Lion: Multi-Region Data Synchronization
1、文档概述
1.1 项目背景
Lion 目前部署在北京,上海两侧数据中心,北上两地双向同步。对于未来怀来,香港或者其他数据中心的规划,Lion 暂不支持其他数据中心的数据同步。
短期内可以通过 Region 内流量闭环,数据访问仍使用北上两地数据中心的方案临时支持,长期需要探索支持多数据中心同步功能。
1.2 项目目标
- 支持多数据中心间数据同步(同步方向可自定义设置)
- 同一 Region 内数据和流量闭环
1.3 名词解释
| 名词 | 解释 |
|---|---|
| DTS | 美团内部一种集数据订阅、数据同步、数据迁移于一体的数据传输服务 |
| DRC | 饿了么数据复制中心 |
| MGR | MySQL 组复制 |
| Lion | 美团内部配置统一管理和实时推送的平台 |
| Lion Consistency | Lion 系统内负责数据同步模块 |
| Lion Manager(新增) | Lion 系统内负责同步任务管理模块 |
| Lion Meta | Lion 系统内负责服务注册发现模块 |
| Lion API/Console | Lion 系统内 Open API 及管理端模块 |
2、整体架构
2.1 技术调研
2.1.1 拓扑结构调研
| 拓扑模型 | 描述 | 比较 | 结论 |
|---|---|---|---|
| 星型拓扑 | 一个指定的根节点将写入转发给所有其他节点 | 优点 1.同步链路保持一定的顺序,数据一致性可以得到提升; 2.运维相对简单。缺点:1.由于数据同步需要通过中间节点转发,中间节点可能会成为性能瓶颈,容易出现单点故障,系统容错降低;2.由于顺序同步,使得整体数据同步延迟会增大(节点数越多,延迟越大) | 采用星型拓扑结构:1.超过2/3的配置变更集中在北京,后续怀来,上海可以以北京为主进行同步;2.以北京为主,在数据冲突,一致性保证方面处理相对简单,包括增量一致性检测功能实现 |
| 全部至全部型(网状型) | 每个主节点将其写入同步到其他所有主节点 | 优点:1.数据同步链路更密集,数据可以沿着不同路径传播,避免了单点故障,容错性更高;2.数据变更全链路广播,整体同步延迟相对更低. 缺点:1.同步链路顺序无法得到保障,数据冲突的情况更复杂(可能所有节点都需要处理冲突);2.运维更加复杂 | - |
2.1.2 同步方案调研
| 业界方案 | 部署架构 | 整体介绍 | 备注 |
|---|---|---|---|
| 美团 DTS | - | 1.Reader 模块与源 DB 同地域部署,从源 DB dump Binlog,并存储在本地内存与磁盘中; 2.Writer 模块与目标 DB 同地域部署,从 Reader 中消费 Binlog,并将数据写入目标 DB 中; 3.Reader 与 Writer 之间通过私有协议实现高速传输;任务调度依赖 Lion 配置下发 | DTS |
| 饿了么 DRC | - | 1.Replicator 模块:用于解析源 DB 的 Binlog,并缓存到一个超大的 Event Buffer 中;同时将解析结果通过 TCP 推动到目标 Applier 模块;2.Applier 模块:接收从 Replicator 推送的数据,并写入到目标 DB 中;3.Console 模块:用于控制管理 | DRC |
DTS 与 DRC 在架构部署上比较类似,有一些共通的地方:
- 读写分离:Binlog 订阅与回放逻辑拆分为两个模块:Reader,Writer,进行读写分离;两个模块可分别按需扩展,提高系统扩展性
- 同地域部署:Reader 模块与源 DB 同地域部署,Writer 模块与目标 DB 同地域部署;Reader 与 Writer 之间通过私有协议高速传输
- 中心化管理:Reader/Writer 涉及的订阅与回放任务分配都是通过中心模块统一调度,而不是由 Reader/Writer 模块分别管理
- Log 打标:为了避免数据回环,对产生的 Log 进行打标,标识地域信息,在回放时进行过滤
对上述几点 Lion 在设计过程中基本都可以借鉴,不过为了简化设计,Reader/Writer 模块不进行拆分,合并部署(不过仍然进行逻辑上角色区分)。
💡 Q:为什么 Lion 不考虑直接接入 DTS ? A:1. DTS 目前所有运维动作、高可用强依赖 Lion,去掉 Lion 强依赖的情况下改造成本高,并且 SLA 无法保证 2. DTS 目前在运维、宕机等场景存在数据回溯,不满 足Lion 低延迟、数据不回退(配置版本回退)要求 3. 如果多中心之间两两互备,DTS 针对这种复杂链路,数据迁移拆分短期没有比较好的解决方
