Raft: An Understandable Consensus Algorithm
概述
Raft 是一种为了管理复制日志的一致性算法(一致性算法允许一组机器像一个整体一样工作,从而能够提供线性一致性,即使其中一些机器出现故障也能够继续工作下去),能够实现与 Paxos 类似的功能,但是实现与理解起来更为简单。
相对于其他一致性算法来说,有一些独特的特性:
- 强领导者:和其他一致性算法相比,Raft 使用一种更强的领导能力形式。比如,日志条目只从领导者发送给其他的服务器。这种方式简化了对复制日志的管理并且使得 Raft 算法更加易于理解。
- 领导选举:Raft 算法使用一个随机计时器来选举领导者,通过随机计时器能够有效减少选举过程中的冲突。
- 成员关系调整:Raft 使用一种共同一致的方法来处理集群成员变换的问题,在这种方法下,处于调整过程中的两种不同的配置集群中大多数机器会有重叠,这就使得集群在成员变换的时候依然可以继续工作。
Raft 基础
节点状态
Raft 的节点有三种状态:Leader, Follower, Candidate。在通常情况下,系统中只有一个 Leader 并且其他的节点全部都是 Follower。Follower 都是被动的:他们不会发送任何请求,只是简单的响应来自 Leader 或者 Candidate 的请求。Leader 处理所有的客户端请求(如果一个客户端和 Follower 联系,那么 Follower 会把请求重定向给 Leader )。
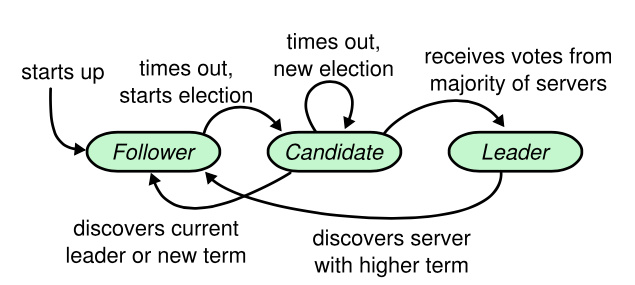
各个状态之间的转化如图:
- 初始状态下,所有的节点都是 Follower 状态,并且随机选择一个选举超时时间
- 当选举超时时间内没有收到 Leader 的心跳或者附加日志的请求,则认为当前集群中不存在 Leader,则将自己的身份从 Follower 转换为 Candidate ,并发起选举,选举的结果可能有三种
- 在选举超时后,仍然没有 Leader 被选出,则再次开始选举(这种情况一般是选票被瓜分了,不过由于采取的是随机选举超时,那么出现选票瓜分的情况比较少)
- 自己收到了大多数选票,赢得了选举,则切换身份为 Leader
- 其他节点赢得了选举或者接收到来自新的领导人的附加日志 RPC,转变成跟随者,则切换自己的身份为 Follower,并从 Leader 中复制日志
- Leader 节点会一直认为自己是 Leader 直到自己宕机了,不过在通信过程中,如果发现有更高任期的节点,则会将自己的身份转换为 Follower
任期
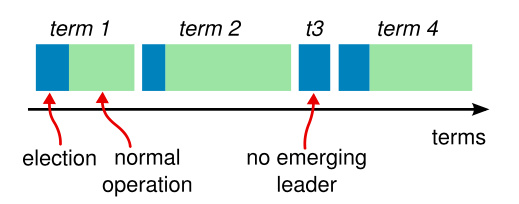
Raft 把时间分割成任意长度的任期,任期用连续的整数标记。任期在 Raft 算法中充当逻辑时钟的作用,在整个时间内单调递增,这会允许服务器节点查明一些过期的信息比如失效的 Leader。任期在 Raft 算法中起着重要的作用;每一个节点存储当前任期号 currentTerm,当节点收到 RPC 通信请求时就会进行比较,做出相关判断
- 追加日志请求中,如果 Leader 的任期小于 currentTerm,则拒绝接收该日志
- 请求投票请求中,如果 Candidate 的任期小于 currentTerm,则拒绝给 Candidate 投票
- 不管是接收到的请求还是响应,如果任期号T > currentTerm,那么就令 currentTerm 等于 T,并切换状态为跟随者
- 在选举投票前,Candidate 会增加自己的 currentTerm
- 在日志比对中,term 号更大的日志更新(类似于 lamport 时间戳)
详解
领导人选举
