内核通过调用以下函数将等待队列中的进程唤醒并把状态设置为 TASK_RUNNING
-
wake_up():扫描等待队列中的所有进程,并通过 func 字段试图唤醒进程。该函数总是先唤醒非互斥进程,再唤醒互斥进程:非互斥进程位于双向链表的开始位置
void wake_up(wait_queue_head_t *q){ sturct list_head *tmp; wait_queue_t *curr; list_for_each(tmp, &q->task_list){ if(cur->func(curr, TASK_INTERRUBPIBLE|TASK_UNITERRUPRIBLE, 0, NULL) && curr->flags) break; } } -
wake_up_all() & wake_up_nr() 等方法
一个等待队列中同时包含互斥进程与非互斥进程的情况很罕见
2-5 进程资源限制
每个进程都有一组相关的进程资源限制(resource limit),限制指定了进程能够使用的系统资源数量。
- RLIMIT_AS: 进程地址空间的最大数(字节为单位)
- RLIMIT_RSS: 进程所拥有的页框最大数
- RLIMIT_CPU: 进程使用 CPU 的最长时间(秒为单位)
- RLIMIT_DATA: 堆大小的最大值
- RLIMIT_STACK: 栈大小的最大值(字节为单位)
- RLIMIT_NOFILE: 打开文件描述符的最大值
- RLIMIT_SIGPENDING: 进程挂起信号的最大数
- RLIMIT_NPROC: 用户能够拥有的进程最大数
3-进程切换
为了控制进程的执行,内核必须能够挂起正在 CPU 上运行的进程,并恢复以前挂起的摸个进程的执行;这种行为被称为进程切换(process switch)或者上下文切换(context switch)。
3-1 硬件上下文
每个进程可以拥有自己的地址空间,但是所有进程需要共享 CPU 寄存器。因此,在进程恢复运行之前,需要确保每个寄存器装入了挂起进程的值;这组数据被称为硬件上下文(hardware context)。
硬件上下文是进程可执行上下文的子集
在 Linux 中,进程硬件上下文的一部分存放在 TSS 段(Task State Segment,任务状态段),而剩余部分存放在内核态堆栈中。
进程切换只发生在内核态。在执行进程切换之前,用户态进程使用的所有寄存器内容已保存在内核态堆栈上。
3-2 执行进程切换
进程切换只能发生在 schedule() 函数中;每个进程切换由两步组成:
- 切换页全局目录以安装一个新的地址空间
- 切换内核态堆栈和硬件上下文(硬件上下文提供了内核执行新进程所需要的素有信息,包含 CPU 寄存器)
4-创建进程
传统的 Unix 操作系统以统一的方式对待所有进程:子进程复制父进程所拥有的资源。这种效率比较低,因为子进程需要拷贝父进程所有的地址空间,实际上,子进程几乎不必读或者修改父进程所拥有的资源;在很多情况下,子进程立即调用 execve(),并清除父进程拷贝过来的地址空间。
现代 Unix 内核通过引入三种不同的机制解决这个问题:
- 写时复制(copy on write)技术允许父子进程读取相同的物理页。只要两者中有一个试图写一个物理页,内核就把这个页的内容拷贝到一个新的物理页,并把这个新的物理页分配给正在写的进程。
- 轻量级进程允许父子进程共享每进程在内核的很多数据结构,如页表(用户态地址空间),打开的文件表及信号处理。
- vfork() 系统调用创建的进程能共享其父进程的内存地址空间。为了防止父进程重写子进程所需要的数据,阻塞父进程的执行,直到子进程退出或执行一个新的程序为止。
4-1 相关系统调用
- clone(): 轻量级进程是由 clone() 函数创建
- 传统的 fork() 调用是用 clone() 实现的,不过对于一些标志都清除
- vfork() 也是用 clone 实现,也是一些参数的不同
4-2 内核线程
一些系统进程只运行在内核态,所以现代操作系统把它们的函数委托给内核线程(kernel thread)。内核线程用于执行一些周期性的任务:刷新磁盘高速缓存,交换出不用的页框,维护网络连接等。内核线程不受不必要的用户态上下文的拖累;在以下方面不同于普通进程:
- *内核线程只运行在内核态*,而普通进程既可以运行在用户态,也可以运行在内核态
- 因为只运行在内核态,所以只使用大于 PAGE_OFFSET 的线性地址空间。而普通进程不管是处于用户态还是内核态,可以使用 4GB 的线性地址空间。
4-2-1 进程 0
所有进程的祖先叫做进程 0,它是在 Linux 的初始化阶段从无到有创建的一个内核线程。
4-2-2 进程 1
由进程 0 创建的内核线程执行 init() 函数,init() 依次完成内核初始化。
5-撤销进程
进程终止一般是调用 exit() 函数,用于释放所分配的资源。
- exit_group(): 终止整个线程组,即基于多线程的应用
- exit(): 终止某个线程