Q:DTS 与 DRC 都是通过 Binlog 订阅传输实现数据复制,Lion 是否也采取该方案? A:Lion 同步数据模型采用自定义 Log 结构。 目前 Lion 北上数据中心间同步使用的是自定义 Log 数据,考虑到引入 MGR Binlog 订阅解析流程并不会对同步流程有显著的提升,并且会提高运维复杂度。 同时,Lion 北上存量数据(Config, Release等表)并不完全一致,暂时无法直接采用 Binglog 进行同步。比如,由于同一条配置在北上最新版本号并不相同,如果从数据库层面强行保持一致,会触发一侧业务重新进行全量配置加载,有较大的风险。 因此,Lion 仍保使用自定义 Log 结构。
2.1.3 推拉选型
这里的推拉模型指的是 Reader 与 Writer 之间传输 Log 的方式:1. Reader 主动将 Log 推送到 Writer;2. Writer 定时从 Reader 按需拉取 Log。
2.2 设计总体思路
2.2.1 部署架构
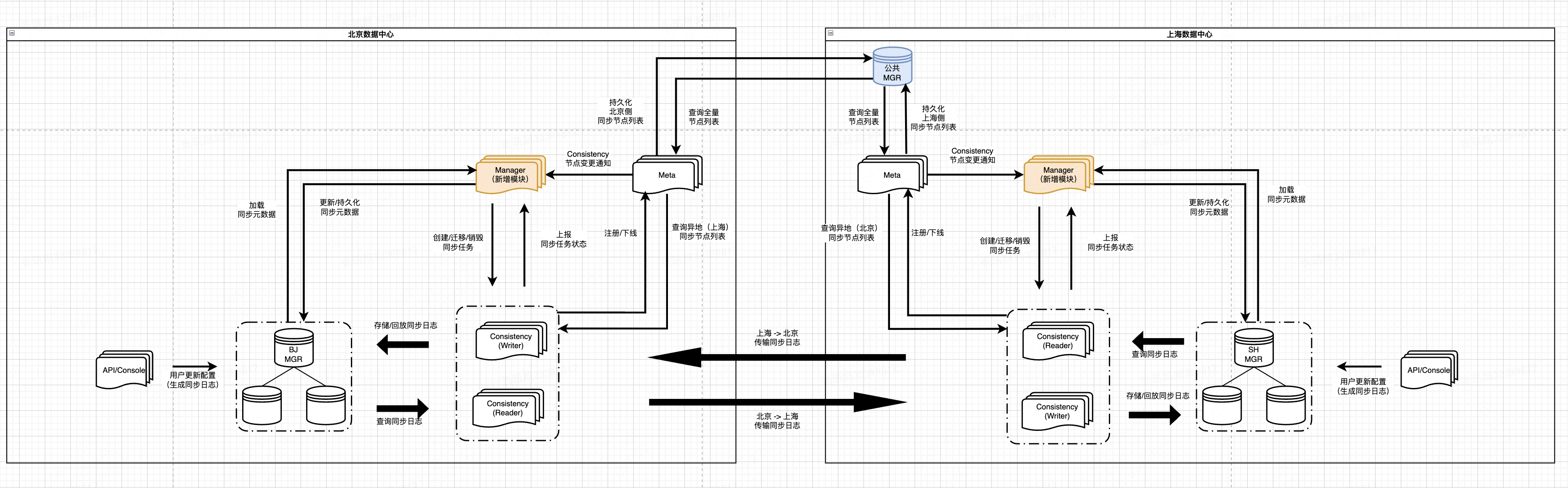
以北京,上海两个数据中心为例,每个数据中心部署了全量的 Lion 服务(部分服务未在图中展示)。通过同步配置变更到其他数据中心,使得每个数据中心拥有全量数据,能够独立提供完整的 Lion 功能。
- MGR (DB):持久化业务配置数据,同步日志,同步任务元数据等信息。MGR 有两种部署模式:
- 每中心单独部署:存储中心内业务数据(如同步任务管理相关元数据),支持中心内流量与数据闭环。不同数据中心的 MGR 数据实时同步,最终每个数据中心拥有全量业务数据。
- 特定中心部署:存储公共数据,便于统一管理(如同步模块节点最新列表),支持不同数据中心的服务进行跨地域访问。只部署在指定数据中心(上海),供所有数据中心进行访问。
- Consistency:执行数据同步任务;每中心单独部署
- 无状态服务;逻辑上划分为 Reader,Writer 两种角色
-
Reader:对外暴露 HTTP API 接口,提供同步日志查询功能
功能很轻量:提供 API 接口供 Writer 访问
- Writer:调用 Reader 接口,实现同步日志在数据中心间传输逻辑;同时完成日志存储,回放等功能。
- 在访问其他数据中心的 Reader 之前,会从 Meta 查询异地数据中心内 Reader 可用节点列表(缓存在本地,定时更新)
- 每个 Writer 任务同步特定分区的日志,并将最新同步偏移量上报到 Manager
- Writer 生命周期由 Manager 进行管理,会周期性上报自身状态
为了提高同步扩展性,将同步日志进行切片,每个 Writer 任务只会同步指定切片的日志。
同步节点 : 同步任务 = 1 : N (每个同步节点上可能会运行多个同步任务)
同步任务 : 同步分区 = 1 : 1 (每个同步任务只会同步一个分区内的日志)
- Manager (新增):用于同步元数据管理,同步任务调度;每中心单独部署
- 管理同步元数据:1. 同步节点(Consistency)与同步分区(Partition)索引的映射关系;2. 同步分区最新同步偏移量(Offset)
- 同步任务调度:1. 在同步节点上,根据分区索引创建对应同步任务;2. 分区索引迁移时,完成同步任务迁移;3. 与同步任务之间维持心跳,确保同步任务处于运行状态
- 每个数据中心内部署多个 Manager 节点,作为同步任务调度的中心模块:
- 与中心内同步节点(Consistency)周期交互:1. 下发同步任务创建/销毁的命令;2. 了解同步任务的运行状态;3. 确定同步任务最新偏移量
- 定时轮询 Meta 节点:查询中心内 Consistency 最新可用节点列表,在节点状态变更时进行同步分区 Rehash 及同步任务迁移
- 从中心内 MGR 加载同步任务元数据;将最新元数据持久化到 MGR
每个 Manager 节点都可以进行任务管理(并不是主从架构),为了减少多个 Manager 管理冲突,引入简单的分布式锁(Lion 内部已运行验证)
- Meta:提供 Lion 侧部分服务注册发现功能;每中心单独部署
- 同步节点(Consistency)上下线时,会由数据中心内的 Meta 节点维护其可用状态,并将中心内最新可用节点列表存储在公共 DB 中
- 不同数据中心的 Meta 节点都可以查看所有数据中心的同步节点(Consistency)列表视图
- API/Console:Lion 管理端 / API 模块,为用户提供配置变更/查询等功能;每中心单独部署