在 Raft 节点的状态转换中,通过选举来确定 Leader & Follower 的身份。
Raft 使用一种心跳机制来触发领导人选举,当集群刚启动或者 Leader 宕机之后,Follower 在选举超时时间内没有收到相关心跳,就会认为没有可用的 Leader,则触发选举流程。
发起选举
要开始选举,Follower 需要使自己的 term + 1,并切换身份到 Candidate;之后会并发地向集群中的其他节点发送请求投票的 RPC 请求征集选票,同时会给自己投票(将 voteFor 更新为自己的 id)。该次选举会维持到以下事件发生:
- 该节点赢得了这次选举,成为 Leader
- 其他节点赢得了这次选举,那么该节点就切换成 Follower 身份
- 一段时间后,没有任何节点赢得选举
Corner Case
存在一些 corner case,如果已经选出了 Leader,并且 Leader 能够正常工作,但是另一个 Candidate 有更高的 term,这样很有可能让 Leader 变成 Follower,或者让 Follower 给这个更高 Term 的 Candidate 重新投票。
为了解决这样的问题,可以考虑 Pre-Vote,也就是一个 Follower 如果要开始投票,它并不会立刻变成 Candidate,给自己 term + 1,而是会先变成 Pre-Candidate 的状态,用当前的 term 去问其他的节点能否给自己投票,如果收到了大多数的同意消息,那么才会变成 Candidate 继续后面的选举流程。
另外,也可以考虑 Check Quorum,当一个 Follower 收到了更高的 Term 选举消息,如果它确信当前集群还在正在工作,也就是在 election timeout 的时间里面仍然收到了 Leader 的消息,那么这个 Follower 会直接丢掉这个消息。
选举投票
投票请求请求与相应的参数:
VoteRequest {
term; // 候选人的任期号
candidateId; // 请求选票的候选人的 Id
lastLogIndex; // 候选人的最后日志条目的索引值
lastLogTerm; // 候选人最后日志条目的任期号
}
VoteResponse {
term; // 当前任期号;如果比 Candidate 大,则用于更新 Candidate
voteGranted; // 候选人赢得了此张选票时为真
}
对于收到投票请求的节点来说,需要做出如下决定:
- 如果请求中的 term < currentTerm,则拒绝给其投票
- 如果请求中的 term > currentTerm,则令 currentTerm 等于 term,并切换状态为 Follower
- 如果 votedFor 为空或者为 candidateId,并且候选人的日志至少和自己一样新,那么就投票给它
针对投票,Raft 还有一些选举限制:一个候选人能够赢得选选票除非这个候选人包含了所有已经提交的日志条目。
结合 Raft 的限制来看,一个 Candidate 如果想要赢得选票,需要满足两个条件:
- Candidate 的 term 必须要大于投票者的 term
- Candidate lastLogEntry 必须不能落后于投票者的 lastLogEntry:如果两份日志最后的条目的任期号不同,那么任期号大的日志更新;如果两份日志最后的条目任期号相同,那么日志比较长的那个就更新。
Corner Case
关于最新日志比较,考虑这样一种情况。A,B,C 三个节点中,A 为 Leader,其他两个节点为 Follower,并且当前 term = 10,logIndex = 19。
A 之后被网络隔离,但是其仍然认为自己是 Leader,仍在接收客户端的请求,假如又收到一个请求,那么 A 的最新日志为 term = 10, logIndex = 20。B,C由于与 A 行程网络隔离,从而发起选举,B 被选为 Leader 并处理请求,如果 B 处理了一个请求,此时其最新日志为 term = 11, logIndex =20。
之后网络恢复,A 给 B,C 投票,此时 A 的 term 可能已经变成 12 了;但是 A 的最后 log 不正确,其 term = 10,因此 B,C 需要拒绝 A。
选举终止
当一个 Candidate 从整个集群的大多数服务器节点获得了针对同一个任期号的选票,那么它就赢得了这次选举并成为 Leader。每一个服务器最多会对一个任期号投出一张选票,按照先来先服务的原则。要求大多数选票的规则确保了最多只会有一个 Candidate 赢得此次选举。一旦 Candidate 赢得选举,它就立即成为领导人。然后会向其他的服务器发送心跳消息来建立自己的权威并且阻止新的 Leader 的产生。
选举过程中可能会遇到选票被瓜分的情况,导致没有 Leader 被选出,从而被迫进入下一次选举。为了减少这种情况,Raft 采用了随机选举超时的方案:每个节点的选举超时时间都不同,从而大多数时候只有一个节点超时,然后该超时的节点赢得选举(其 term 比其他节点都大,并且日志不落后)。
日志复制
相关参数
LogAppendRequest{
term; // 领导者的任期
leaderId; // 领导者ID 因此跟随者可以对客户端进行重定向
prevLogIndex; // 紧邻新日志条目之前的那个日志条目的索引
preLogTerm; // 紧邻新日志条目之前的那个日志条目的任期
entries[]; // 需要被保存的日志条目(被当做心跳使用是 则日志条目内容为空;为了提高效率可能一次性发送多个)
leaderCommit; // 领导者的已知已提交的最高的日志条目的索引
}
LogAppendResponse{
term; // 当前任期,对于领导者而言 它会更新自己的任期
success; // 结果为真:如果跟随者所含有的条目和prevLogIndex以及prevLogTerm匹配上了
}
如果 leaderCommit 大于 Follower commitIndex,则把 Follower 的 commitIndex 置为 leaderCommit;同时对于之前的日志依次提交到状态机中
复制流程
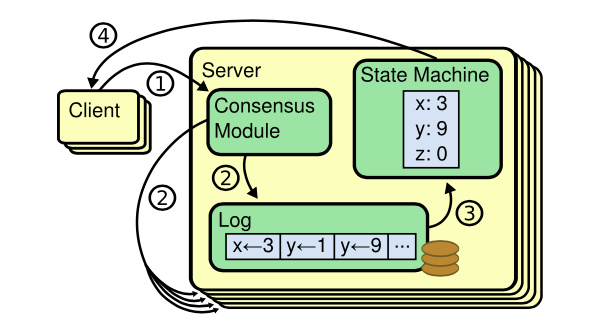
Leader 选举出来之后就会为客户端提供服务:
- 客户端的每一个请求都包含一条被复制状态机执行的指令。
- Leader 把这条指令作为一条新的日志条目附加到日志中去,然后并行的发起附加条目 RPCs 给其他的服务器,让他们复制这条日志条目。
- 当这条日志条目被安全的复制,Leader 会应用这条日志条目到它的状态机中然后把执行的结果返回给客户端。
- 如果 Follower 崩溃或者运行缓慢,再或者网络丢包,领导人会不断的重复尝试附加日志条目 RPCs (尽管已经回复了客户端)直到所有的 Follower 都最终存储了所有的日志条目。
在一个集群中,各个节点的日志情况可能如下所示:
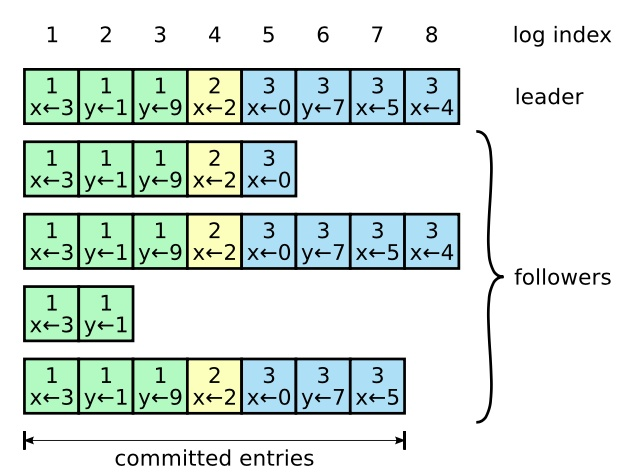
每一个日志条目存储一条状态机指令和从领导人收到这条指令时的任期号,日志中的任期号用来检查是否出现不一致的情况。
在 Leader 将创建的日志条目复制到大多数的服务器上的时候,日志条目就会被提交;而已提交的状态是安全的,Raft 算法保证所有已提交的日志条目都是持久化的并且最终会被所有可用的状态机执行。