- 每次配置变更都会产生对应的同步日志(Log),用于数据中心间配置同步
- API/Console 请求的流量 + 访问的数据会在中心内实现闭环
2.2.2 数据模型
2.2.2.1 同步日志
Lion 同步日志采用自定义 Log,而非 Binlog。根据同步阶段的不同,我们将 Log 拆分为两种形式:
-
源同步日志(source sync log):包含变更配置的详细信息。配置变更时,在本地数据中心产生一条日志,该日志会被其他数据中心加载,同步。
具体设计
id release_key timestamp key appkey set/swimlane/env old_value new_value 主键 变更唯一标识 变更时间戳 配置 key 配置 appkey 配置其他标识 旧值 新值 同步方向为上海 -> 北京时,北京侧的 Consistency(Writer) 节点上的同步任务会不断从上海侧批量拉取未同步的 SourceSyncLog。
通过 Offset 来标识已同步的 SourceSyncLog(id > offset : 未同步;id <= offset : 已同步)
-
目标同步日志(target sync log):通过回放该日志,将其他数据中心的最新配置更新到本地数据中心(目标同步日志是由源同步日志转化而来的)。
具体设计
id source_idc source_idc_log_id status release_key timestamp key appkey set/swimlane/env old_value new_value 主键 源数据中心标识 源数据中心的 SourceSyncLog Id 同步状态 变更唯一标识 变更时间戳 配置 key 配置 appkey 配置其他标识 旧值 新值 同步方向为上海 -> 北京时,北京侧的同步任务将从上海侧拉取到的 SourceSyncLog 转化成 TargetSyncLog,并插入本地 DB;之后会根据 TargetSyncLog 将上海侧的变更回放到本地。
💡 TargetSyncLog 比 SourceSyncLog 多了 source_idc, source_idc_log_id, status 字段,主要是为了避免数据回环,标识已同步位置等
2.2.2.2 同步任务元数据
数据中心间 Log 传输简单来看就是将其他数据中心的 Log 复制到本侧数据中心,复制过程有几点需要考虑:
- 同步链路控制:应该明确哪些数据中心间可以进行同步,数据是单向同步还是双向同步
- 同步任务扩展性及性能:如果集群中的单个同步节点都同步全量 Log,可能会使得同步性能较低,延迟较大;同时,集群无法水平扩容,扩展性低。我们应该将同步 Log 以切片的形式分配给各个集群节点,每个节点同步部分 Log,从而提高集群的扩展性及同步性能
- 同步稳定性:节点状态经常变化(宕机/重启/扩容/下线),同步任务也随之不太稳定;我们应该保证在同步任务重启/迁移/销毁时,Log 同步尽量不遗漏,不重复
针对上面三点问题,可以通过相应的配置进行管理:
2.2.2.2.1 同步路由配置(IDC Routers)
用于控制不同数据中心间的同步方向
| id | target_idc | source_idc | status | 备注 |
|---|---|---|---|---|
| 主键 | 目标数据中心 | |||
| (当前数据中心) | 源数据中心 | 同步是否开启 | 数据同步方向: | |
| source -> target |
示例:北京 -> 上海
| id | target_idc | source_idc | status |
|---|---|---|---|
| 1 | sh | bj | true |
2.2.2.2.2 同步分区配置(Partitions)
同步节点与同步分区的映射关系
-
同步分区设计参考 Redis Cluster Slot 实现,人为提前设定分区总数,如分区总数 30,分区索引为 [0, 1, 2, 3, 4 … 29]。
每个同步节点负责一部分分区索引集合,如 node_1:[0, 2, 4, 6],node_2:[1, 3, 5]。
在进行 Log 同步时,先对 Log Key 进行 Hash 取模,计算 Log 对应的分区索引,如果该索引值落在同步节点维护的范围内,则由该节点进行同步,否则忽略。
通过这种方式,可以保证同一个 key 的变更会由相同的同步节点进行同步,保证同步顺序
| id | node | source_idc | partition_indexes |
|---|---|---|---|