Raft 中还有一个安全性限制,从而使得之前领导人创建的日志也会被应用到状态机(之前的日志可能是已提交,也可能只是复制到其他节点但是未完成提交)。
同时,Leader 跟踪了最大的将会被提交的日志项的索引,并且索引值会被包含在未来的所有附加日志 RPCs (包括心跳包),这样其他的服务器才能最终知道领导人的提交位置。一旦跟随者知道一条日志条目已经被提交,那么他也会将这个日志条目应用到本地的状态机中(按照日志的顺序)。
日志匹配 & 冲突解决
Raft 的日志匹配特性:
- 如果在不同的日志中的两个条目拥有相同的索引和任期号,那么他们存储了相同的指令。
- 如果在不同的日志中的两个条目拥有相同的索引和任期号,那么他们之前的所有日志条目也全部相同。
关于第二条特性是由附加日志 RPC 进行一致性检查实现的:在发送附加日志 RPC 的时候,会把新的日志条目紧接着之前的条目的索引位置和任期号包含在里面。如果匹配成功,则一致性检查通过;如果 Follower 在它的日志中找不到包含相同索引位置和任期号的条目,那么 Follower 就会拒绝接收新的日志条目,此时 Leader 与 Follower 的日志就会产生冲突。
造成这种冲突的原因是之前的 Leader 崩溃,但是没有完全复制日志,使得部分 Follower 可能拥有与新的 Leader 不同的日志;可能的情况如下:
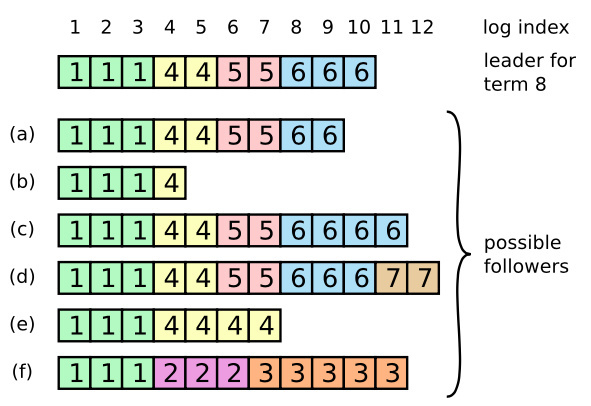
在 Raft 算法中,Leader 处理不一致是通过强制跟随者直接复制自己的日志来解决了,这意味着在跟随者中的冲突的日志条目会被领导人的日志覆盖。要使得 Follower 的日志重新与 Leader 保持一致的状态,Leader 必须找到最后两者达成一致的地方,然后删除从那个点之后的所有日志条目,发送自己的日志给 Follower。
- Leader 刚被选举成功后,会初始化所有的 nextIndex 为自己 lastLogEntryIndex + 1(Leader 维护了 nextIndex:表示下一个需要发送给 Follower 的日志条目的索引地址)
- Leader 发送附加日志进行一致性检查
- Follower 一致性检查失败并拒绝附加日志请求
- Leader 收到拒绝之后,减小该 Follower 的 nextIndex 进行重试,直到找到与其日志保持一致的位置
- 多次重试之后,附加日志返回成功,此时会把 Follower 的日志删除并重新加上 Leader 的日志(Leader 的日志只能附加不能删除,但是 Follower 的日志可以删除)
安全性
Raft 保证了以下几条安全性:
- 选举安全特性:对于一个给定的任期号,最多只会有一个领导人被选举出来
- 领导人只附加原则:领导人绝对不会删除或者覆盖自己的日志,只会增加
- 日志匹配原则:如果两个日志在相同的索引位置的日志条目的任期号相同,那么我们就认为这个日志从头到这个索引位置之间全部完全相同
- 领导人完全特性:如果某个日志条目在某个任期号中已经被提交,那么这个条目必然出现在更大任期号的所有领导人中
- 状态机安全特性:如果一个领导人已经将给定的索引值位置的日志条目应用到状态机中,那么其他任何的服务器在这个索引位置不会应用一个不同的日志
为了保证以上安全性,Raft 存在一些限制:
选举限制
Candidate 必须包含了所有已经提交的 logEntries 才能赢得选举。
这一点分为两个角度看:
- Candidate 想要赢得选举,需要赢得大多数的选票;而要想赢得选票,需要其日志比投票人新
- 前任 Leader 的已提交日志需要复制到大多数节点上
所以,能够赢得选举的 Candidate 一定包含了所有已经提交的日志;不过其在最后已提交的日志后可能包含还未提交的日志(前任 Leader 复制到该节点但是未提交)。