| 主键 | 同步节点:Consistency(Writer) | 源数据中心 | 同步分区索引列表 |
示例:上海侧同步分区配置
| id | node | source_idc | partition_indexes |
|---|---|---|---|
| 1 | sh_node_1 | bj | [1, 2, 3, 4, 5] |
| 2 | sh_node_2 | bj | [6, 7, 8, 9, 10] |
💡 该配置表示的是本地数据中心同步任务的配置。通常,一个同步节点可能运行多个同步任务,每个同步任务负责同步特定的分区索引 Log。 分区总数提前配置好,且正常情况下保持不变;尽量保证分区索引在同步节点中均匀分配。 同步节点 : 同步任务 = 1 : N (每个同步节点上可能会运行多个同步任务) 同步任务 : 同步分区 = 1 : 1 (每个同步任务只会同步一个分区)
2.2.2.2.3 日志分区偏移量配置(Offsets)
记录每个分区最新同步位置
| id | source_idc | partition_index | offset |
|---|---|---|---|
| 主键 | 源数据中心 | 同步分区索引 | 同步日志偏移量 |
示例:北京分区偏移量配置
| id | source_idc | partition_index | offset |
|---|---|---|---|
| 1 | bj | 1 | 10 |
| 2 | bj | 2 | 4 |
| 3 | bj | 3 | 5 |
| 4 | bj | 4 | 9 |
💡 同步任务增量同步指定分区的部分 Log 之后,更新该分区的偏移量(offset),以便当同步任务重启/迁移后能够从上次同步的位置继续同步。 每个源数据中心下的每个分区都需要维护自身的 Offset。
2.2.3 Manager : 同步任务调度
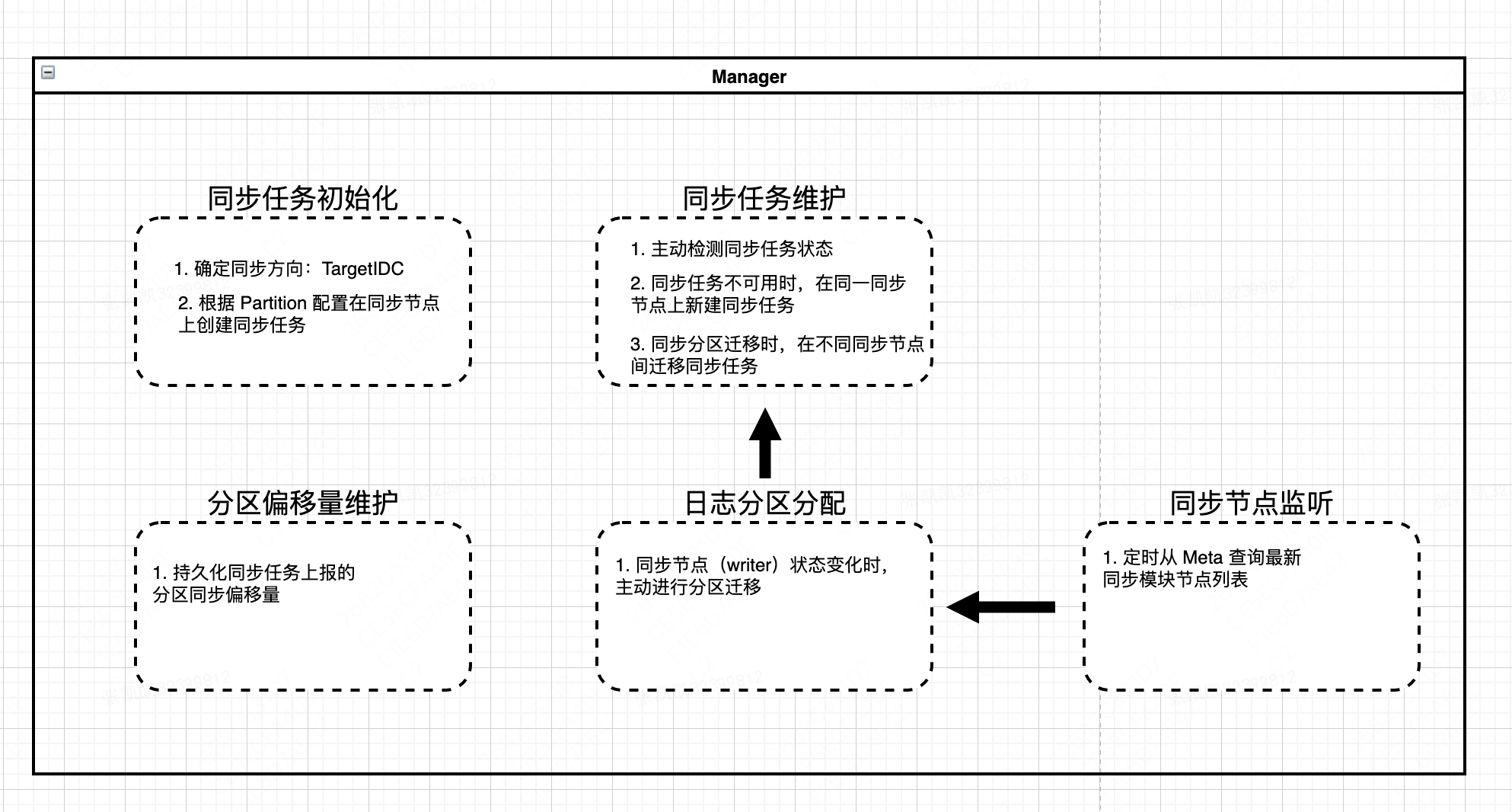
前面提到,为了提高同步任务的扩展性,对同步日志进行了切片处理,每个同步任务只负责一个切片,每个同步节点上可运行多个同步任务。
Manager 作为同步任务管理的核心模块,主要与同数据中心内的同步节点(Consistency)节点进行交互,涉及功能有:
- 初始化同步任务:在新增数据中心,新增同步/集群节点,同步服务启动时,在同步节点(Consistency)上初始化同步任务
- 同步任务维护:主动检测同步节点上各个任务的执行状态;在同步任务不可用时,及时销毁旧任务,创建新任务;当同步分区迁移时,主动在同步节点间迁移同步任务
-
日志分区分配:当同步节点变更时,需要对分区进行分配,保证不同节点间同步负载尽可能均衡(同步分区的变更会触发同步任务的迁移)
系统初始化时,由人工手动进行分区配置
- 同步节点监听:Manager 会定时从 Meta 查询最新的同步节点列表,当发生节点变更时,触发分区重新分配
- 分区偏移量维护:同步任务在完成增量日志同步时,会上报当前分区最新偏移量并持久化,以便后续同步任务重启时能够从最新 Offset 处重新同步
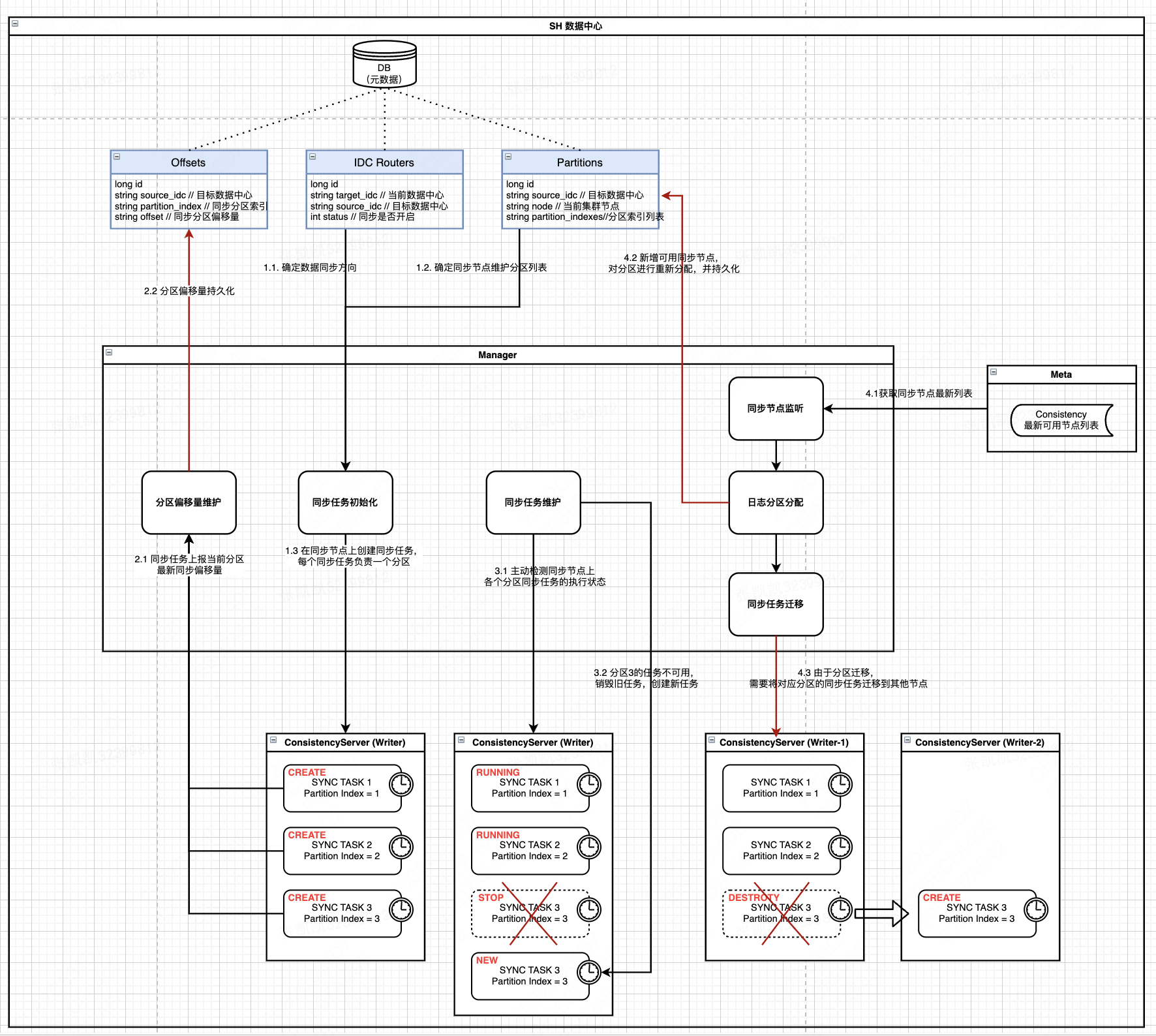
Manager 管理流程细节如下:
- Manager 从 DB 中加载 IDC Routers,Partitions 原数据,用于明确数据同步方向(source->target),同步节点维护的分区列表
- Manager 定时与同步节点通信,获取节点上分区同步任务的执行状态:{partition_index: task_status}
- 如果同步节点维护的分区列表没有对应的同步任务执行,则在该同步节点上初始化对应分区同步任务
- 如果同步节点维护的部分分区任务执行状态异常,则在该同步节点上新建对应分区同步任务,并销毁旧同步任务
- 在同步任务正常执行期间,会上报最新已同步分区日志偏移量至 Manager,并持久化到 Offsets 表中
- Manager 定时从 Meta 查询同步模块最新可用节点列表
- 如果新增/摘除同步节点,则 Manager 会对同步分区进行重新分配,尽量保证分区均匀分配
- 分区重新分配之后,需要对同步任务进行迁移,确保同步节点维护的分区列表与同步任务一一对应
从上面流程我们可以看到:
- Offset 只会由同步任务上报并更新; Offset 与 Partition 绑定
- Partition 配置只在同步节点发生变更的时候才会变更;Partition 与同步节点绑定
💡 Q:数据中心初始化阶段,同步分区如何分配的? A:初始阶段由人工手动为同步节点进行分区分配,并且分区总数需要大于节点数。如同步节点数为 5,分区总数为 30.