所以在 Leader 选举中,不仅仅要看 term,还需要看日志信息:
投票人会拒绝掉那些日志没有自己新的投票请求。
Raft 通过比较两份日志中最后一条日志条目的索引值和任期号定义谁的日志比较新。如果两份日志最后的条目的任期号不同,那么任期号大的日志更新;如果两份日志最后的条目任期号相同,那么日志比较长的那个就更新。
提交之前任期内的日志条目
Raft 不会通过计算副本数目的方式去提交一个之前任期内的日志条目。
当前任期内,如果 Leader 将日志复制到大多数节点上,那么 Leader 就知道该日志可以被提交了;但是当前任期内的 Leader 不能断定前任 Leader 复制到大多数节点的日志就一定已经提交了。
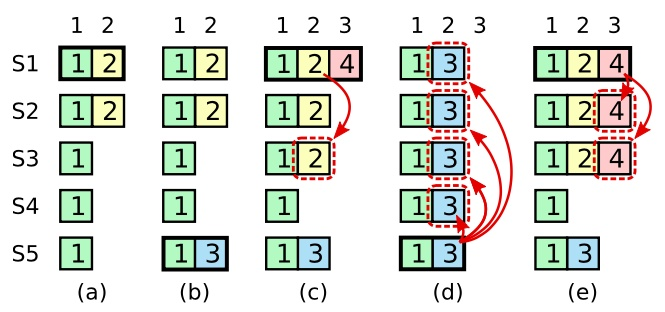
- 在 (a) 中,S1 是 Leader,部分的复制了索引位置 2 的日志条目。
- 在 (b) 中,S1 崩溃了,然后 S5 在任期 3 里通过 S3、S4 和自己的选票赢得选举,然后从客户端接收了一条不一样的日志条目放在了索引 2 处。
- 到了 (c),S5 又崩溃了;S1 重新启动,选举成功,开始复制日志。在这时,来自任期 2 的那条日志已经被复制到了集群中的大多数机器上,但是还没有被提交。
- 如果 S1 在 (d) 中又崩溃了,S5 可以重新被选举成功(通过来自 S2,S3 和 S4 的选票:term = 5, 并且最后一条日志够新),然后覆盖了他们在索引 2 处的日志。
- 反之,如果在崩溃之前,S1 把自己主导的新任期里产生的日志条目复制到了大多数机器上,就如 (e) 中那样,那么在后面任期里面这些新的日志条目就会被提交(因为 S5 就不可能选举成功:最后一条日志不够新)。 这样在同一时刻就同时保证了,之前的所有老的日志条目就会被提交。
如果通过计算副本数目的方式去提交一个之前任期内的日志条目,那么就很可能会出现已经提交的日志被覆盖的情况(index = 2 的日志被重新覆盖了)。只有 Leader 当前任期里的日志条目通过计算副本数目可以被提交;一旦当前任期的日志条目以这种方式被提交,那么由于日志匹配特性,之前的日志条目也都会被间接的提交(按照 e 的情况,假如 s3 被选为 Leader,那么 2,4 位置的日志都会被重新提交)。
对当前 Leader来说,commitIndex 增加,使得前任的日志都应用到状态机中;同时日志一致性检查会促进 Follower 将日志保持同步并应用到自己的状态机中。
集群成员变化
当集群中需要新增节点或者删除节点,意味着集群配置发生了变更。如果直接将各个节点的集群配置从旧配置切换到新配置是不安全的,因为每个节点的配置切换可能发生在任何时候,那么就可能存在一个时间点使得两个不同的领导人在同一个任期内选举成功;其中一个是通过旧的集群配置,另一个是通过新的集群配置。
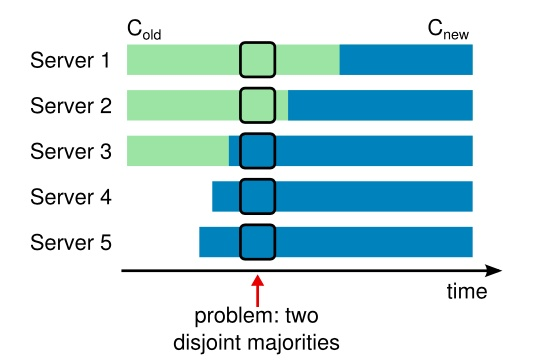
为了保证安全性,Raft 采用的是两阶段方法:集群先切换到一个过渡的配置,称为共同一致;一旦共同一致已经被提交了,那么系统就切换到新的配置上。共同一致是老配置和新配置的结合:
- 日志条目被复制给集群中新、老配置的所有服务器。
- 新、旧配置的服务器都可以成为领导人。
- 达成一致(针对选举和提交)需要分别在两种配置上获得大多数的支持。
共同一致允许独立的服务器在不影响安全性的前提下,在不同的时间进行配置转换过程。此外,共同一致可以让集群在配置转换的过程中依然响应客户端的请求。
关于集群配置,存在一条规则:一旦一个服务器将新的配置日志条目增加到它的日志中,它就会用这个配置来做出未来所有的决定(服务器总是使用最新的配置,无论他是否已经被提交)。
那么成员变化时,整个切换流程如下:
-
Leader 收到新的集群配置请求 C-new
-
Leader 为了共同一致存储配置 C-old,new,并将其添加到本地日志中,同时复制给集群中的节点(此时需要成功
复制到 C-old,new 中大多数节点,才能提交
)。在此期间,如果 Leader 收到了客户端的请求,那么也需要将日志复制到 C-old,new 中的大部分节点才能提交
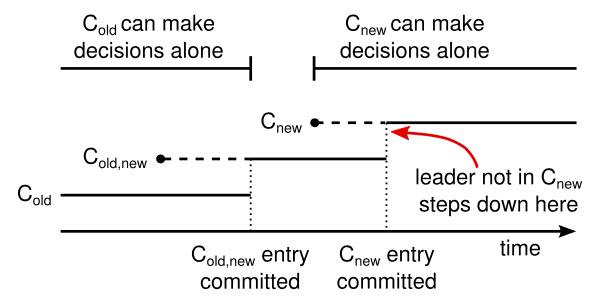
- 如果 C-old,new 还没提交,但是此时 Leader 崩溃了,被选出来的新 Leader 可能是使用 C-old 配置也可能是 C-old,new 配置,这取决于赢得选举的候选人是否已经接收到了 C-old,new 配置。在任何情况下, C-new 配置在这一时期都不会单方面的做出决定。
- 如果 C-old,new 被成功提交了,那么即使 Leader 崩溃了,只有拥有 C-old,new 的节点才能成为新的 Leader(Leader 完全特性)
-
Leader 创建新的集群配置 C-new,并添加到自己的本地日志中,同时将日志复制给 Follower(此时
只需要 C-new 中大多数节点同意即可
,后续都采用新的配置)。在此期间,如果 Leader 收到了客户端的请求,只需要将日志复制到 C-new 的大多数节点即可提交
- 如果 C-new 还没提交但是 Leader 崩溃了,那么新 Leader 可能使用 C-new,也可能使用 C-old,new 作为配置
- 如果 C-new 提交后 Leader 崩溃了,那么新 Leader 只能使用 C-old,new 作为新配置
-
如果 Follower 发现自己不在 C-new 中,则会主动退出
- 如果当前 Leader 不是 C-new 中的一员,则在 C-new 配置提交后退出
使用两阶段过渡的方式,C-old 与 C-new 不会同时做出单方面的决定,保证了安全性。
线性化语义支持
线性化语义支持
客户端交互
Raft 中的客户端发送所有请求给 Leader。
当客户端启动的时候,会随机挑选一个服务器进行通信。如果客户端第一次挑选的服务器不是Leader,那么那个服务器会拒绝客户端的请求并且提供他最近接收到的 Leader 的信息(附加条目请求包含了领导人的网络地址)。如果 Leader 已经崩溃了,那么客户端的请求就会超时;客户端之后会再次重试随机挑选服务器的过程。
写线性化
Raft 是可以执行同一条命令多次的:例如,Leader 在提交了这条日志之后,但是在响应客户端之前崩溃了,那么客户端会和新的领导人重试这条指令,导致这条命令就被再次执行了。解决方案就是客户端对于每一条指令都赋予一个唯一的序列号。然后,状态机跟踪每条指令最新的序列号和相应的响应。如果接收到一条指令,它的序列号已经被执行了,那么就立即返回结果,而不重新执行指令。
读线性化
为了防止前任 Leader 崩溃导致读取了脏数据,需要一些额外的措施。
-
Leader 必须有关于被提交日志的最新信息
Leader 完全特性保证了 Leader 一定拥有所有已经被提交的日志条目,但是在其任期开始的时候,可能不知道哪些是已经被提交的。为了知道这些信息,Leader 需要在任期里提交一条日志条目。
Raft 中通过领导人在任期开始的时候提交一个空白的没有任何操作的日志条目到日志中去来实现。该动作会使得前任 Leader 的 log 全部被提交,同时会间接促进 Follower 提交之前的日志并与 Leader 保持一致。
-
领导人在处理只读的请求之前必须检查自己是否已经被废黜了
Raft 中通过让 Leader 在响应只读请求之前,先和集群中的大多数节点交换一次心跳信息来处理这个问题。