Q:多个 Manager 会同时进行任务管理吗? A:会的,同一数据中心内会有多个 Manager 节点进行管理,为了减少冲突,可以更新前使用简单的分布式锁(已在 Lion 当前实现中得到验证).
2.2.4 Consistency : 实时同步数据
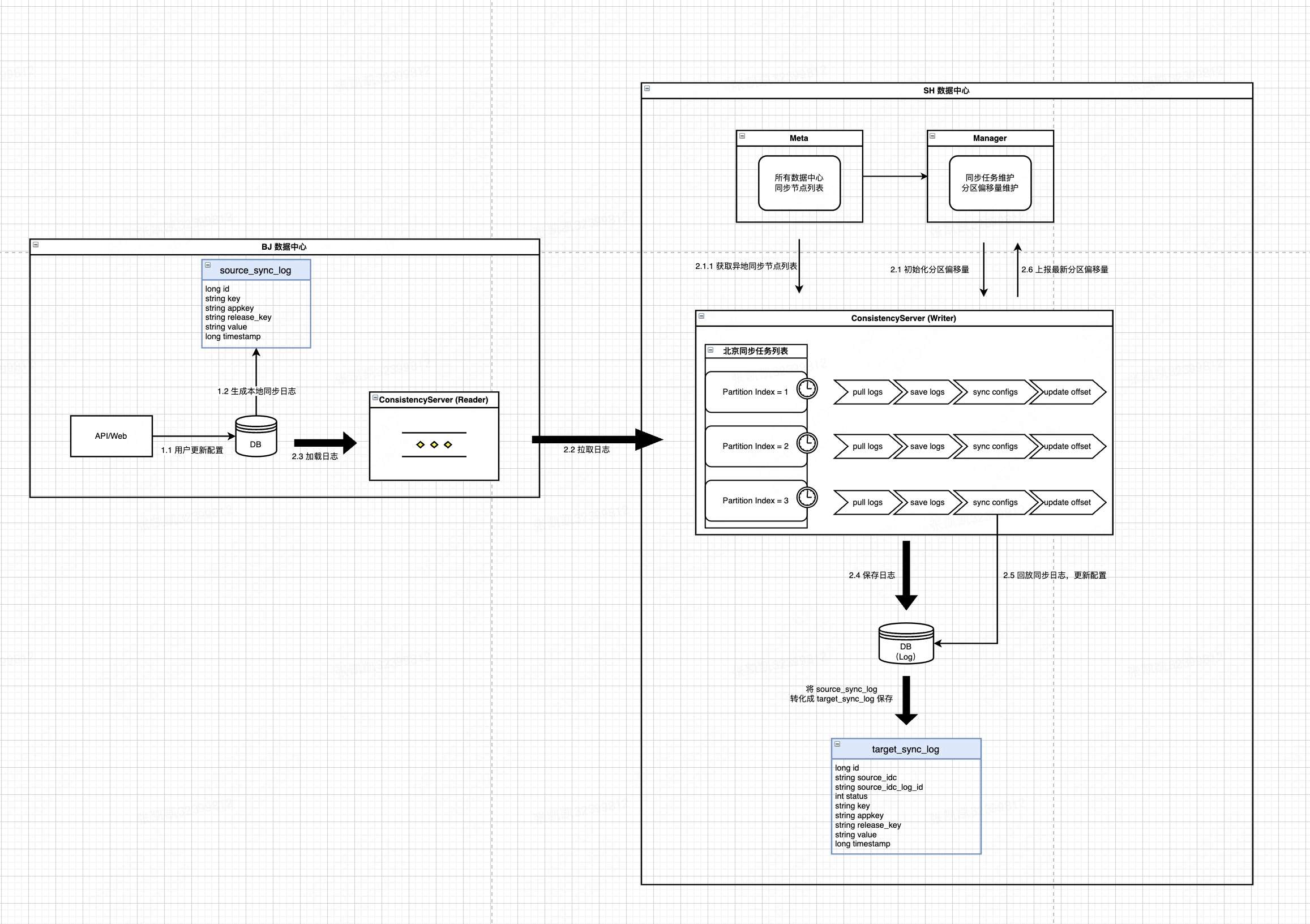
Manager 在同步节点(Consistency)上创建的同步任务用于实现不同数据中心间数据同步功能
- 用户在北京侧变更配置,北京侧 DB 会插入一条 SourceSyncLog,该 Log 包含了配置变更的详细信息
- 上海侧同步任务(Writer)在运行时,会从 Manager 加载对应分区的偏移量,同时从 Meta 获取北京侧 Consistency 最新可用节点列表,用于后续日志拉取
- 同步任务(Writer)随机访问北京侧 Consistency(Reader)节点,根据 Offset 批量加载 SourceSyncLog
- 对北京侧返回的日志进行过滤,过滤出属于当前分区索引的部分日志(对配置 key 取 hash)
- 过滤完成后,同步任务首先将过滤结果日志批量保存在本地 DB(TargetSyncLog)中
- 此时,保存在本地的 TargetSyncLog 的 Status 字段默认为未同步状态
- 随后,同步任务(Writer)将日志依次回放,将北京侧的最新配置同步本地
- 同步成功之后,将 TargetSyncLog 的 Status 字段置为同步成功状态
- 如果同步失败,则应将 Status 字段置为同步失败状态
- 将回放完成的日志 LogId 作为最新分区 Offset 上报给 Manager
- 不管回放成功还是失败,都需要上报 Offset,优先保证不阻塞后续日志同步 => 对于失败的日志,由后续补扫任务继续同步
- 本批次同步完成之后,将以最新的 Offset 进行下一次同步流程
每个同步任务只会同步属于自身分区的日志,正常情况下,不同节点上的不同同步任务不会重复同步同一条日志(即使有少量重复同步也没影响)
💡 Q:日志同步流程是否可以将 Log 持久化到 DB 步骤移除? A:日志回放过程可能会失败,通过将 Log 持久化,并标识状态,可以方便后续重新同步,保证不遗漏
Q:整个流程基本为同步执行,是否会存在性能问题? A:通过设置适当大小的分区(如 256),并考虑代码层面优化(如热点 key 聚合,分区内部再 hash),基本能够满足 Lion 需求
2.2.5 同步集群节点变更与任务迁移
在日常运维中,集群节点变更是经常发生的,如服务发布,宿主机宕机,新增机器等。我们需要保证集群节点变化时,数据同步功能仍稳定执行。针对这类问题,进一步进行讨论。
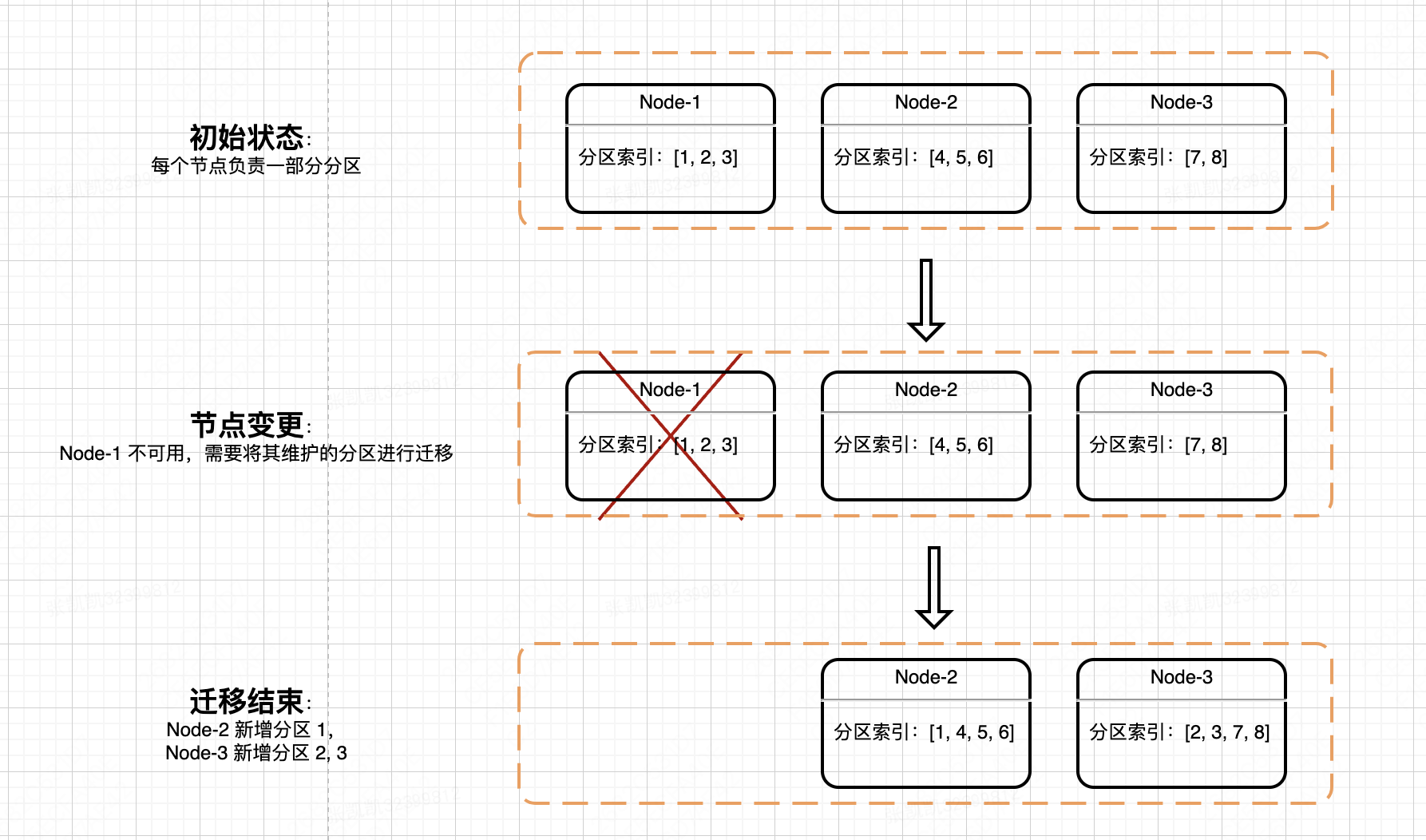
每个节点维护一部分分区,每个分区对应一个同步任务。当其中一个节点不可用时,该节点维护的分区集合就会被迁移到其他节点上,同时在其他节点上创建对应的分区同步任务。
那么,在同步任务迁移(分区迁移)过程中,能否保证同步流程稳定执行?
回看下同步任务的执行步骤,进一步分析:

在日志从异地加载过滤之后,将会持久化到 DB。之后会逐条顺序回放日志,回放完成后上报最新 Offset
| 任务迁移时机 | 直接影响 | 同步稳定性影响 |
|---|---|---|
| Step 1: 日志加载 | 当前批次拉取失败 | 无影响:由于 Offset 未变化,迁移后的新任务会重新从当前位置拉取 |
| Step 2: 日志过滤,保存 | 拉取的日志保存失败 | 无影响:由于 Offset 未变化,迁移后的新任务会重新从当前位置拉取,过滤,保存 |
| Step 3: 逐条回放日志 | 该批次 logId > offset 的日志回放失败 | 少量日志重复同步:该批次 logId > offset 的日志会被新任务重新同步 |
| Step 4: 上报 Offset | 该条回放完成的日志 logId 未上报 | 少量日志重复同步:该批次 logId > offset 的日志会被新任务重新同步 |
可以看出,在同步任务执行阶段的任何时机迁移,最坏的情况是该批次日志被重复同步。而我们的同步流程支持幂等,且日志批次大小可控,因此,对同步流程的稳定性基本没有影响。
2.2.6 补扫任务:重新同步
在 Log 复制并同步到本地流程中,可能会因为 DB 异常/代码逻辑 Bug 等原因导致同步失败,为了不阻塞后续变更同步,在重试一定次数之后,应该放弃。
但是,为了保证配置最终同步成功,应该对同步失败的 Log 进行重新同步。

-
补扫任务定时从 TargetSyncLog 中加载未同步成功(可能是同步失败,也可能是未同步)的日志,同样按照分区进行过滤
为了避免扫描到刚复制过来,但还未同步完成中的日志,补扫任务需要扫描一定时间范围内的日志,如 1 分钟范围外
-
对扫描到的日志进行重新同步,如果成功,则更新 Status 字段为同步成功状态;否则仍放弃,等待下次补扫任务同步
多次补扫同步仍可能失败,因此需要设置一个同步阈值,超过该阈值仍未成功,则触发告警,人工介入排查原因
补扫任务与同步节点是 1 : 1 的关系,即一个同步节点上只有一个补扫任务,并且该补扫任务负责多个日志分区。
假如同步节点负责的分区索引为 [1, 2, 3],那么会有三个实时同步任务,每个实时同步任务分别负责一个分区;但是只有一个补扫任务,同时负责 [1, 2, 3] 分区
2.2.7 一致性检测
实时同步与补扫同步流程能够保证大部分情况下配置一致性(>99.99%),仍有小概率会出现配置不一致的情况。
因此除了实时同步,补扫同步,还需要增加增量一致性检测任务,对于不一致的配置进行再次检测与修复。
理想情况下,增量一致性检测任务执行步骤如下:1. 每个数据中心的同步节点按照 IDC Router 配置,从目标 IDC 中查询指定配置的最新值;2. 将目标 IDC 返回的最新值进行比较(timestamp 比较),如果多个数据中心的配置值不同,则选择最新的配置值作为目标值,并更新本地。
举例,北京侧有个配置 key = lion-test.demo,北京侧同步节点查询 lion-test.demo 在上海/怀来/香港侧的最新值,如果这几个数据中心的值都不同,则以最新值为主,将其更新本地
考虑到已知需要支撑的数据中心有北京/上海/怀来/香港,如果按照上面执行步骤,那么检测链路为 4*3,每两个数据中心间都需要进行一次比较,对于不一致冲突情况处理比较复杂。后续如果需要再新增数据中心,冲突处理情况将会更加复杂,不利于维护。
现在 Lion 已经有北京/上海两个数据中心,上海侧的变更请求只有北京侧的一半,大部分变更触发源都在北京,即大部分数据同步方向为:北京 -> 上海。
因此,为了简化不一致冲突处理,我们人为给数据中心设置优先级:北京 > 怀来 > 上海 > 香港。北京数据中心作为主数据中心,其他数据中心以北京侧为主进行增量一致性检测。
但是,如果其他数据中心的数据比北京要新,则需要反哺北京,更新北京侧数据。
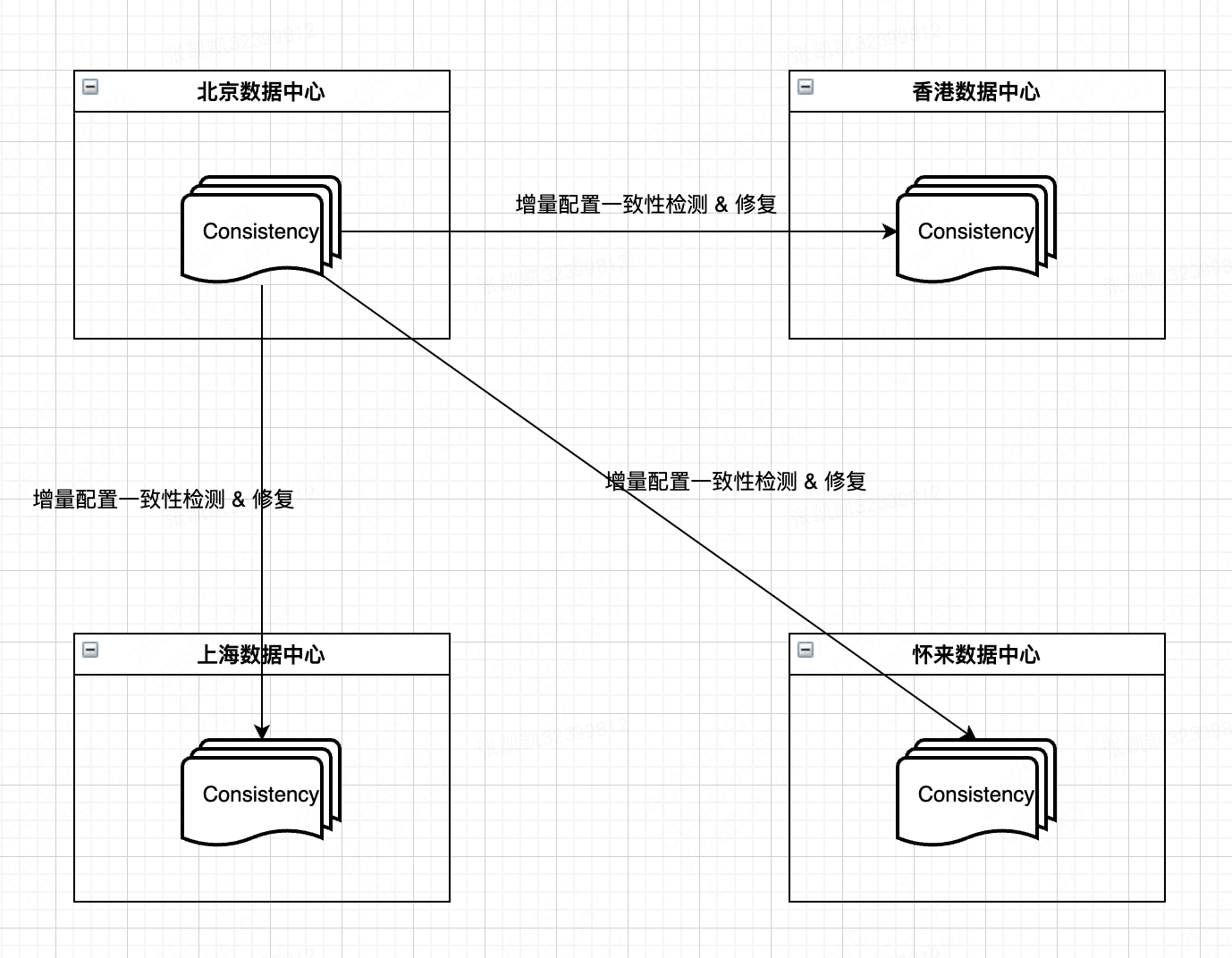
以上海数据中心增量检测为例,基本流程如下:
- 上海侧 Consistency 增量一致性检测任务查询本地指定时间范围内配置变更列表
- 通过 HTTP 请求查询北京侧对应配置的最新值,并进行比较时间戳
- 反哺:如果上海 Timestamp > 北京 Timestamp,则回调北京,在北京侧插入一条 TargetSyncLog,等待后续补扫任务重新同步
- 修复:如果上海 Timestamp <= 北京 Timestamp,则在上海侧插入一条 TargetSyncLog,等待后续补扫任务重新同步,完成修复
💡 Q:为什么日志同步时未对数据中心进行优先级划分,简化同步流程呢? A:如果日志同步也按照这种方式处理,那么优先级低的数据中心的变更就不会同步到其他数据中心,不能满足多数据中心一致性的目标。 从 Lion 现状来看,经过实时同步,补扫同步之后,北上数据一致性的比例 > 99.99%。而增量一致性检测是对实时同步,补扫同步的兜底处理,对一些极少数配置不一致的情况进行检测修复。
Q:为什么只考虑增量一致性检测,不考虑全量检测? A:全量一致性检测成本太高,且从 Lion 现状来看,实时同步 & 补扫同步 & 增量一致性检测能够满足 Lion 对数据一致性要求。
2.2.8 数据同步可用性保障
2.2.8.1 冲突解决
每次配置变更都会记录变更时间戳(timestamp),默认冲突解决为比较时间戳进行覆盖。
如果时间戳相同,则根据 IDC 优先级进行覆盖:BJ > HL > SH > HK。
2.2.8.2 一致性保证
- 同步日志持久化到本地 DB,同步失败后会进行多次重试(实时同步与补扫同步均会重试)
- 每批次从其他数据中心成功复制日志之后,会持久化最新分区 Log 偏移量。即使节点重启,或者分区迁移,都能保证从上次同步位置重新同步
- 根据同步日志同步变更的配置流程是幂等的,支持重复同步
- 增量一致性检测任务进行兜底检测
2.2.8.3 数据回环解决
同步日志在复制传输时,只会从目标 IDC 的 SourceSyncLog 表中查询,并保存在本地的 TargetSyncLog 表中,而根据 TargetSyncLog 执行数据同步的过程不会产生新的 SourceSyncLog,避免了数据回环的条件。即 异地配置变更 -> SourceSyncLog -> TargetSyncLog -> 本地配置。
2.3 上线方案
2.3.1 前期准备
- BJ,SH 侧创建同步元数据表:IDC Router, Partitions, Offsets;同步日志表:SourceSyncLog, TargetSyncLog
- BJ,SH 侧配置同步相关元数据
- BJ,SH 侧添加同步开关配置,用于新旧版本数据同步方案切换(默认关闭,使用旧方式进行同步)
2.3.2 上线步骤
- BJ,SH 服务发布:Manager, Consistency, Meta;此时配置变更会插入 Log 至 SourceSyncLog,但不通过该日志进行同步
- 开启 SH 侧同步开关:此时 BJ -> SH 采取新方案同步,SH -> BJ 仍采用旧方案同步
- 记录下时间戳 T1,用于异常修复
- 观察监控:
- 同步流程正确性,同步日志堆积情况,同步延迟,北上数据一致性,增量一致性检测任务是否正常执行等
- 通过全链路监控查看配置变更推送是否正常
- 同时,观察 SH 侧 Offsets 是否持续增长
- 手动调整 SH 侧 Consistency 节点状态,观察 Partitions 是否正常调整,同步任务是否正常迁移,同步延迟/堆积是否符合预期
- 开启 BJ 侧同步开关:此时 BJ <-> SH 双向同步均采用新方案
- 记录下当前时间戳 T2,用于异常修复
- 持续观察 SH,BJ 侧同步监控
2.3.3 回滚步骤
- 关闭 SH,BJ 侧同步开关:切回旧同步方案
-
调整 SH 侧增量一致性检测时间戳为 T1,BJ 侧时间戳调整为 T2
prefix = lion.instance.last.check.timestamp
- 持续观察监控:北上数据一致性,变更推送延迟等
2.4 非功能性设计
- 同步任务执行状态监控
- 同步分区变更周知
- 数据不一致告警
- 同步延迟监控,告警
- 同步堆积告警
- 多次同步失败告警
3、项目风险点
- 同步任务的管理
- 能否准确判断同步任务的执行状态
- Manager 能否准确完成同步任务的迁移,能否及时 Kill 不可用任务并新建任务
- 在 Manager 管理不符合预期的情况下,需要人为介入,手动执行任务的删除与创建
- Offset 上报时机
- 每回放一条 Log 就上报 Offset 可以保证可靠性,但是性能会有所损耗
- 是否可以调整 Offset 上报时机,如周期上报,这样可以提高部分性能,但是在任务迁移时可能会有 Log 重复同步,需要进行权衡
- 同步一致性保证
- 在新方案上线期间,如果数据不一致概率较高,需要及时切换旧方案
- 新方案在北上数据中心得到验证,并且长时间运行一段时间后,才能推广到多数据中心
4、FAQ
Q:Writer 任务调度管理比较复杂,如果只有一个 Writer 任务同步全量数据,是否可行?
A:如果只有一个 Writer 任务进行同步,那么 Writer 同步性能需要尽可能高,最低要支持 2000QPS。
- 按照当前的同步逻辑,单个同步任务肯定无法支撑:单条日志顺序同步耗时 TP999 48.4ms
- 优化单条日志顺序同步 -> 批量同步:简单测试了下,性能大概提升 20% 左右,不太能满足要求(可能仍存在优化空间;单批次日志数量不能过多,可能会引发大事务)
我们将同步任务进行切片处理,除了性能因素,还有服务扩展性考虑。
- 随着业务配置增加,数据中心逐步建设,同步任务要支持水平扩展以保证 SLA
- 同步任务调度管理虽然比较复杂,但是部分逻辑(如分区迁移)已经经过线上验证,其稳定性及扩展性能够得到保障
因此,我们仍倾向继续采用任务切片的形式。
Q:能否灵活调整数据中心同步方向?如将香港 -> 北京的同步链路切断,或者香港侧数据中心不与其他数据中心同步
A:通过更新 IDC Router 配置即可调整数据中心间的同步方向(source_idc -> target_idc)
- 更新 IDC Router 的 status 字段可以调整同步方向开启与否
- 新增 IDC Router 记录可以新增同步链路
Q:能否支持 Appkey 粒度同步方向控制?如 lion-demo 项目只可以从北京同步到上海
A:可以支持。不过只按照前面的描述还不能满足,需要额外的配置,如每个数据中心新增一个表 IDCFilter,在该表中配置哪些 IDC 中的 Appkey, Key 不需要进行同步。
在同步任务进行日志过滤时直接忽略对应的 IDC, Appkey, Key 即可实现。
Q:能够支持部分业务同步流程隔离?如数据库相关配置与普通业务配置同步隔离
A:可以支持;将特定范围的分区(如 1000 ~ 1024)单独划分出来给指定业务使用。
在分区索引计算时进行设计,保证指定的 Appkey 列表只会路由到特定的分区,而其他业务 Appkey 路由到其他分区。
Q:Lion 短期内仍不能完全下掉 Redis,对 Redis 同步如何处理?
A:同步任务在回放日志时,先同步 DB,之后再同步 Redis。现有监控来看,Redis 数据同步耗时 TP999 71.3ms,平均 4.2ms,对同步延迟影响有限,可以直接同步。
等 Redis 完全下掉之后,在通过开关移除 Redis 同步流程。
Q:目前针对北上两个数据中心,Lion 文件配置在更新时会将文件内容同时更新到北上两个 S3 集群,在同步时只同步文件 SHA Key。如果扩展到多个集群,针对文件配置如何处理?
A:对于文件配置,在同步 SHA Key 后,通过单独的线程,从源数据中心 S3 集群进行文件加载,同步到本地 S3 集群。
如果从源数据中心的 S3 集群加载失败,则按照顺序(BJ > HL > SH > HK)降级进行重新拉取。
5、其他补充
- https://km.sankuai.com/page/28131829#id-%E6%9E%B6%E6%9E%84%E4%BB%8B%E7%BB%8D
- https://km.sankuai.com/page/600429548
- https://dbaplus.cn/news-11-1399-1.html
- https://km.sankuai.com/collabpage/1407987923
- https://km.sankuai.com/page/1476581664
- https://km.sankuai.com/page/617657890
- https://km.sankuai.com/collabpage/1532367225